Nature最新封面:AI 訓練 AI?也許越來越笨
當前,在愈發火熱的大模型行業,Scaling Law 被證明依然奏效。
問題是,一旦由人類生成的高質量數據(如書籍、文章、照片、影片等)用盡,大模型訓練又該如何進行?
目前,一個被寄予厚望的方法是「用大模型自己生成的數據來訓練自己」。事實上,如果後代模型的訓練數據也從網絡中獲取,就會不可避免地使用前代模型生成的數據。
然而,來自牛津大學和劍橋大學的研究團隊及其合作者,卻給這一設想「潑了一盆冷水」。
他們給出了這樣一個結論:模型在訓練中使用自身生成的內容,會出現不可逆轉的缺陷,逐漸忘記真實數據分佈,從而導致模型性能下降。
即「模型崩潰」(Model Collapse)。
相關研究論文以「AI models collapse when trained on recursively generated data」為題,已發表在權威科學期刊 Nature 上。
但他們也表示,用一個舊模型生成的數據去訓練一個新模型,並非不可行,但必須對數據進行嚴格的過濾。
在一篇同期發表的新聞與觀點文章中,來自杜克大學的 Emily Wenger 認為,「論文作者沒有考慮模型在由其他模型生成的數據上訓練時會發生什麼,他們專注於模型在自身輸出上訓練的結果。一個模型在訓練其他模型的輸出時是否會崩潰還有待觀察。因此,下一個挑戰將是要搞清楚模型崩潰發生的機制。」

什麼是模型崩潰?
本質上,當大模型生成的數據最終汙染了後續模型的訓練集時,就會發生「模型崩潰」。
像 GMM 和 VAE 這樣的小型模型通常是從頭開始訓練的,而LLM 重新訓練的成本非常高,因此通常使用如 BERT4、RoBERTa5 或 GPT-2 這樣在大型文本語料庫上預訓練的模型進行初始化,然後針對各種下遊任務進行微調。
那麼當語言模型依次使用其他模型生成的數據進行微調時會發生什麼?
為此,研究團隊使用 OPT-125m 語言模型進行實驗,並使用 wikitext2 數據集進行微調。實驗結果表明,無論是否保留原始數據,模型崩潰現象都發生了。隨著迭代次數的增加,模型生成的樣本中低困惑度樣本的數量開始積累,表明模型開始忘記真實數據分佈中的尾部事件。並且,與原始模型相比,後續迭代模型的性能有所下降,表現為困惑度增加。此外,模型生成的數據中包含大量重覆的短語。
 圖 | 受模型崩潰影響的 OPT-125m 模型的文本輸出示例-模型在幾代之間退化。
圖 | 受模型崩潰影響的 OPT-125m 模型的文本輸出示例-模型在幾代之間退化。想像一下一個生成 AI 模型負責生成狗的圖像。AI 模型會傾向於重現訓練數據中最常見的狗的品種,因此可能會過多地呈現金毛,而非法鬥。如果隨後的模型在一個 AI 生成的數據集中進行訓練,而這個數據集中過多地呈現了金毛,這個問題就會加劇。經過足夠多輪次的過多呈現金毛後,模型將忘記諸如法鬥這樣的冷門品種的存在,只生成金毛的圖像。最終,模型將崩潰,無法生成有意義的內容。
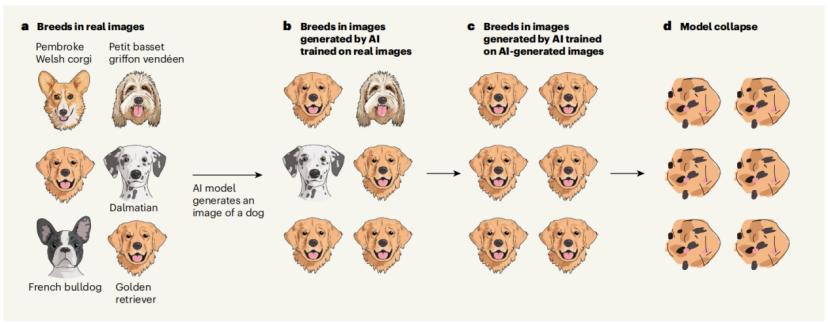 圖 | 模型會逐漸忽視訓練數據中不常見的元素。
圖 | 模型會逐漸忽視訓練數據中不常見的元素。總而言之,模型會逐漸忘記真實語言中出現的低概率事件,例如罕見詞彙或短語。這會導致模型生成的內容缺乏多樣性,並無法正確地模擬真實世界的複雜性。並且,模型會逐漸生成與真實世界不符的內容,例如錯誤的日期、地點或事件。這會導致模型生成的內容失去可信度,並無法用於可靠的信息檢索或知識問答等任務。此外,模型會逐漸學習到訓練數據中的偏見和歧視,並將其反映在生成的內容中。
為何會發生?
模型崩潰是一個退化過程,模型生成的內容會汙染下一代的訓練數據,導致模型逐漸失去對真實數據分佈的記憶。模型崩潰分為早期和晚期兩種情況:在早期階段,模型開始失去對低概率事件的信息;到了晚期階段,模型收斂到一個與原始分佈差異很大的分佈,通常方差顯著減小。
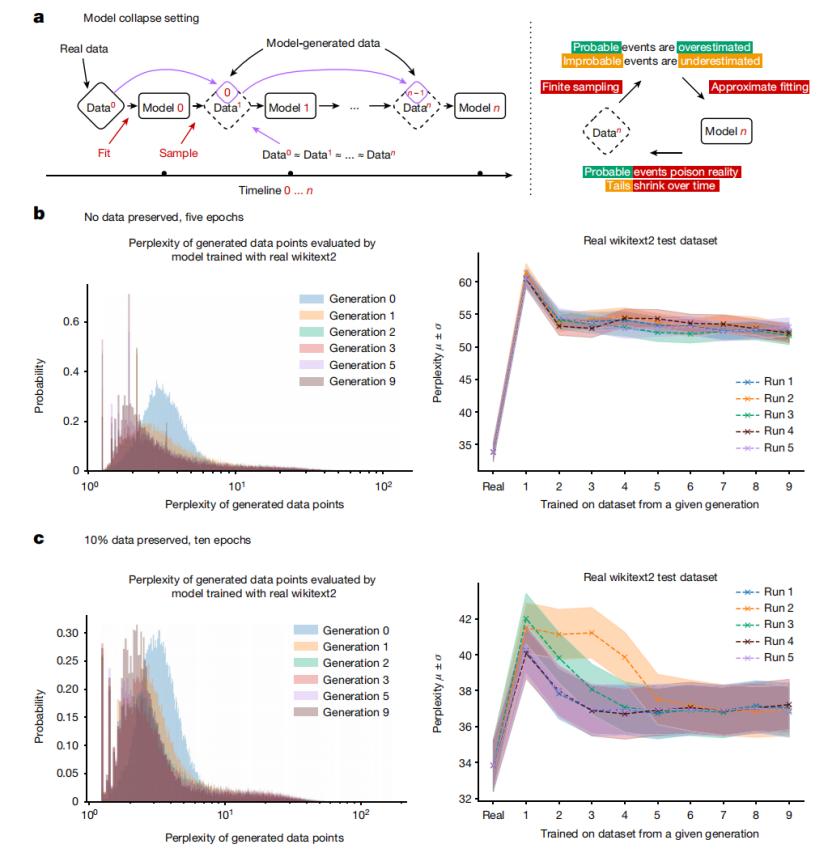 圖 | 對學習過程中反饋機制的高層次描述。
圖 | 對學習過程中反饋機制的高層次描述。隨著代數的增加,模型傾向於生成由最初模型更可能生成的樣本。同時,後代模型的樣本分佈尾部變得更長。後代模型開始生成原始模型絕不會生成的樣本,即它們開始基於先前模型引入的錯誤誤解現實。儘管在生成數據上訓練的模型能夠學習部分原始任務,但也會出現錯誤,如困惑度增加所示。
模型崩潰主要由三種誤差累積導致:
1. 統計近似誤差:
由於樣本數量有限,模型無法完全捕捉到真實數據分佈的所有細節。隨著時間的推移,低概率事件(即分佈的尾部)會逐漸消失,因為它們被采樣的概率很低。
隨著模型訓練代數的增加,這種誤差會不斷累積,導致模型最終收斂到一個與原始分佈完全不同的分佈,其尾部幾乎為零,方差也大大減小。
2. 函數表達能力誤差:
神經網絡等函數近似器的表達能力是有限的,無法完美地逼近任何分佈。
這種誤差會導致模型在逼近真實分佈時產生偏差,例如,將高密度區域分配到低密度區域,或者將低密度區域分配到高密度區域。
隨著模型訓練代數的增加,這種誤差會不斷累積,導致模型最終收斂到一個與原始分佈完全不同的分佈,其尾部幾乎為零,方差也大大減小。
3. 函數近似誤差:
學習過程的局限性,例如隨機梯度下降的結構偏差或目標函數的選擇,也會導致模型產生誤差。
這種誤差會導致模型在逼近真實分佈時產生偏差,例如,過擬合密度模型導致模型錯誤地外推數據,並將高密度區域分配到訓練集支持範圍之外的低密度區域。
隨著模型訓練代數的增加,這種誤差會不斷累積,導致模型最終收斂到一個與原始分佈完全不同的分佈,其尾部幾乎為零,方差也大大減小。
可以避免嗎?
研究團隊認為,用 AI 生成數據訓練一個模型並非不可能,但必須對數據進行嚴格過濾。
首先,在每一代模型的訓練數據中,保留一定比例的原始數據,例如 10% 或 20%。這樣可以確保模型始終接觸到真實世界的樣本,避免完全依賴於模型生成的內容。定期對原始數據進行重采樣,並將其添加到訓練數據中。這樣可以保證訓練數據始終保持新鮮,並且能夠反映真實世界的最新變化。
其次,可以使用多樣化的數據。例如,除了模型生成的內容,還應該使用人類產生的數據作為訓練數據。人類數據更加真實可靠,可以幫助模型更好地理解真實世界的複雜性和多樣性。此外,可以使用其他類型的機器學習模型生成的數據作為訓練數據,例如強化學習模型或模擬器。這樣可以保證訓練數據來源的多樣性,並避免過度依賴於單一類型的模型。
最後,可以嘗試改進學習算法。研究更魯棒的語言模型訓練算法,例如對抗訓練、知識蒸餾或終身學習。這些算法可以幫助模型更好地處理訓練數據中的噪聲和偏差,並提高模型的泛化能力。
儘管這一警示似乎對當前的生成式 AI 技術以及尋求通過它獲利的公司來說都是令人擔憂的,但是從中長期來看,或許能讓人類內容創作者看到更多希望。
研究人員表示,在充滿 AI 工具及其生成內容的未來世界,如果只是作為 AI 原始訓練數據的來源,人類創造的內容將比今天更有價值。
本文來自微信公眾號「學術頭條」,作者:學術頭條,36氪經授權發佈。