大模型時代結束?大佬齊預測:AI模型或需先縮小規模,才能再次擴大規模

新智元報導
編輯:耳朵
【新智元導讀】小模型強勢來襲,「大模型時代」或將落幕?
「小模型周」過去了 ,小模型的最新戰場才剛剛開闢。
上週GPT-4o mini和Mistral NeMo二連發,「麻雀雖小,五臟俱全」的小模型成為業界大佬密切關注的新方向。

這麼說來,難道大模型要失寵了? Scaling Law要失效了?
前OpenAI和特斯拉AI研究員Andrej Karpathy剛剛入局AI教育,「K老師」最近發表推文指導行業迷津,揭秘科技巨頭紛紛轉向小模型研發的背後新趨勢:AI大模型的競爭即將逆轉。
他預判,未來的模型將會更小,但仍然會變得更智能。
人工智能巨頭公司和一些新晉獨角獸,最近都發佈了與其他同行相比更緊湊、更強大、更實惠的人工智能模型,最新的例子是OpenAI的GPT-4o mini。
Karpathy預測這一趨勢將持續下去。他寫道,「我敢打賭,我們會看到很多能夠有效可靠思考的模型,而且體積非常小。」
小模型:站在巨人的肩膀上
在LLM發展的初期階段,吞吐更多數據,把模型往大了做是必然的趨勢。這主要基於以下幾個原因:
首先,數據驅動的需求。
生活在一個數據爆炸的時代,大量豐富和多樣化的數據需要更強大的模型來處理和理解。
大模型具備容納和處理海量數據的能力,通過大規模的數據訓練,能夠挖掘出深層次的模式和規律。
其次,計算能力的提升。
硬件技術的不斷進步,GPU等高性能計算設備的發展,為大模型的訓練提供了強大的算力支持。使得訓練大型、複雜的模型成為可能。
再者,追求更高的性能和精度。
大模型通常能夠在語言理解、生成、圖像識別等多個領域展現出卓越的性能,懂的越多,生成出來的結果也就越準確。
最後,泛化能力更強。
大模型能夠更好地處理未曾見過的新問題和新任務,能夠基於之前學到的知識進行合理的推測和回答,具有更強的泛化能力。
再加上AI領域競爭激烈,各研究機構和巨頭都致力於開發更大更強的模型,展示技術實力和領先地位,卷模型大小自然成了LLM的發展大方向。
Karpathy也將當前最強大模型的規模歸因於訓練數據的複雜性,並補充說大語言模型在記憶方面表現出色,超越了人類的記憶能力。
類比一下,期末周如果你要接受閉卷考試,考試要求根據前幾個單詞背誦書本上的某個段落。
這就是當今大模型的預訓練目標。Karpathy表示,現在的大模型就像是一個貪吃蛇,只想把所有能用的數據全部吞進肚子裡。
它們不僅能背誦常見數字的SHA系列哈算法,還能記住所有領域大大小小的知識。
但是,這種學習方式就像是你為了考試,把整個圖書館和互聯網上的內容通通都背下來。
不可否認能做到這種記憶能力的是天才,但是結果考試時只用到了其中的一頁!
對於這種天才學生——LLM想要做得更好之所以困難,是因為在訓練數據的過程中,思維演示與知識「糾纏」在一起。
而且,一方面從實際應用的角度來看,大模型在部署和運行時面臨著高昂的成本和資源消耗,包括計算資源、存儲資源以及能源消耗等。
小模型更易於在各種設備和場景中進行部署,滿足使用便利性和低功耗的要求。
另一方面,從技術成熟的角度考慮,當通過大模型充分探索和理解了問題的本質和規律後,可以將這些知識和模式提煉並應用於小模型的設計和優化中。
使得小模型在保持大模型同等性能甚至更優性能的前提下,降低規模和成本。
雖然大模型發展遇到了瓶頸,小模型逐漸成為新趨勢,但是Karpathy強調,大模型仍然是需要的,即使它們沒有得到有效的訓練,但是小模型正是從大模型中濃縮而來。
Karpathy預計,每個模型都會不斷改進,為下一個模型生成訓練數據,直到出現「完美的訓練集」。
即使是像GPT-2這樣,擁有15億個參數的已經out模型,當你用這個完美的訓練集來訓練GPT-2時,它可能會變成一個按今天標準來看非常強大且智能的模型。
這個用完美的訓練集訓練過的GPT-2可能在例如大規模多任務語言理解(MMLU)測試中的分數會稍低一些,MMLU測試涵蓋57項任務,包括初等數學、美國歷史、計算機科學、法律等,用以評測大模型基本的知識覆蓋範圍和理解能力。
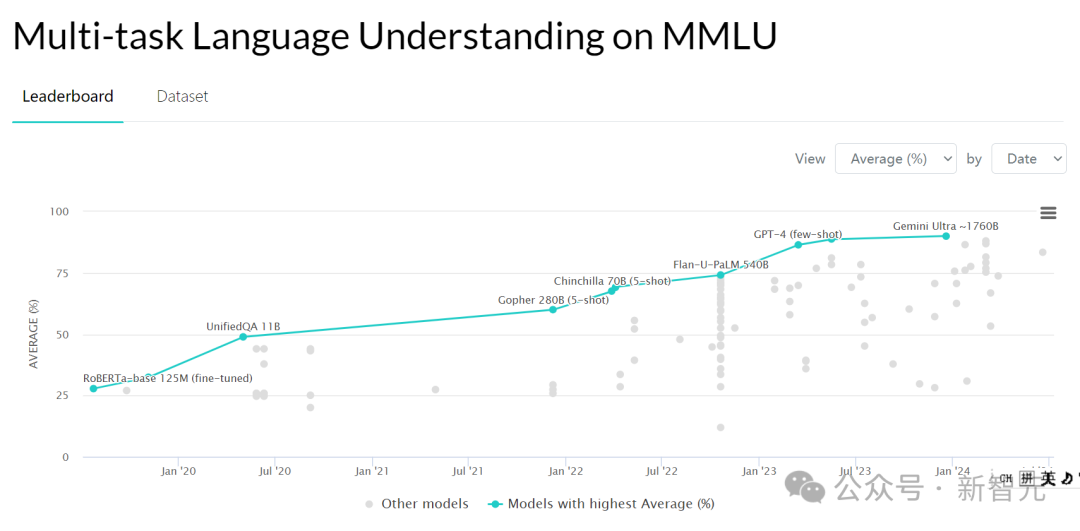
但未來更智能的人工智能模型並不走量取勝,它可以更可靠地檢索信息並驗證事實。
正如一個學霸做開卷考試,雖然不是所有的知識都爛熟於心,但是能夠精準地定位到正確答案。
據報導,OpenAI的Strawberry項目就著重在解決這個問題。
「虛胖」大模型的「瘦身」
正如Karpathy所說,經過海量數據訓練出來的超大模型(如GPT-4),大部分其實是用來記住大量的無關緊要細節的,也就是死記硬背資料。
這與模型預訓練的目的有關,在預訓練階段,模型被要求儘可能準確的複述接下來的內容,這相當於背課文,背的越準得分越高。
雖然,模型能學會裡面反復出現的知識,但是,數據資料有時也會出現錯誤和偏見,模型還要先全部記住再進行微調。
Karpathy相信如果有更高質量的訓練數據集,完全可以訓練出一個規模更小,能力更強,更有推理能力的模型。
可以在超大模型的幫助下,自動生成,清洗出質量更高的訓練數據集。
類似GPT-4o mini,就是用GPT-4清洗出來的數據訓練的。
先把模型做大,然後在此基礎上「瘦身」,這可能是一種模型發展的新趨勢。
做個生動的比喻就像當前的大模型存在數據集過多虛胖的問題,經過數據清洗和大量訓練,搖身一變一身精瘦肌肉的小模型。

這個過程就像是一個階梯式的進化,每一代模型都會幫助生成下一代的訓練數據,直到我們最終得到一個「完美的訓練集」。
OpenAI首席執行官Sam Altman也發表了類似言論,早在2023年4月就宣佈大型AI模型的「時代結束」。
並且,數據質量是AI訓練的關鍵成功因素也越來越成為共識,無論是真實數據還是合成數據。
奧特曼認為,關鍵問題是人工智能系統如何從更少的數據中學到更多的東西。
微軟研究人員在開發Phi模型時也做出了相同的判斷,Hugging Face AI研究人員也同意對於高質量數據集的追求,並發佈了高質量的訓練數據集。
這意味著一味擴張不再是科技巨頭們唯一的技術目標,即使是小型的高質量模型也可以受益於更多、更多樣化、更高質量的數據。
回到更小、更高效的模型可以被視為下一個整合階段的目標,OpenAI的模型發佈就清晰地表明未來的發展方向。
評論區:正確的、中肯的、一陣見血的
Karpathy還提到了特斯拉在自動駕駛網絡上的類似做法。
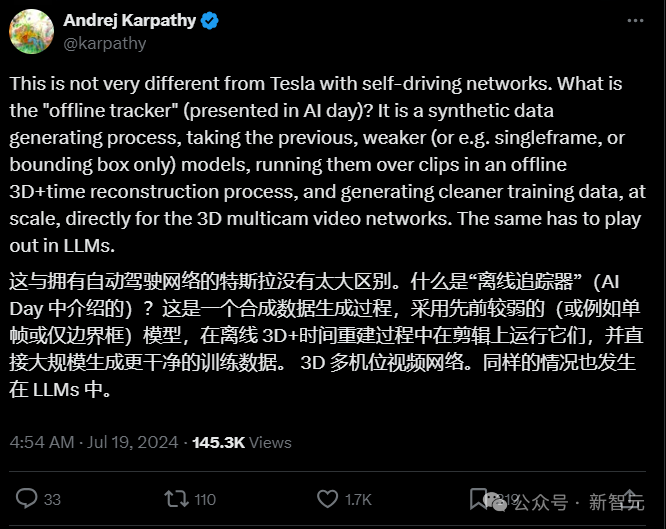
特斯拉有一個叫「離線追蹤器」的東西,通過運行先前的較弱模型,生成更乾淨的訓練數據。
一聽到特斯拉技術被cue走在時代前列,馬斯克迅速趕往評論區:
評論區的網民對於Karpathy的遠見卓識也紛紛表示,臣附議!
對於未來的通用人工智能來說,更小、更高效的人工智能模型可能會重新定義人工智能中的「智能」,挑戰「越大越好」的假設。

《Python機器學習》作者Sebastian Raschka認為,這就像是知識蒸餾,從27B的大模型蒸餾出Gemma-2這樣的小模型。
他也提醒我們,MMLU這種多選題測試,可以測試知識,但不能完全反映實際能力。
也有網民腦洞大開,如果小模型表現得好,那麼術業有專攻,為什麼不用更多的小模型來生成一個個回答呢?
召集10個AI助手,然後讓最聰明的那個做最後的總結,簡直是AI版的智囊團。
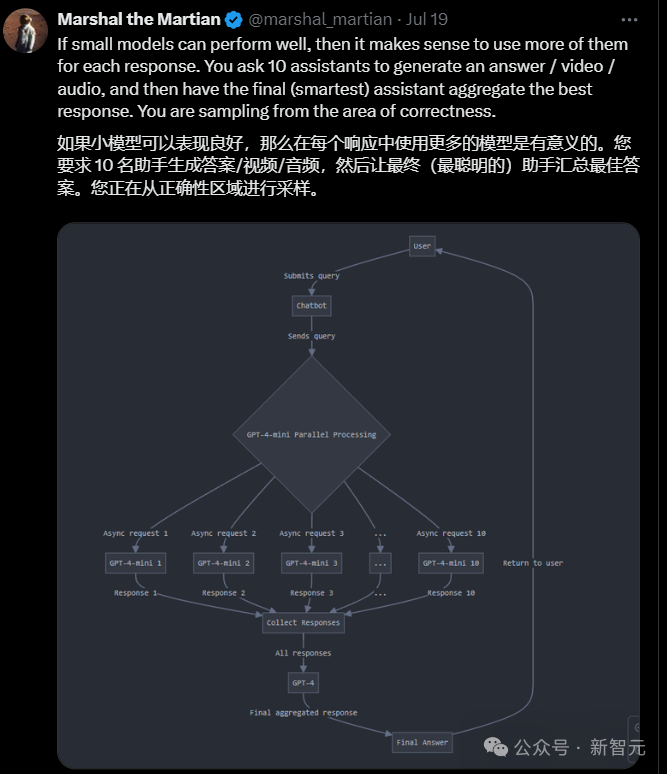
那麼,AGI到底是一個全能大模型,還是來自許多小模型的協作呢?
參考資料:
https://the-decoder.com/ai-models-might-need-to-scale-down-to-scale-up-again/
https://x.com/karpathy/status/1814038096218083497

















