Nature封面:AI訓AI,越訓越傻
白交 發自 凹非寺
量子位 | 公眾號 QbitAI
AI訓練AI,可能會讓AI變傻?!
來自牛津、劍橋等學校機構的研究人員最新發現,使用合成數據訓練,大模型可能會崩潰。其研究成果被選為最新的Nature封面。
直接一個:GARBAGE OUT!

要知道,現在絕大部分科技公司的大模型都在用合成數據來緩解「數據荒」。這下無疑是整個行業澆了一波冷水。
研究團隊給了這樣一個例子。
他們測試了Meta的OPT-125m模型,詢問了關於中世紀建築的相關信息。

每一次微調都是由上一次生成的數據來訓練。結果前面幾輪迴答還好。結果就在第九次,就開始胡說八道……
扯到兔子是什麼鬼?!
該論文主要作者表示,他們曾考慮過合成數據可能對大模型造成誤差,但未曾預料到模型的惡化速度會如此迅速。
三個誤差導致模型崩潰
首先,團隊定義了什麼是模型崩潰。
模型崩潰是一個退化過程,模型生成的內容會汙染下一代的訓練數據集。而在被汙染的數據上訓練之後,新一代模型就容易誤解現實。
以此循環往複,一代更比一代差。
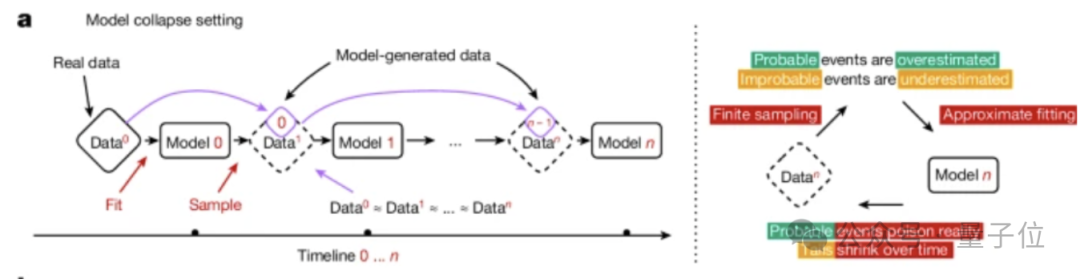
按照時間推移,主要分為兩種情況:早期模型崩潰和晚期模型崩潰。
早期模型崩潰中,模型開始丟失一些尾部信息。(類似概率分佈中一些低概率事件) 而在晚期模型崩潰,模型將收斂到同原始分佈幾乎沒有任何相似之處。
這一過程的發生,同模型設計、學習過程和所用數據質量有關。
具體到理論中,主要包括了這三個誤差導致大模型同原始模型的偏離。
-
統計近似誤差。這是主要類型的誤差,由於樣本數量有限而產生,並隨著樣本數量趨於無窮大而消失。這是因為在重新采樣的每一步中信息都有可能丟失,這種概率不為零。
-
函數表達性誤差。這種誤差是由於函數近似表達能力有限而產生的。特別是,神經網絡只有在其規模達到無窮大時才是通用近似值。不過,在沒有其他兩種誤差的情況下,這種誤差只會發生在第一代。
-
函數近似誤差。主要由學習過程局限性引起,例如隨機梯度下降的結構偏差或目標的選擇。這種誤差可以看作是在無限數據和每一代都具有完美表達能力的情況下產生的誤差。
對語言模型的影響
隨後研究人員評估了模型崩潰對語言模型的影響。由於從頭開始訓練大模型成本非常高,他們選擇評估語言模型最常見的設置:微調設置。
每個訓練週期都從具有最新數據的預訓練模型開始。訓練數據來自另一個經過微調的預訓練模型。
他們用Meta因果語言模型OPT-125m,在wikitext2上進行了微調。
為了從訓練好的模型中生成數據,團隊使用了five-way波束搜索。他們將訓練序列設為 64 個token長度;然後對於訓練集中的每個token序列,要求模型預測下一個64個token。
他們會瀏覽所有原始訓練數據集,並生成一個相同大小的人工數據集。如果模型的誤差為0,它就會生成原始的wikitext2數據集。
為了進一步感受區別,他們採用兩種不同的設置:一組是除了最開始訓練,後續過程沒有任何原始訓練數據;另一組則是保留10%的原始數據。
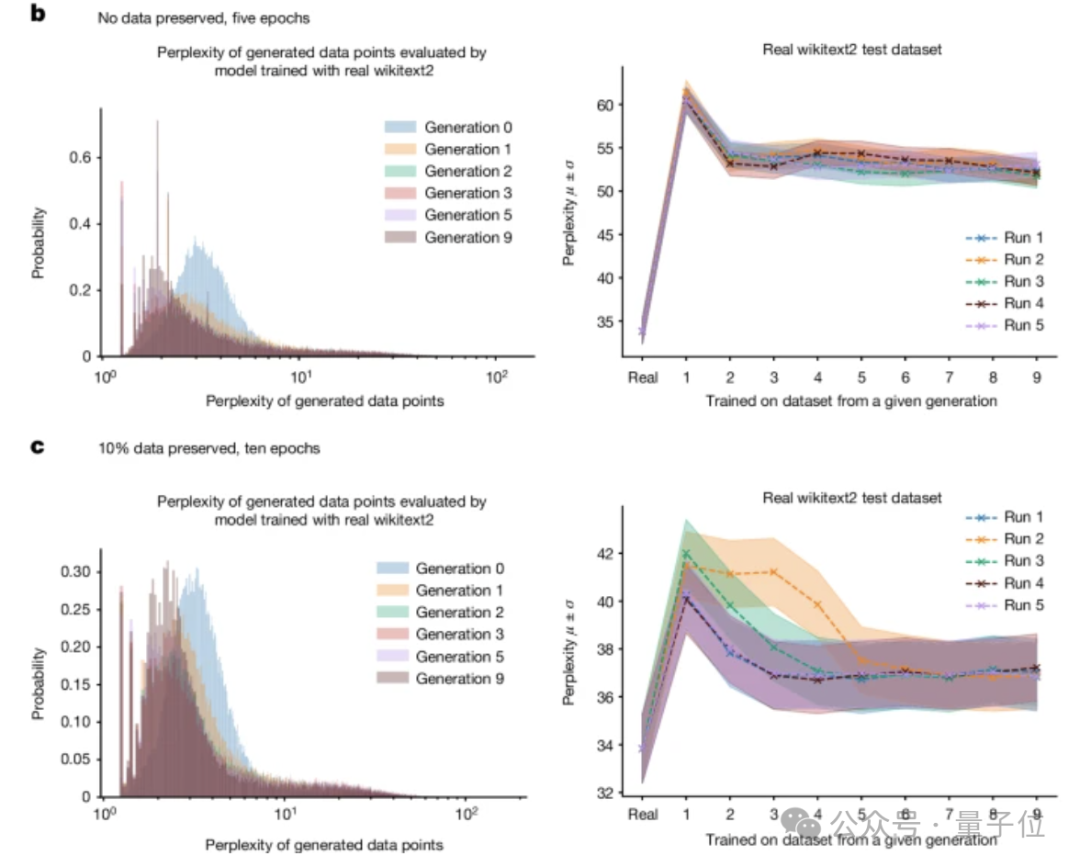
結果顯示,隨著時間推移,模型產生的錯誤會增加。在模型完全崩潰之前,它還會導致模型遺忘數據集中低概率事件,他們的輸出也變得更加同質化。最終也就出現了開頭這一現象。
另外在VAE、GMM模型中看到了類似模型崩潰的現象。

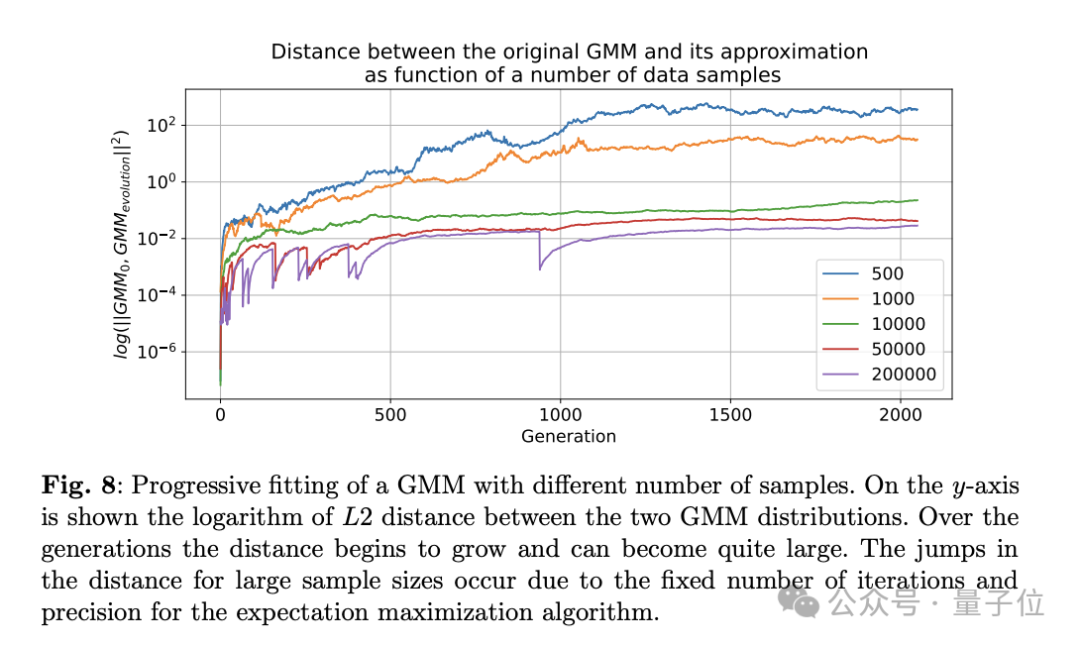
來自杜克大學的Emily Wenger教授表示,到目前為止,要緩解這一問題並非易事。
有領先的科技公司已經部署了一項技術,即嵌入「水印」——
標記AI生成的內容,讓其在訓練數據中排除。但困難在於,這需要科技公司之間的協調,因此不太具有商業可行性。
這樣一來,那從之前互聯網獲取數據的公司,他們訓練的模型更能代表現實世界。所以,最開始那一波大模型算是有了正選優勢。
對於這一觀點,你怎麼看呢?
參考鏈接:
[1]https://www.nature.com/articles/d41586-024-02420-7
[2]https://www.nature.com/articles/d41586-024-02355-z
[3]https://www.nature.com/articles/s41586-024-07566-y