ECCV 2024 | 提升GPT-4V、Gemini檢測任務性能,你需要這種提示範式
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文作者來自浙江大學、上海人工智能實驗室、香港中文大學、雪梨大學和牛津大學。作者列表:吳逸璿,王逸舟,唐詩翔,吳文灝,賀通,Wanli Ouyang,Philip Torr,Jian Wu。其中,共同第一作者吳逸璿是浙江大學博士生,王逸舟是上海人工智能實驗室科研助理。通訊作者唐詩翔是香港中文大學博士後研究員。
多模態大模型(Multimodal Large Language Models,MLLMs)在不同的任務中表現出了令人印象深刻的能力,儘管如此,這些模型在檢測任務中的潛力仍被低估。在複雜的目標檢測任務中需要精確坐標時,MLLMs 帶有的幻覺又讓它常常錯過目標物體或給出不準確的邊界框。為了讓 MLLMs 賦能檢測,現有的工作不僅需要收集大量高質量的指令數據集,還需要對開源模型進行微調。費時費力的同時,也無法利用閉源模型更強大的視覺理解能力。為此,浙江大學聯合上海人工智能實驗室和牛津大學提出了 DetToolChain,一種釋放多模態大語言模型檢測能力的新提示範式。不需要訓練就能讓多模態大模型學會精確檢測。相關研究已經被 ECCV 2024 收錄。
為瞭解決 MLLM 在檢測任務上的問題,DetToolChain 從三個點出發:(1)針對檢測設計視覺提示(visual prompts),比傳統的文字提示(textual prompts)更直接有效的讓 MLLM 理解位置信息,(2)把精細的檢測任務拆解成小而簡單的任務,(3)利用 chain-of-thought 逐步優化檢測結果,也儘可能的避免多模態大模型的幻覺。
與上述的 insights 對應,DetToolChain 包含兩個關鍵設計:(1)一套全面的視覺處理提示(visual processing prompts),直接在圖像中繪製,可以顯著縮小視覺信息和文本信息之間的差距。(2)一套全面的檢測推理提示 (detection reasoning prompts),增強對檢測目標的空間理解,並通過樣本自適應的檢測工具鏈逐步確定最終的目標精確位置。
通過將 DetToolChain 與 MLLM 結合,如 GPT-4V 和 Gemini,可以在無需指令調優的情況下支持各種檢測任務,包括開放詞彙檢測、描述目標檢測、指稱表達理解和定向目標檢測。

-
論文標題:DetToolChain: A New Prompting Paradigm to Unleash Detection Ability of MLLM
-
論文鏈接:https://arxiv.org/abs/2403.12488
什麼是 DetToolChain?
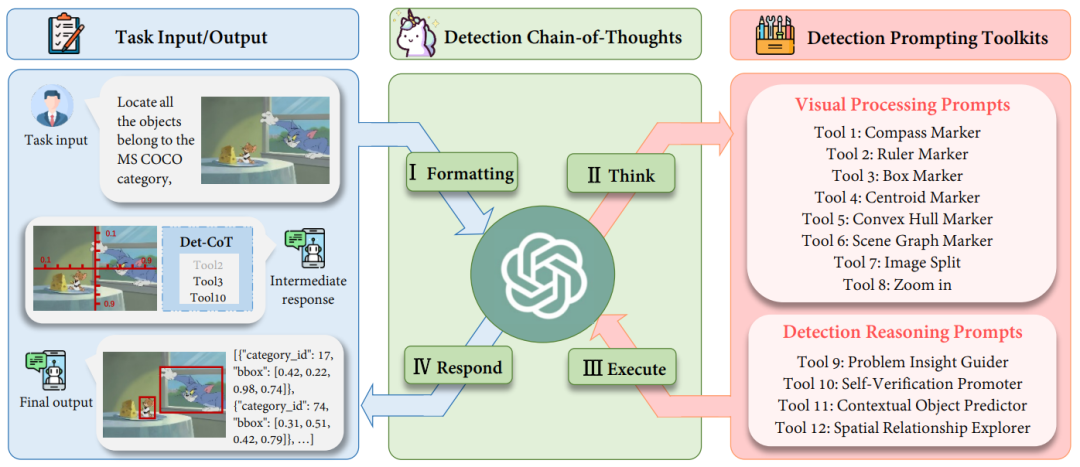
圖 1 DetToolChain 的整體框架
如圖 1 所示,對於給定的查詢圖像,MLLM 被指示進行以下步驟:
I. Formatting:將任務的原始輸入格式轉化為適當的指令模板,作為 MLLM 的輸入;
II. Think:將特定的複雜檢測任務分解為更簡單的子任務,並從檢測提示工具包中選擇有效的提示(prompts);
III. Execute:按順序迭代執行特定的提示(prompts);
IV. Respond:運用 MLLM 其自身的推理能力來監督整個檢測過程並返回最終響應(final answer)。
檢測提示工具包:Visual Processing Prompts
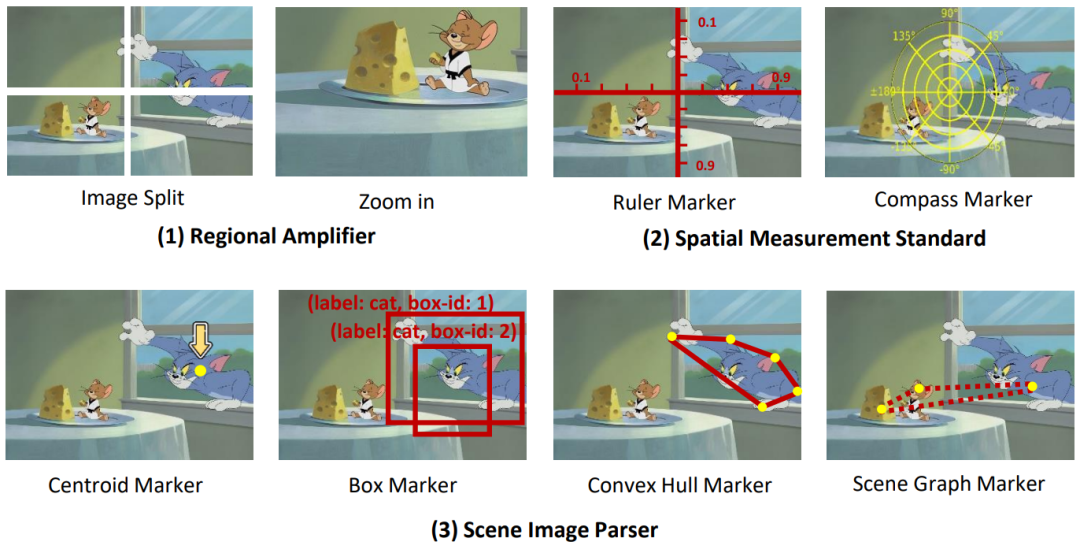
圖 2:visual processing prompts 的示意圖。我們設計了 (1) Regional Amplifier, (2) Spatial Measurement Standard, (3) Scene Image Parser,從不同的角度來提升 MLLMs 的檢測能力。
如圖 2 所示,(1) Regional Amplifier 旨在增強 MLLMs 對感興趣區域(ROI)的可見性,包括將原始圖像裁剪成不同部分子區域,重點關注目標物體所在子區域;此外,放大功能則使得可以對圖像中特定子區域進行細粒度觀察。
(2) Spatial Measurement Standard 通過在原始圖像上疊加帶有線性刻度的尺子和指南針,為目標檢測提供更明確的參考,如圖 2 (2) 所示。輔助尺子和指南針使 MLLMs 能夠利用疊加在圖像上的平移和旋轉參考輸出準確的坐標和角度。本質上,這一輔助線簡化了檢測任務,使 MLLMs 能夠讀取物體的坐標,而不是直接預測它們。
(3) Scene Image Parser 標記預測的物體位置或關係,利用空間和上下文信息實現對圖像的空間關係理解。Scene Image Parser 可以分為兩類:首先,針對單個目標物體,我們用質心、凸包和帶標籤名稱及框索引的邊界框標記預測的物體。這些標記以不同格式表示物體位置信息,使 MLLM 能夠檢測不同形狀和背景的多樣物體,特別是形狀不規則或被大量遮擋的物體。例如,凸包標記器標記物體的邊界點並將其連接為凸包,以增強對形狀非常不規則的物體的檢測性能。其次,針對多目標,我們通過場景圖標記器(scene graph marker)連接不同物體的中心,以突出圖像中物體之間的關係。基於場景圖,MLLM 可以利用其上下文推理能力來優化預測的邊界框並避免幻覺。例如,如圖 2 (3) 所示,Jerry 要吃乳酪,因此它們的 bounding box 應該非常接近。
檢測提示工具包:Detection Reasoning Prompts

為了提高預測框的可靠性,我們進行了檢測推理提示(如表 1 所示),以檢查預測結果並診斷可能存在的潛在問題。首先,我們提出了 Problem Insight Guider,突出困難問題並為查詢圖像提供有效的檢測建議和相似例子。例如,針對圖 3,Problem Insight Guider 將該查詢定義為小物體檢測的問題,並建議通過放大沖浪板區域來解決它。其次,為了利用 MLLMs 固有的空間和上下文能力,我們設計了 Spatial Relationship Explorer 和 Contextual Object Predictor,以確保檢測結果符合常識。如圖 3 所示,衝浪板可能與海洋共現(上下文知識),而衝浪者的腳附近應該有一個衝浪板(空間知識)。此外,我們應用 Self-Verification Promoter 來增強多輪響應的一致性。為了進一步提升 MLLMs 的推理能力,我們採用了廣泛應用的 prompting 方法,例如 debating 和 self-debugging 等。詳細描述請見原文。
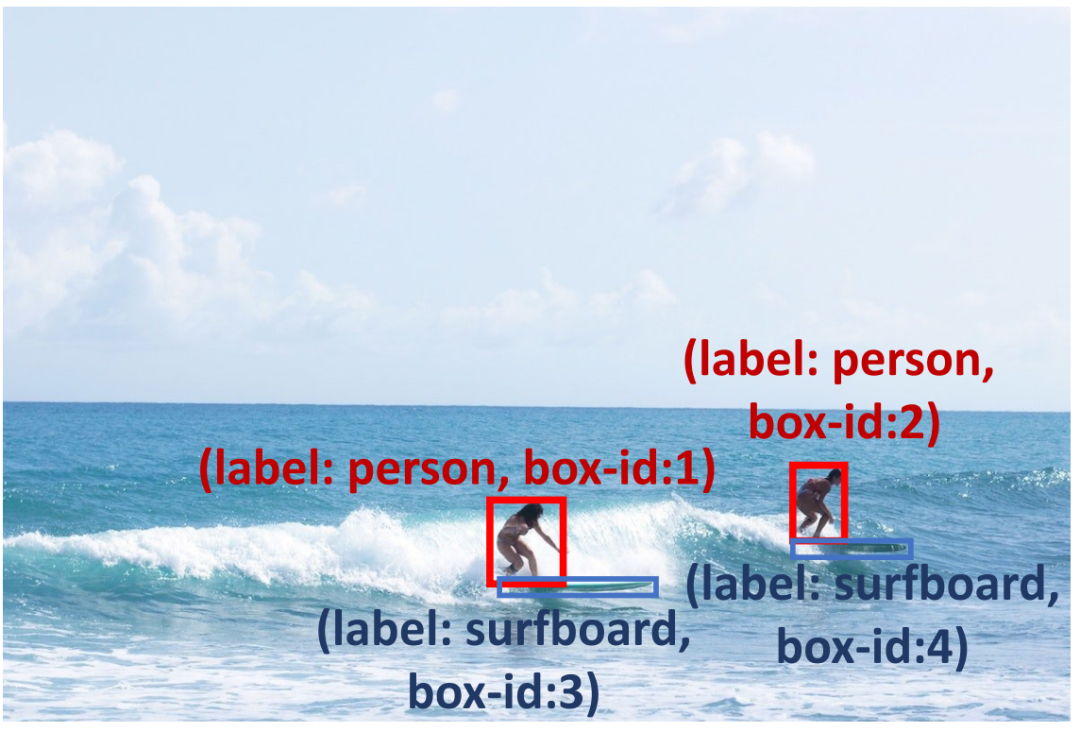
圖 3 檢測推理提示可以幫助 MLLMs 解決小物體檢測問題,例如,利用常識定位人腳下的衝浪板,並鼓勵模型在海洋中檢測衝浪板。

圖 4 一個 DetToolChain 應用於旋轉目標檢測的例子(HRSC2016 數據集)
實驗:免訓練也能超越微調方法

如表 2 所示,我們在 open vocabulary detection(OVD)上評估了我們的方法,測試了在 COCO OVD benchmark 中 17 個新類、48 個基礎類和所有類的 AP50 結果。結果顯示,使用我們的 DetToolChain,GPT-4V 和 Gemini 的性能均顯著提升。

為了展示我們的方法在指稱表達理解上的有效性,我們將我們的方法與其他零樣本方法在 RefCOCO、RefCOCO + 和 RefCOCOg 數據集上進行了比較(表 5)。在 RefCOCO 上,DetToolChain 使得 GPT-4V 基線在 val、test-A 和 test-B 上的性能分別提升了 44.53%、46.11% 和 24.85%,展示了 DetToolChain 在 zero-shot 條件下優越的指稱表達理解和定位性能。