OpenAI DALL·E 3來了,集成ChatGPT,生圖效果太炸了
機器之心報導
機器之心編輯部
集成 ChatGPT 後,DALL・E 3 對上下文的理解上了一個大台階。
終於,OpenAI 的文生圖 AI 工具 DALL-E 系列迎來了最新版本 DALL・E 3,而上個版本 DALL・E 2 還是在去年 4 月推出的。
OpenAI 表示,「DALL・E 3 比以往系統更能理解細微差別和細節,讓用戶更加輕鬆地將自己的想法轉化為非常準確的圖像。」

是不是真如 OpenAI 所說的那樣呢?眼見為實,我們來看以下 DALL・E 3 與 DALL・E 2 的生成效果比較,同樣的 prompt「一幅描繪籃球運動員入樽的油畫,並伴以爆炸的星雲」,左圖 DALL・E 2 在細節、清晰度、明亮度等方面顯然遜於右圖 DALL・E 3。

除了炸裂的生圖效果之外,此次 DALL・E 3 的最大特點是與 ChatGPT 的集成,它原生構建在 ChatGPT 之上,用 ChatGPT 來創建、拓展和優化 prompt。這樣一來,用戶無需在 prompt 上花費太多時間。
具體來講,通過使用 ChatGPT,用戶不必絞盡腦汁地想出詳細的 prompt 來引導 DALL・E 3 了。當輸入一個想法時,ChatGPT 會自動為 DALL・E 3 生成量身定製的、詳細的 prompt。同時用戶也可以使用自己的 prompt。
至於集成 ChatGPT 後的效果怎麼樣?OpenAI CEO 山姆・奧特曼興奮地展示了 DALL・E 3 的連續性生成結果,簡直稱得上完整的「故事片」。

超級向日葵刺蝟長什麼樣子
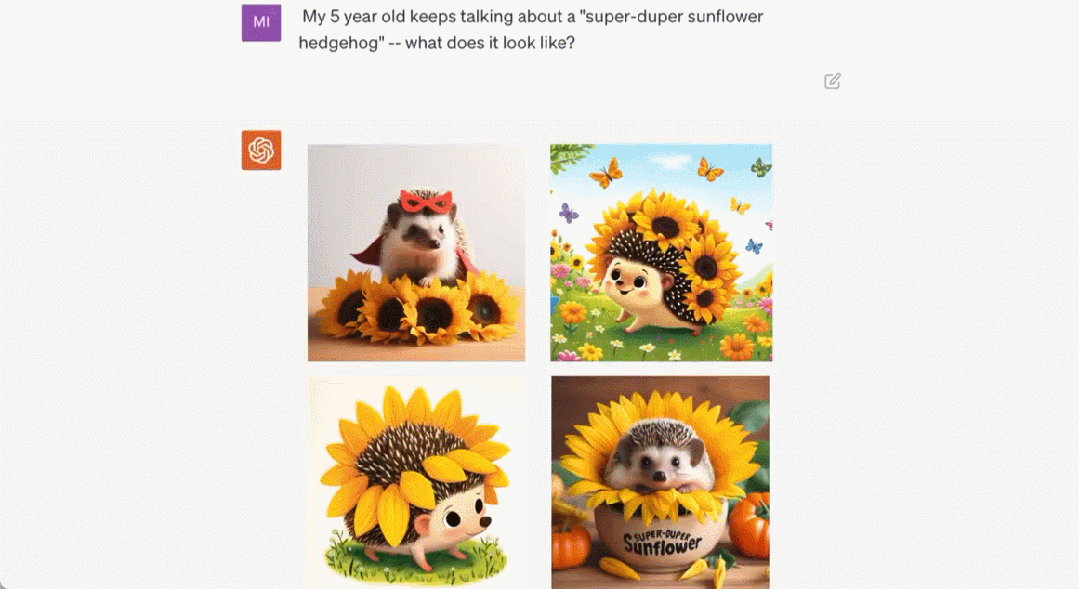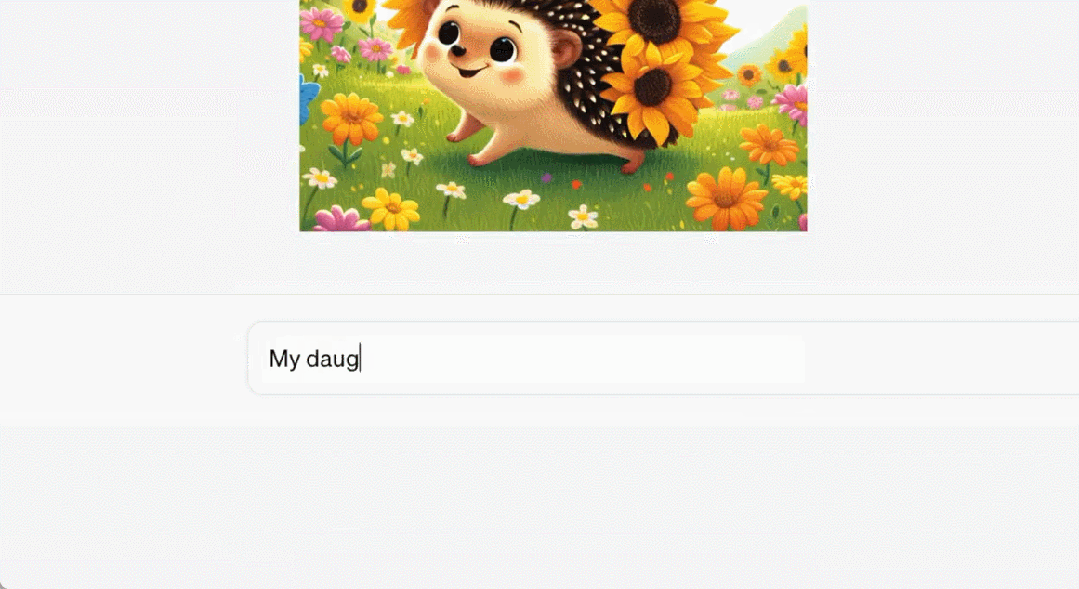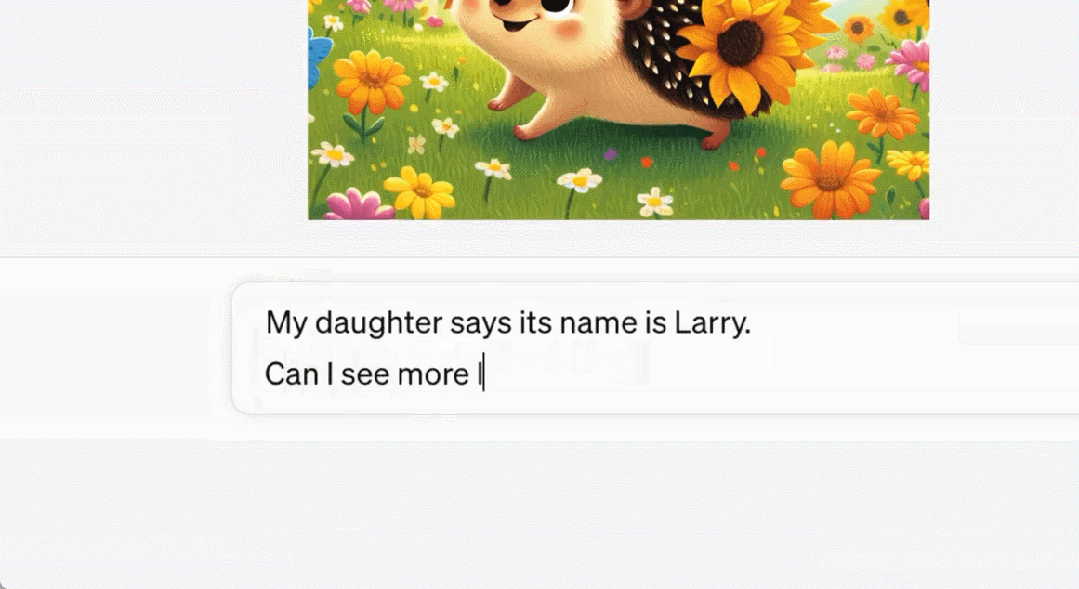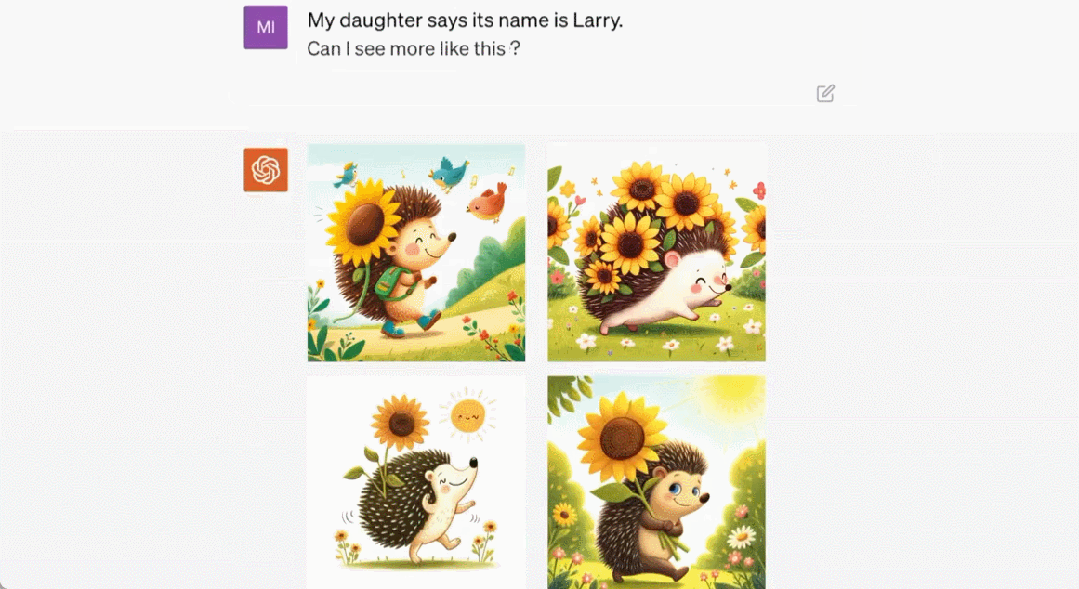
這隻刺蝟叫「Larry」以及它的更多同類。
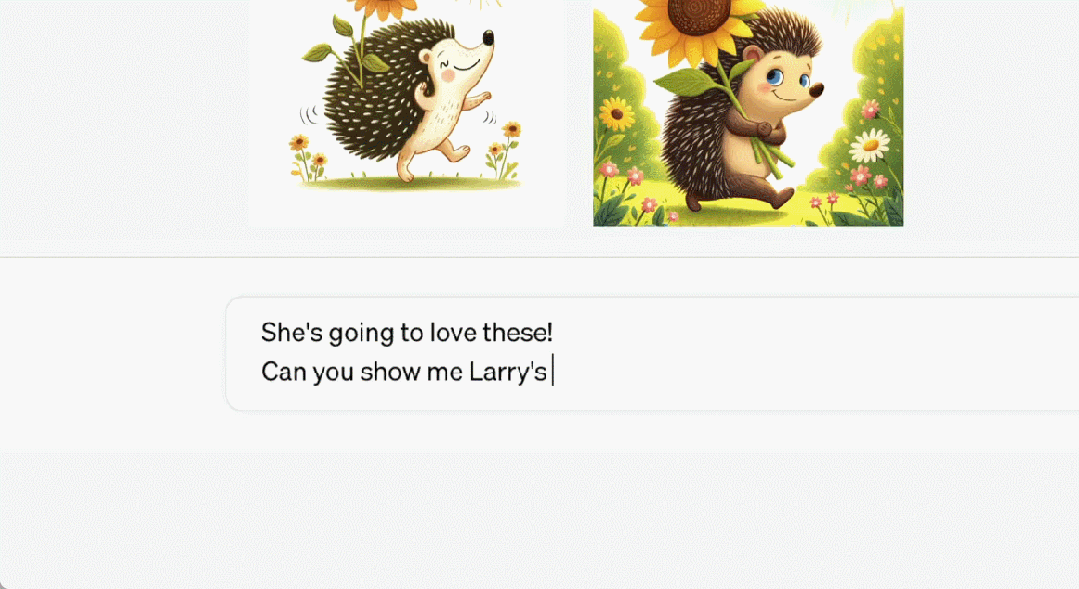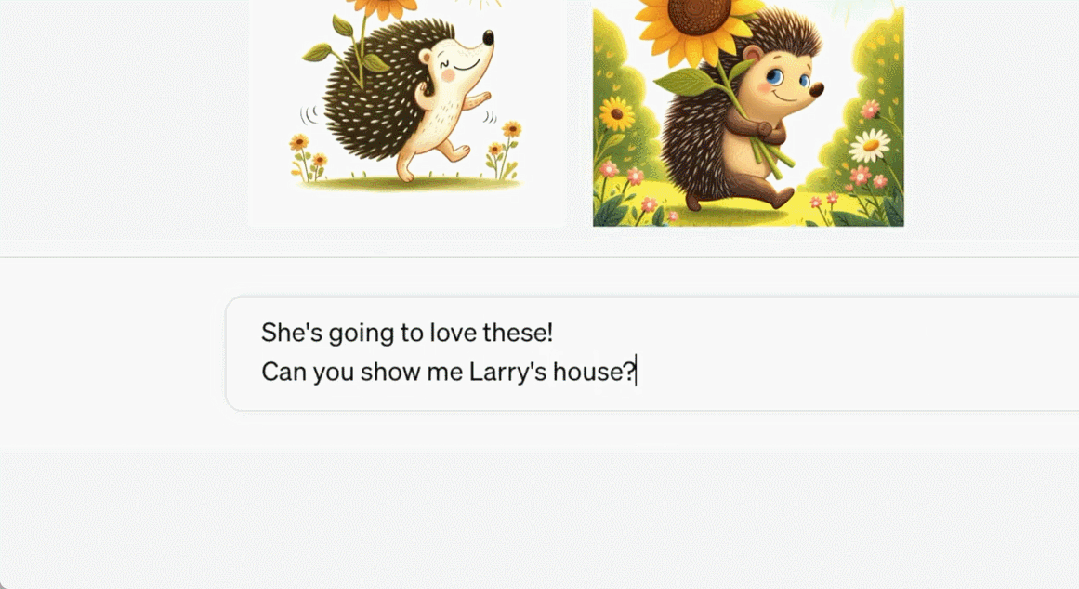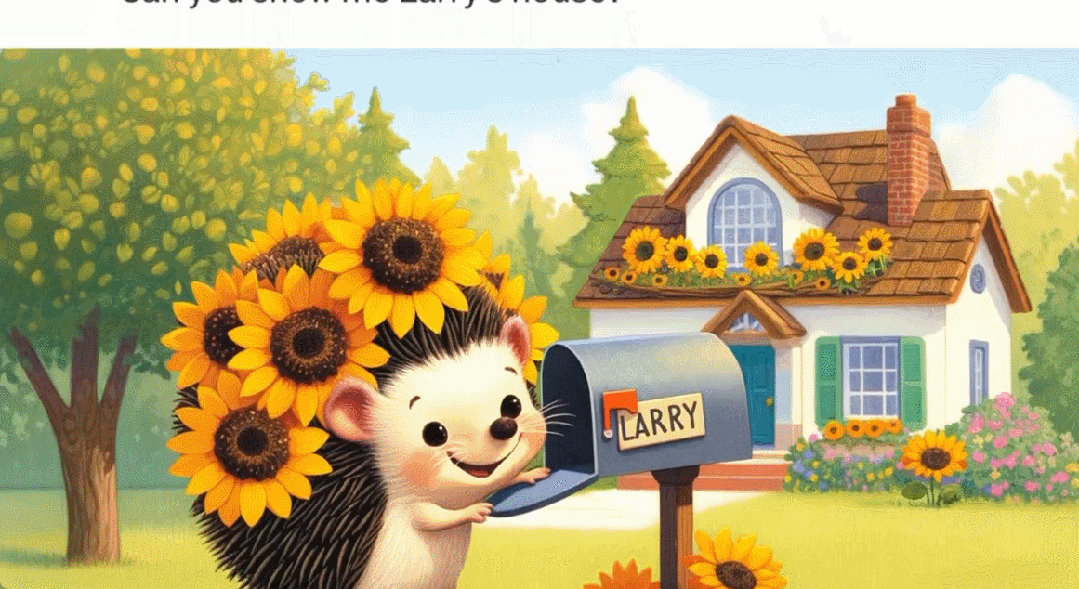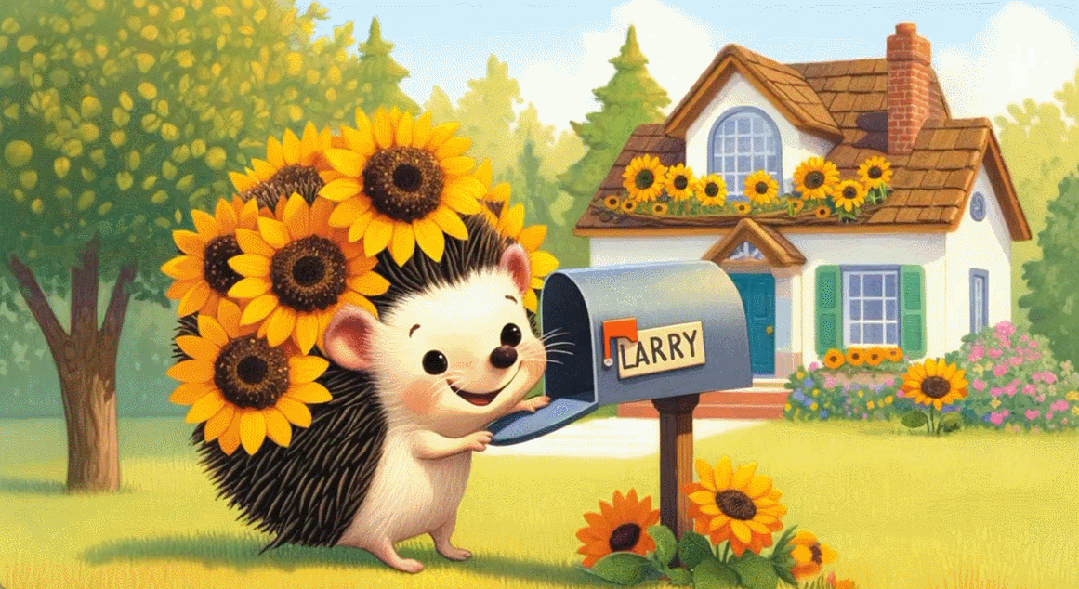
Larry 的家長這樣。
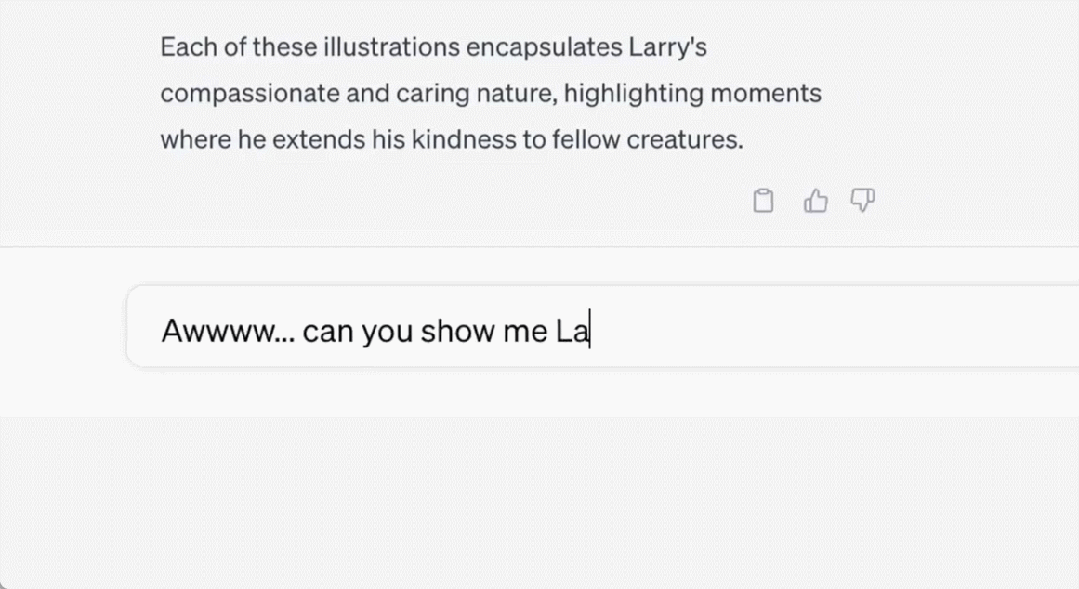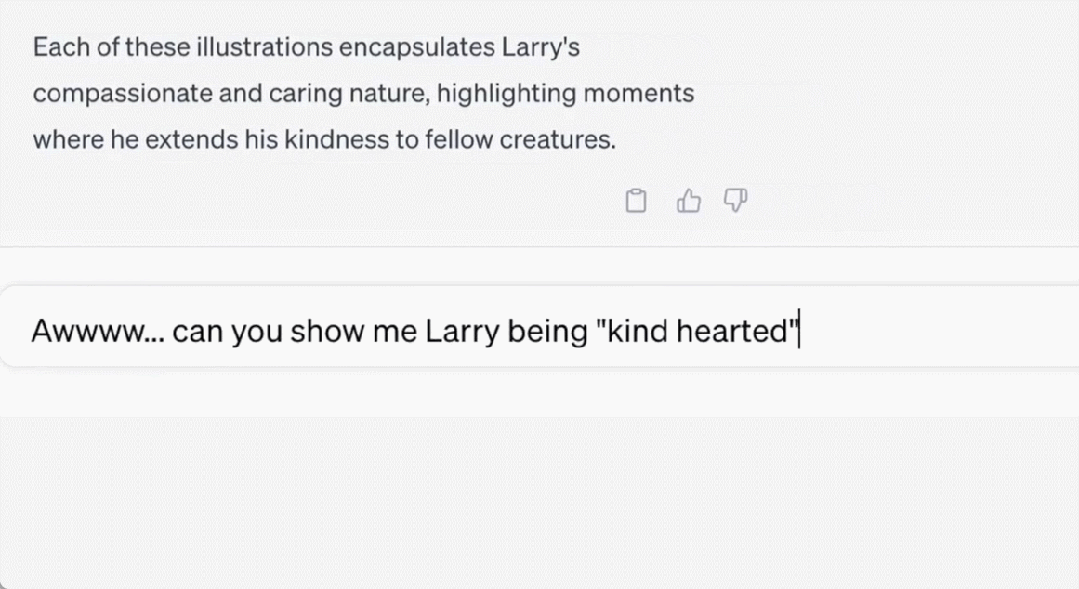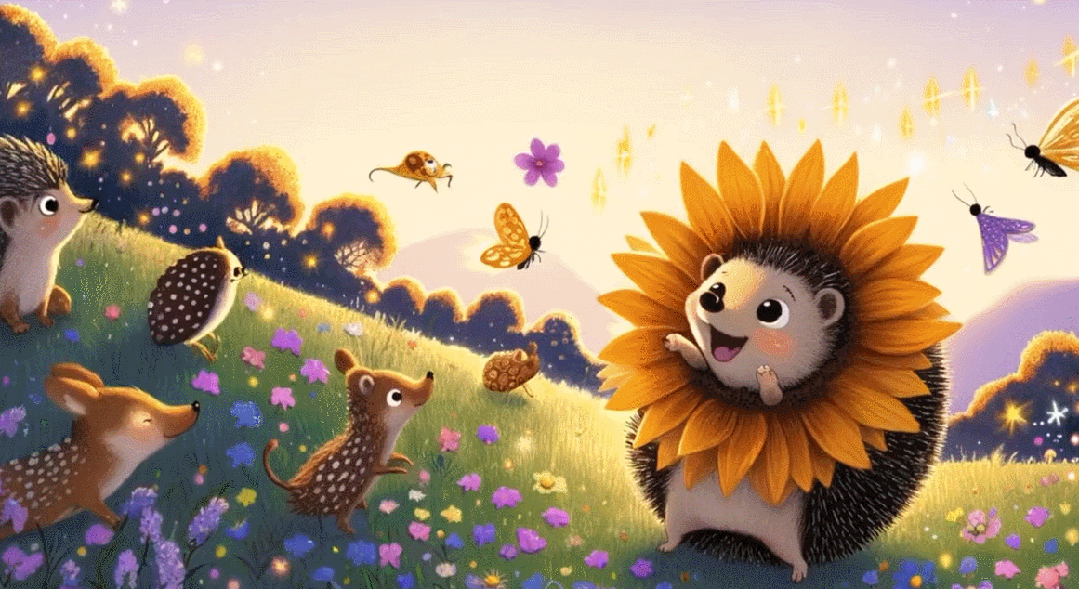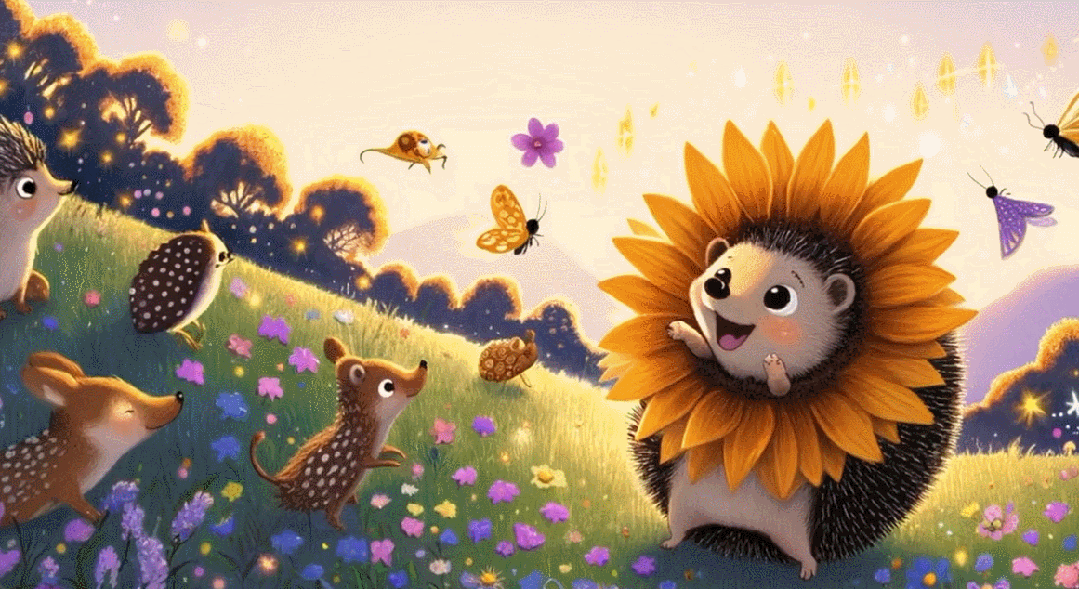
Larry 很善良。
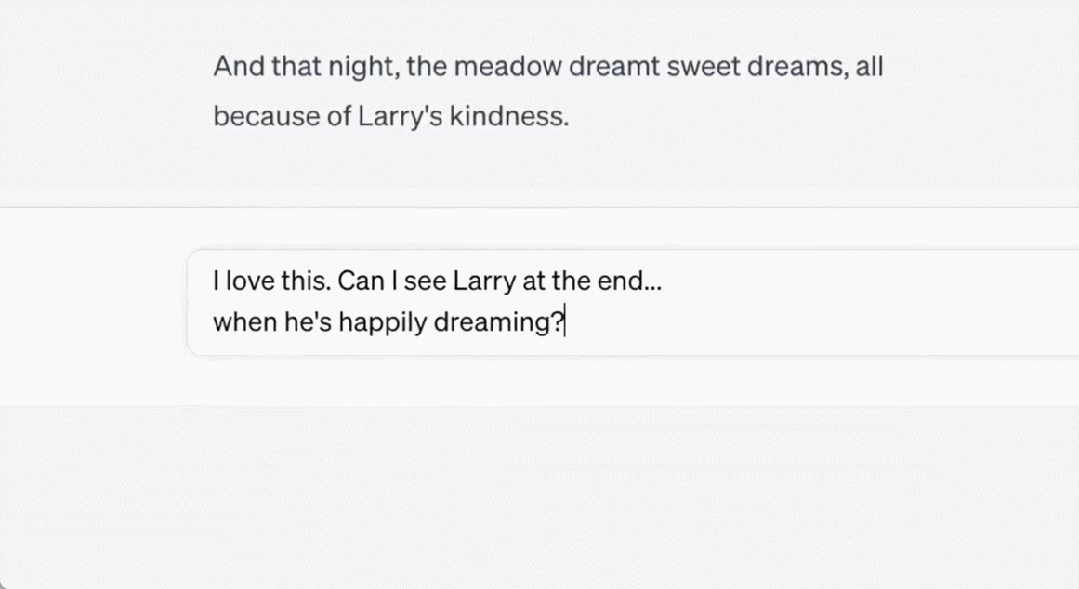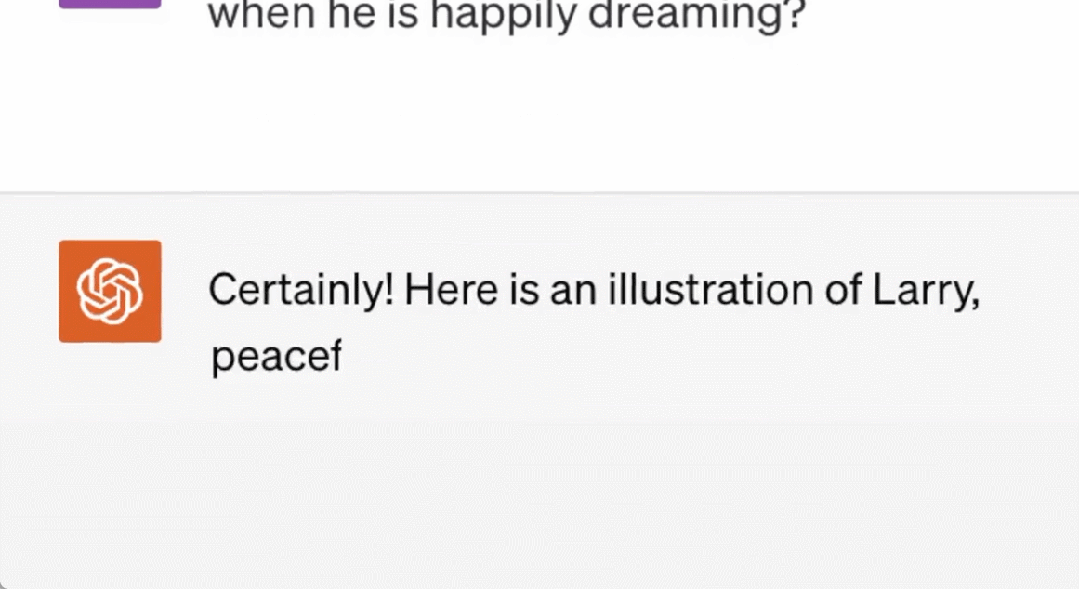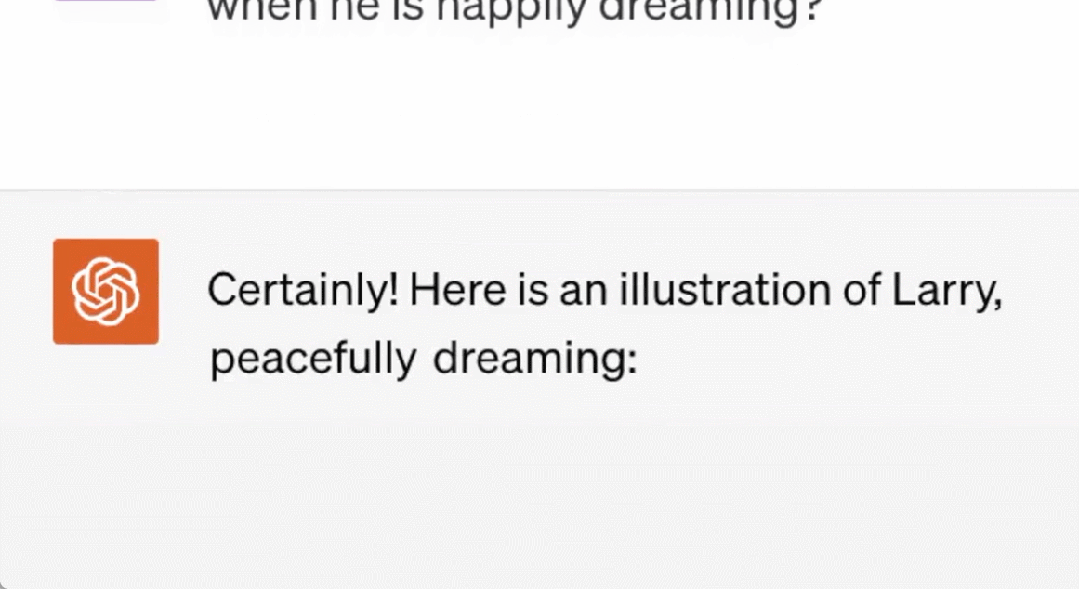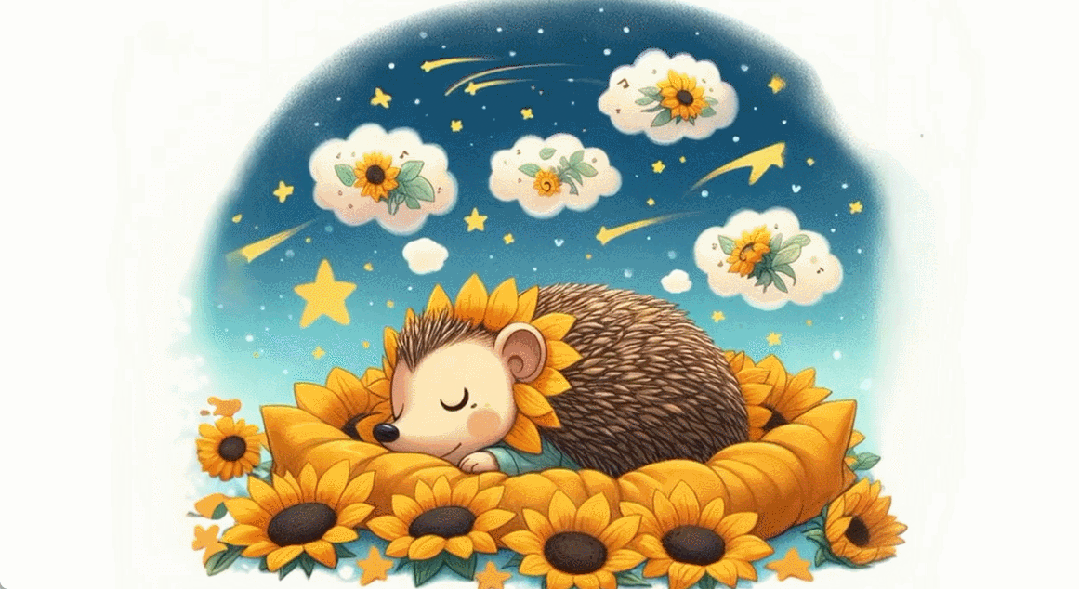
Larry 最後安然入眠了。
ChatGPT 集成並不是 DALL・E 3 唯一的新特點,它還能生成更高質量的圖像,更準確地反映提示內容。DALL・E 將文本 prompt 轉換成圖像。即使是 DALL・E 2 ,也會經常忽略特定的措辭導致出錯。但 OpenAI 的研究人員說,最新版本能更好地理解上下文,並且處理較長的 prompt 效果會更好。此外,它還能更好地處理向來困擾圖像生成模型的內容,如文本和人手。

prompt:這幅插畫描繪了一顆由半透明玻璃製成的人心,矗立在驚濤駭浪中的基座上。一縷陽光穿透雲層,照亮了心臟,揭示了其中的小宇宙。地平線上鐫刻著一行醒目的大字 「Find the universe within you」。
可以看到在上圖將 prompt 中的每一個細節都表現出來了。半透明的質感、畫面底部的波濤洶湧、陽光與厚厚的雲層、心臟中的宇宙景象,以及難倒很多圖像生成模型的文字展現,DALL・E 3 都順利地完成了這些任務。
那麼,DALL・E 3 能不能成為 Midjourney 「殺手」呢?Twitter用戶 @MattGarciaEth 已經將二者生成的圖片進行了很多比較。大家覺得哪個更好呢?

prompt 為「一個鱷梨坐在治療師的椅子上,說『我只是覺得內心很空虛』,中間有一個坑大小的洞。治療師、一個笠射、潦草地寫筆記。」

prompt 為「這幅插畫描繪了一顆由半透明玻璃製成的人心,矗立在驚濤駭浪中的基座上。一縷陽光穿透雲層,照亮了心臟,揭示了其中的小宇宙。地平線上鐫刻著一行醒目的大字 『Find the universe within you』」

prompt 為「一位亞裔中年婦女的黑髮上散落著銀絲,顯得支離破碎,錯綜複雜地鑲嵌在一片碎瓷片中。瓷器上閃爍著飛濺的顏料圖案,光澤和啞光的藍色、綠色、橙色和紅色和諧地交織在一起,在動與靜的超現實並置中捕捉著她的舞姿。她的膚色與瓷器一樣呈淺色,為她的造型增添了一種神秘的氣質。」(Twitter @nickfloats,上圖為 DALL・E 3 的生成結果, 下圖為 Midjourney 的生成結果)
目前,DALL・E 3 處於研究預覽版本。OpenAI 計劃將 DALL・E 3 的發佈時間錯開, 將於 10 月份首先向 ChatGPT Plus 和 ChatGPT Enterprise 用戶發佈,隨後在秋季向研究實驗室及其 API 服務發佈。不過,該公司沒有透露何時或者是否計劃發佈免費的公開版本。
DALL・E 系列研究
我們簡單為大家梳理介紹下 OpenAI 文本生成圖像的 DALL・E 系列研究,也方便讀者們了 DALL・E 系列背後的技術。
2021 年 1 月 6 日,OpenAI 博客發佈了兩個連接文本與圖像的神經網絡:DALL・E 和 CLIP。DALL・E 可以基於文本直接生成圖像,CLIP 則能夠完成圖像與文本類別的匹配。這兩項研究的發佈,引起了社區極大的關注。
據博客介紹,DALL・E 可以將以自然語言形式表達的大量概念轉換為恰當的圖像,可以說是 GPT-3 的 120 億參數版本,可基於文本描述生成圖像。

DALL・E 示例。給出一句話「牛油果形狀的椅子」,就可以獲得綠油油、形態各異的牛油果椅子圖像。
2 個月後,DALL・E 的論文和代碼公開。

項目地址:https://github.com/openai/DALL-E 論文地址:https://arxiv.org/abs/2102.12092
2022 年 4 月 7 日左右,DALL・E 迎來了升級版本 ——DALL・E 2。與 DALL・E 相比,DALL・E 2 在生成用戶描述的圖像時具有更高的解像度和更低的延遲。並且,新版本還增添了一些新的功能,比如對原始圖像進行編輯。
OpenAI 還公佈了 DALL・E 2 的研究論文《Hierarchical Text-Conditional Image Generation with CLIP Latents》。

論文地址:https://cdn.openai.com/papers/dall-e-2.pdf
遺憾的是。OpenAI 可能不會像之前一樣,公佈 DALL・E 3 背後的技術細節。
注重安全與版權問題
OpenAI 稱其在 DALL・E 3 上投入了大量工作,包括製定強有力的安全措施,以防止創建「有害」的圖像。OpenAI 表示其與外部「紅隊」成員(一個故意試圖破壞系統以測試系統安全性的團隊)合作,並依賴輸入分類器(一種教語言模型忽略某些單詞以避免顯式或暴力 prompt 的方法)。DALL・E 3 也無法生成公眾人物的圖像。
OpenAI 研究員 Sandhini Agarwal 表示她對 DALL・E 3 的安全措施「高度有信心」,並表示該模型在不斷改進。OpenAI 還在一封電子郵件中表示:DALL・E 3 拒絕生成在世藝術家風格的圖像,這一點與 DALL・E 2 不同。
藝術家們曾起訴 DALL・E 的競爭對手 Stability AI 和 Midjourney,以及藝術網站 DeviantArt,指控它們使用他們擁有版權的作品來訓練文本到圖像的模型。或許是為了避免訴訟,OpenAI 將允許藝術家將其藝術作品從未來版本的文本到圖像 AI 模型中刪除,不用於訓練。創作者可以提交一張他們擁有版權的圖片,並在網站上填寫表格要求將其移除。
這樣,未來版本的 DALL・E 就可以屏蔽與藝術家的圖像和風格相似的結果。
參考鏈接:
https://openai.com/dall-e-3
https://www.theverge.com/2023/9/20/23881241/openai-dalle-third-version-generative-ai
OpenAI unveils DALL-E 3, allows artists to opt out of training



















