騰訊元寶治好了我的信息焦慮症

5 大模型橫評,只有它 500 字說清 10 萬字論文的事。
作者丨馬蕊蕾、林傑鑫
編輯丨林傑鑫
最近翻相冊的時候翻到3月份的一張圖片,恍惚間發現從事AI之後自己的閱讀量一直在暴漲。
大模型重構了很多行業工作流中的思考角色,也導致在這個行業的人一直都有信息攝取焦慮症。因為各行各業搞研究的人腦洞大開。比如史丹福大學用AI扮演不同的人搞了個AI社會啟發清華大學用AI開遊戲設計公司,後來就有AI模擬人類社會發展6000年,發現AI人類為了活下去會變得自私。這些都還好,看著挺趣味的也好理解,過家家嘛。


最頭疼的就是那些個鬼:AI成功編輯人類基因,AI學會預測等離子體撕裂推進可控核聚變,AI設計了一套無需人類示範的歐幾里得平面幾何定理證明系統。(別看了,頭痛,偏偏這些讓我上課瞌睡的卻成了我的工作內容。)
很長一段時間我都在測試各家的大模型讀論文的能力,自己摸索了一套prompt:
總結論文內容,研究背景是什麼,採用了什麼方法論證,取得了什麼積極性的突破,對比同類型研究有什麼優勢?將對普通人的生活產生什麼影響?如果技術方法複雜,請用類比或比喻的手法輔助我理解。

這段話可以快速定位研究的目的和用途,同時瞭解這些研究會對咱這些平頭老百姓會有什麼影響。問題在於,大部分論文動不動幾萬字到十幾萬字的,有很多各行業的專業術語,AI能讀,但給出來的結果往往是一個很空的大框架。更別說用比喻的手法解讀一些內容了,因為AI的理解不夠深入,也就不能做到用通俗易懂的話輔助理解…..

半年前我發現最好用的還是kimi,所以2個月時間我用他讀了1183萬字的論文,整個人的靈魂都昇華了。當然,人嘛總是喜新厭舊,過了半年時間了,這會兒我也想看看其他家AI做的咋樣,來一場橫評。於是我打開我跟kimi的聊天記錄打算看看以往遇到什麼問題,然後就戴上了痛苦面具……


是的,看著過去的聊天記錄我想起來kimi只會用OCR識別字但不會讀圖,所以很多論文的統計圖kimi都無法識別,導致有些論文有大量曲線圖、數據圖的時候。kimi直接燈下黑睜眼瞎,像上面的圖屬於AI模擬人類社會發展1000代之後,人類性格轉變曲線,如果論文沒具體闡述,我是完全不知道如何變化的…也就無法獲取關鍵信息。

所以這次評測我打算找一個長文理解能力不輸kimi,然後又有圖文理解能力的,但最好還是國內的,方便我隨時使用。
1
初階圖片理解測試
首先是來一輪簡單的圖片理解測試。

在這裏做個免責聲明:大家都知道我這個人呢測試AI喜歡刁鑽。沒辦法,經常有些AI大廠就喜歡拿大家用過的經典測試題鑽漏洞,比如識別狗跟炸雞這題以前很火,有一天AI突然集體開竅了,然後有網民換了下圖片順序,AI又識別不出來了。(嗯,大夥兒自己琢磨)

所以下面這輪測試我本來打算用廣東2016年的高考語文題目來挑戰一下AI圖片閱讀理解,但我怕這東西被AI偷偷摸摸練過,所以兄弟靈機一動,給圖片打了一堆噪點。
這一輪就不欺負kimi了。來一輪已經確定有識別圖片能力的大模型來一場皇城pk。阿里的通義千問、百度文心一言、字節豆包、騰訊元寶。

注意我這裏用的是原圖測試,我發現通義可以準確識別數字,但是無法深入解讀表情、或者臉上的巴掌、吻,為了確認實驗的嚴謹,我又上傳了一張停車場的圖片,發現它是能準確識別福特汽車的logo,所以也就不存在不能讀圖這一情況,而是他沒訓練過。

這是豆包的表現,連數字都讀錯了,那咱也就不繼續了…..

文心一言……雖然讀出了分數,但是後面我問他看到巴掌和吻了嗎…..這傢伙回我一句「嘻嘻」,我&*%$#?!

說實話到元寶我已經放棄了,因為在我印象中,文心一言、通義千問、豆包都比元寶早出至少半年,而且元寶在我這確實沒什麼存在感。結果,兄弟咋回事?這就讀出來了,而且還是加了噪點的圖片???騰訊不聲不響憋了個大的,然後當我問到這些表情特徵的時候他還做了可能發生的情況的解讀。
所以第一場pk,元寶取得領先優勢。
那麼既然各家確定有讀圖能力,接下來就加大難度,上有圖文的長論文。
2
長文精讀能力測試
論文名:《An evolutionary model of personality traits related to cooperative behavior using a large language model》
這篇論文內容,主要講了用大模型生成不同性格的AI,模擬人類社會發展1000代,最後AI居然集體變為自私人格,自然雜誌上的新研究揭露,AI在不受約束的情況下,可能整體都會趨向於自私。

主要是論文中有一大坨的各種曲線圖,要想更好的理解AI人類為了生存做出的性格改變就必須結合曲線圖理解。
所以這裏想看一下,各家大模型對於長文以及圖片的總結能力。鑒於kimi有優秀的長文理解能力,所以這裏還是拉上他來作為一個衡量各家質量的標杆。但這把不再是中國大模型內戰,而是拉上目前國外目前T0級別的claude,直接上強度。
Kimi
提示詞:總結論文內容,闡述研究背景,研究方法以及成果,實驗者提供什麼數據支撐他的實驗。

我先是讓kimi總結論文內容大致瞭解詳情,得知這是一篇關於AI模擬人類社會發展和人類性格變化的論文。

於是我追問人類迭代的趨勢是什麼,kimi也給出瞭解答,但這個解答說實話沒有將全文連貫起來讀。

在後續的追問中也沒體現出這張圖表的波動。而是大致概括為 先自私然後偏向合作然後又可能變自私,但這個可能就很致命,因為在第900代的時候,所有AI是大幅度變自私。也就是kimi獲取的信息不準確。
騰訊元寶

元寶我照例先問主要內容,我覺得訓元寶的估計沒少研究用戶閱讀習慣或者乾脆就是一群有高效閱讀強迫症的人練出來的。因為它生成的格式主次分明,從研究背景、研究方法、實驗設計、結果分析、總體結論。感覺就像是讀書時拿了學霸同學的筆記。而且用什麼模型進行實驗、關鍵數據包括哪些,都有呈現。這是同樣提示詞下,kimi所不具備的。

但相比於kimi,最大的差異點我認為還是在迭代趨勢這裏。元寶是能講出曲線發展的波動。在進化過程中,初始階段,持續到大約第300代後,合作比例迅速上升,到第350代左右佔比達到0.55,然後在第450代左右下降到約0.40。接著,合作比例反復增加和減少,到第850代左右達到最高值約0.75,之後迅速下降到0.15左右。
根據數據波動又總結出出在進化過程中,AI人類的性格基因在二維空間中的分佈顯示出多次轉變,反映了合作和自私性格特徵的交替出現。也就是AI人類的進化一直在自私和合作之間反復橫跳,並且給出了具體的時間週期。(歷史果然是個車輪啊~)

而且,我還發現它左下角居然多了一個按鈕——深度閱讀該文檔,一點進去,元寶老爺今天我給您磕一個,此後承蒙不棄,多多帶我。
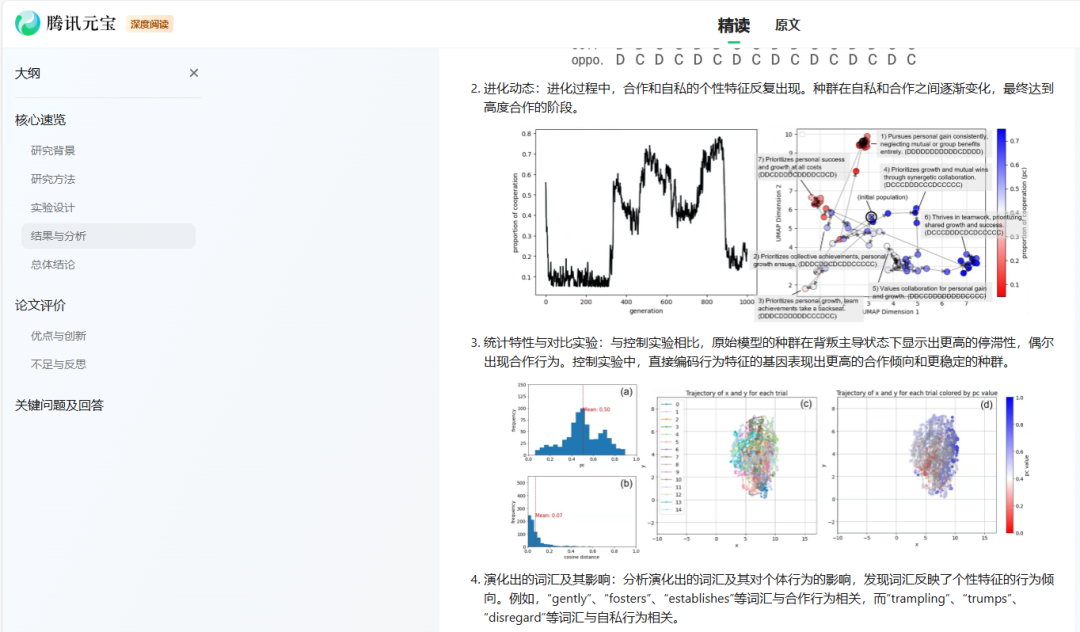
因為它直接將圖表和內容結合講述,把論文變成課件,以往我打開論文看到圖表人麻了,因為我還得看小字去瞭解這是描述什麼的圖表。現在用元寶打開圖表,我人炸了,因為我直接就悟了。
而且我懷疑騰訊是不是去哪裡請來了金牌備課講師,整個ui界面的視覺設計很符合閱讀習慣,左邊有論文的大綱,正文部分配合著圖來看論文,如果不懂,還可以實時對內容進行提問,真的很懂我。


拉到底人家還擺了一個關鍵問題及回答,這玩意看得我虎軀一震。兄弟們,參加過答辯的應該都知道這功能的重要性吧?這是元寶教授在跟你模擬畢業答辯呢,考試前老師在給你劃重點呢,還可以刷新不同的問題。

人家甚至會對論文進行評價,換句話說自己寫的論文上傳給元寶,元寶教你改論文,完事了還跟你模擬答辯,寶子哥,不僅看論文厲害,我發現估計寫論文和模擬答辯還有奇效。
通義千問
整體思路看起來不錯,開頭簡潔明晰的介紹了論文的研究重點,正文從研究的特點和成果進行展示,但是深究具體內容,會發現不是很全面,有些模糊,讀完一席話,勝似一席話。
Claude-3.5

一眼看過去,Claude的回覆真的很簡潔,主要概括了論文的一些要點,沒有特別成體系,但不得不說可能因為字數少,我竟然看進去了。但過於簡潔,看完之後,我就沒有然後了,對於我這個剛入門學習的人來說,不太友好。

當然,通義千問和Claude-3.5在內容上也做到了元寶講的總結出具體的數值,不同的是,Claude-3.5能清晰知道具體結論對應哪幅圖,這一點上通義千問沒有。但Clude3.5沒有像元寶那樣把圖放在那講,還得去翻圖片來回滑動,看起來很麻煩。
從kimi、通義千問、騰訊元寶和Claude3.5的測試中,我意外還發現kimi和騰訊元寶的交互設計做的很絲滑。當提出問題得到相應的反饋後,這兩家有一點非常Nice,點擊生成答案的右下角的分享標識,他們都可以快速生成內容的長圖或者鏈接。
其實通義千問,點擊分享也會有相應交互,但是目前只能複製答案的鏈接,沒有生成圖片的功能,通義啊,這裏可以改進一下下。
除了論文總結能力,讀研報不知道各家表現怎麼樣,我們再試一試,看看效果。
3
分析研報
接著扔一個《2024巴黎奧運會熱度趨勢洞察》PDF,並加上幫我分析一下這份研報,概括出最重要的信息,字數不要超過500字。
通義千問
很簡單的總結了一段話,細看內容只總結了平台和品牌合作,概括不太全面。

騰訊元寶

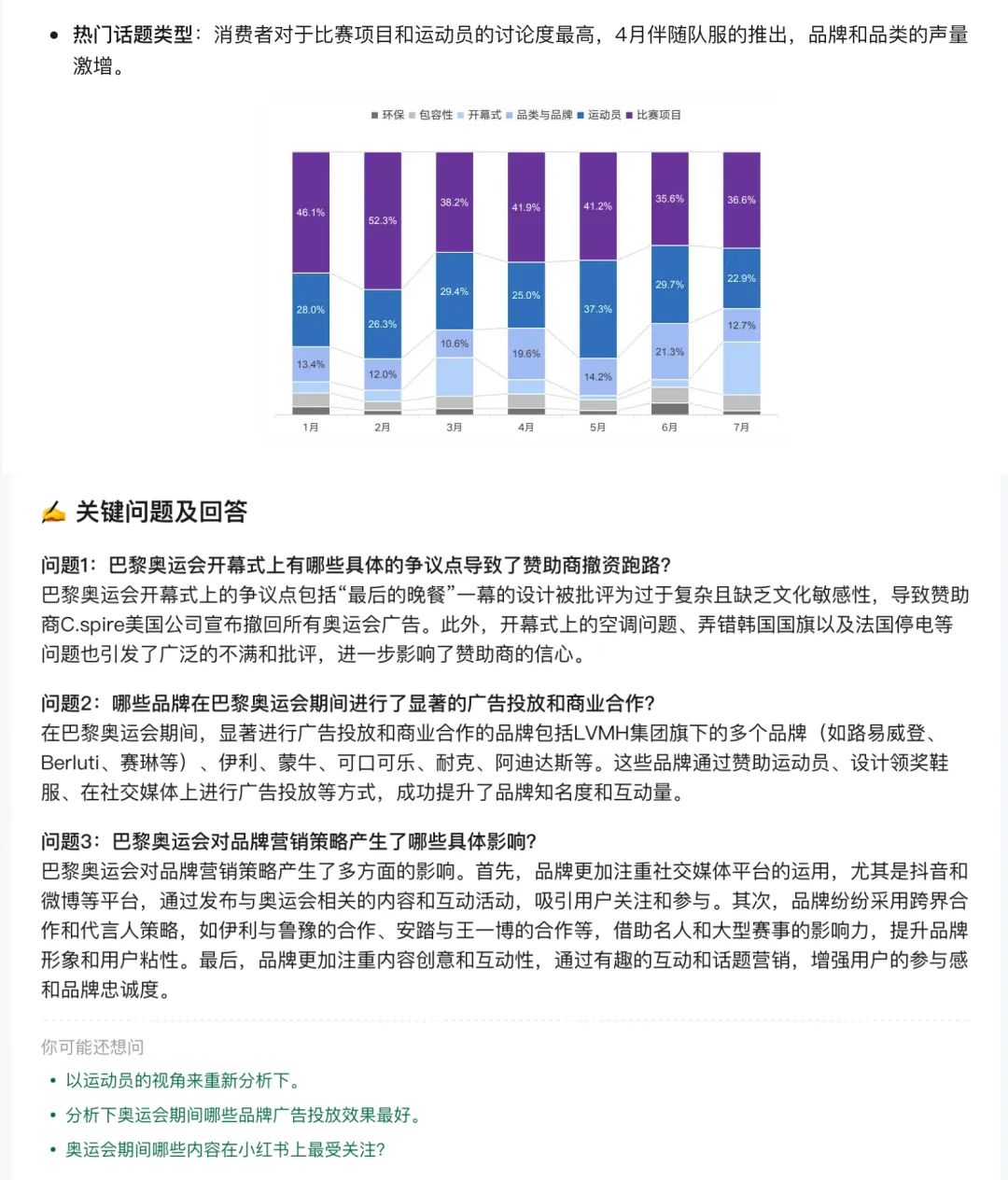
這裏元寶我又i了,總結了研報的核心觀點,還從奧運會熱度掃瞄、話題洞察、品牌洞察分別概括了具體內容,很清晰。
如果作為一名短影片運營或者商家,你就會發現元寶的信息有多珍貴。首先他會跟你說主要熱點有哪些。緊接著又指出兩個熱度最高的社交平台微博和抖音,其中微博是內容量佔了全網68.3%,抖音互動奧運話題互動量佔全網69.4%。
但元寶又指出,品牌方主要在小紅書進行商業投放,原因是小紅書熱門話題更注重體育項目和運動員,抖音則以愛國話題為主。同時從消費者趨勢來看,小紅書女性用戶多,抖音男性用戶多,25~34歲是主要人群。這下消費者畫像不就一下子清晰了?每個研報如果都能這麼總結,我一天能看100份。
重點是它的深度閱讀依舊可以總結重點信息還帶配圖的那種,每次精讀的尾聲部分,還能再來一波關鍵問題的解答。
Claude-3.5

中規中矩,很簡潔的概括了一些想要看到的信息。整體體驗下來,元寶確實在長文精讀方面的能力更強,在內容和文本格式方面都很在線,我感覺它很懂用戶的閱讀使用習慣,深度閱讀模式的大綱、圖文搭配、實時對文章進行提問的能力,用起來一整個都很舒適!
4
番外測試篇
當然最近網上也很流行測AI理解梗圖的能力和數學邏輯推理,所以這裏也測點網上大家都喜歡測的,看看各家的表現。

上傳一張表情包,問:這個表情包實際代表什麼意思?
通義千問
能看出它有很認真的去理解表情包,物理層面有了,缺了點化學反應,幽默和倦怠點題了。
騰訊元寶

元寶真是懂打工人的,直接明了的對準一個情緒。
「在抱怨某個無法解決的問題」or「對某種情況感到無能為力」。
Claude3.5

這一波Claude讀出了很多種複雜的情緒,看上去比我更會形容日常的無奈。
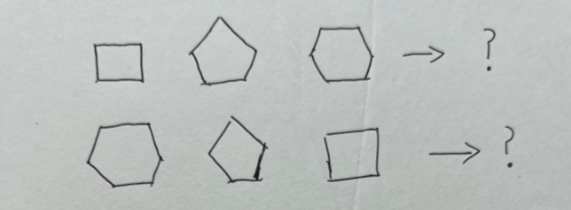
接下來是簡單的數學邏輯推理,為了防止題目被AI訓練過,所以我對同個圖形進行順序顛倒的測試。
文心一言

這不,文心一言就漏出雞腳了,正向回答沒問題,反向回答卻是比正方形更簡單或與正方形相似……

通義千問正常通關。
元寶也正常通關。

插個題外話,我今天在用騰訊元寶的時候,也想看一下它實時聯網更新獲取最新信息的能力。原因是大部分AI雖然現在有聯網功能,但它一般搜索的都是一些陳年消息作為參考。
當我試著搜索AI在義烏的應用時,居然搜到了上週五自己寫的文章,並且元寶還對文章內容進行了概括,我順帶試了試其他家,目前只有元寶能搜到。
這次橫測,有一種感覺,各家大模型好像在去年的百模大戰之後,就變得有些懈怠。其實作為用戶,還挺想看各家捲來捲去的,這樣就會有更好用的產品幫我「打工」。
說真的,AI產品的優勢在於持續進化的過程,沒有永遠的勝者,只有永遠的創新者。
這是一場漫長的競爭,而更好的用戶體驗是唯一不會變的法則。