被「霸道」的知網控訴侵權,秘塔AI不妨再多講幾句

作者|週一笑
郵箱|zhouyixiao@pingwest.com
編輯|王兆洋
郵箱|wangzhaoyang@pingwest.com
斷開鏈接
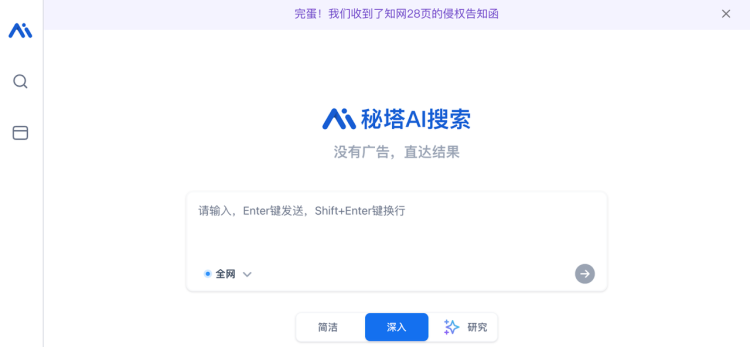
最近,秘塔AI搜索的用戶在打開網站時會發現頂端有一行醒目的文字:「完蛋!我們收到了知網28頁的侵權告知函」。
點開是秘塔的一份聲明,其表示收到《中國學術期刊(光盤版)》電子雜誌社有限公司侵權告知函——也就是此前先後因涉嫌壟斷行為和個人信息安全等問題被罰8760萬元和5000萬元而爭議不斷的知網,向它發出了侵權指控。

簡單地概括,秘塔AI搜索能搜到知網的內容,知網認為這是一種侵權行為,要求立即停止在搜索服務中提供中國知網的數據。
「我司不希望我司網站中國知網被秘塔科技搜索到,請立即斷開搜索結果到我司網站的鏈接。如需商務合作,請與我司聯繫。」
秘塔科技在這份聲明中回應,秘塔AI搜索的「學術」版塊僅收錄了論文的文獻摘要和題錄,並未收錄文章內容本身,閱讀正文需通過來源鏈接跳轉至網站獲取。而依照學術規範,文獻的摘要和題錄應具有獨立性和自明性,能夠使讀者不閱讀全文就能獲得必要的信息。

目前秘塔學術搜索的部分鏈接會跳轉到萬方數據。
秘塔AI同時強調了知識的價值在於流動,學術文獻彙集了人類智力成果的重要載體,具有極強的不可替代性。科學文獻若成為一種奢侈品,既不利於知識的公平獲取,也不利於科學研究的發展。
不過從人類智慧到學術追求談完後,秘塔給出的行動是「斷鏈」:「即使不理解,但我們也尊重知網的選擇。」從即日起,秘塔AI搜索將不再收錄知網文獻的題錄及摘要數據,轉而收錄其他中英文權威知識庫的文獻題錄及摘要數據,也歡迎其他數據庫來合作探討。
也就是秘塔最終按知網的申訴要求做了處理。
沒太說清楚的重要問題
秘塔AI搜索是這一輪AI熱潮里的明星產品,經常被比作中國的Perplexity。秘塔也是這一輪大模型創業公司里的明星公司,最新消息顯示,其完成了一億元的最新融資,投後估值1.5億美元。秘塔成立於大模型熱潮之前,但核心產品秘塔AI搜索是在今年3月正式上線。

秘塔在湖南衛視做的投放廣告
知網的侵權通知中稱秘塔向用戶提供知網的學術文獻題錄及摘要數據,涉嫌侵權。對此,上海大邦律師事務所高級合夥人、律師遊雲庭表示,網頁不同於論文,知網的學術文獻題錄及摘要網頁都是國內用戶公開可以訪問的,知網作為在中國境內中文學術文獻網絡數據庫服務市場具有支配地位的經營者,其不允許秘塔搜索抓取這兩部分公開信息需要有合理的理由。
本質上,知網是要求秘塔不要對其網站進行爬蟲。而在傳統搜索引擎的生態里,這樣的信息抓取爬蟲行為有基本的規則——各個網站和各種信息提供方通過一個Robots.txt文件來告訴搜索引擎哪些內容可以抓取,哪些不行。
而像百度、Google等搜索引擎會在這個過程中把自家的爬蟲進行命名,讓對方知道自己來過,拿走了什麼。但從知網的Robots.txt文件來看,它沒有針對任何爬蟲做屏蔽。
「有意思的是,雖然知網給秘塔發函要求斷開鏈接,也就是不允許其抓取網頁內容,但其robots文件(https://www.cnki.cn/robots.txt)卻並沒有禁止任何搜索引擎爬蟲,根據知網的robots文件內容,不禁止任何人抓取他們網頁,只是cms、query.html?*、 report、paper、qrcode、js、cs這些涉及後台管理界面、靜態資源目錄和特定內容目錄網頁不能抓取。」
又沒從行業規則上禁止對方爬取,那為何還要發告知函?
「現在很多的人工智能搜索引擎的爬蟲確實也不講武德,其不像傳統的百度、Google、搜狗、必應那樣把自家的爬蟲進行命名,而是默不作聲的匿名爬取。」遊雲庭表示。其實這些匿名爬取不一定都是以這些AI搜索公司之名展開。市面上有很多第三方的爬蟲服務,以各種方法繞開這些基本準則進行爬取。而是否使用了這些服務,在秘塔的回覆中沒有提到。
在此前Peroplexity也已遇到了類似的爭議。
當時連線雜誌和開發者Robb Knight 調查後發現,Perplexity並不遵守robots.txt 標準。而創始人Aravind Srinivas在一次採訪里回應說Perplexity 並未無視機器人排除協議(Robot Exclusions Protocol)……被調查發現有問題的網絡爬蟲屬於第三方供應商。
但被問到是否會停止使用第三方爬蟲時他只是表示「這很複雜」。此外,當時這個調查還顯示,在某些情況下,Perplexity 可能並未總結實際的文章,而是根據 URL 和搜索引擎中留下的痕跡(例如摘錄和元數據)重建內容。似曾相識。
根據秘塔發佈的文章,知網向秘塔發送的侵權通知長達28頁。秘塔僅截取了告知函發佈出來,而從發的的截圖來看,剩下的內容主要在羅列侵權的證據,這些內容可能不只是展示各種摘要和標題被爬取的情況。
根據不少用戶此前的分享,秘塔是能獲取到非公開論文的,而且,可以在秘塔的網頁直接閱讀,這些PDF文檔雖鏈接到外部文庫網站,實際可能存儲於秘塔服務器。遊雲庭認為如果秘塔建立了包含知網論文全文內容的索引庫,可能構成侵權。
「秘塔AI搜索的播客和文庫板塊是有索引庫的,我理解的索引庫可能是秘塔把批量收集的文獻事先直接在內部做了一個索引數據庫,當用戶搜索時,秘塔會搜索網絡對應的實時內容,然後利用人工智能把實時搜索結果和索引庫的內容整合在一起提供答案。」遊雲庭說。也就是雖然核心的展示結果頁面對索引以標註來源形式呈現,但同時在自己的服務里把「原文」也搬了過來。
「索引庫很可能是真實存在的,其實這個技術上也不難證明,我們代理訴訟時碰到此問題,通常用抓包軟件顯示該文檔的真實ip地址。如果這個ip地址位於秘塔的服務器,則說明是秘塔提供的。」
此外,作為使用預訓練模型為基礎的AI搜索引擎,在訓練數據里是否用到了這些有知識產權的數據,則是更重要的問題。
當訓練里的論文數據因為模型通常會存在的「過擬合」問題而導致最終給用戶輸出內容時與原文高度一致,這就從合理使用進入了類似「洗稿」的著作權侵權範疇了。
但在這樣的情況下,知網有權對這些由個體研究者們撰寫的論文「維權」麼?
「知網無權主張秘塔訓練版權侵權。」遊雲庭認為。
他表示,知網站內的多數論文雖然被收錄,但知網擁有這是雜誌社或作者授權的信息網絡傳播權,如果該論文被用於訓練,訓練涉及的版權是著作權法規定的複製權和著作權其他權利,並不侵犯知網的信息網絡傳播權。當然如果是雜誌社維權秘塔訓練侵權的,那麼秘塔將面臨《紐約時報》起訴OpenAI一模一樣的問題。

是時候多一些更嚴肅的討論
所以,秘塔們要「回應」的對像其實不只是被網民評論為「萬惡」的知網。
除了對知網作出回應——這些回應總能引發共情,從它回應文章的評論區看,人們依然是苦知網久矣的態度,紛紛「站」秘塔——秘塔們也許可以對這些訓練數據背後的個體作者講解一下這些數據的使用情況。
此次陷入爭議的「學術」搜索功能,是秘塔區別於其他Perplexity們的一個重要設計,這個功能也贏得了不少用戶的好評。這些用戶往往是一些需要為課堂作業、文章二次創作甚至寫論文等任務做大量文獻查詢的用戶。
而對於論文的真正作者們,這些數據的使用可能帶來另外的問題。
在最近Nature的一篇文章中就指出,很多學術出版商已經向科技公司授權訪問自家的論文,用來訓練AI模型。比如美國出版商Wiley允許某家公司使用其內容訓模型後,直接獲得2300萬美元收益。而這些收入與論文作者一點關係都沒有。
除了這種很可能最終也無法解決的真實收益分配問題,對於這些研究者來說,學術界本身的一些很重要的評價體系也在這種「AI學術搜索」的生成過程里被打亂。比如,學術界很重要的一個指標——引用量,在這些AI學術搜索的場景里似乎不存在了。大模型本身的隨機性和不可解釋性,以及數據的不完整性,都讓它生成的這些學術搜索結果與學術界本身的判斷標準有出入。
一名學者對矽星人表示,在這些AI搜索自己生成答案的時候,選哪個不選哪個的標準是什麼呢?對於把引用量作為最直接重要性標準的學術界,如果這些AI結果越來越多,然後也被許多研究者用在自己的論文里,這是不是也是另一種形式的AI SEO汙染?


在秘塔Law里提問展示的結果
對於這次爭議本身,當秘塔清除了索引庫中的知網論文,並不再向用戶提供知網論文的在線閱讀功能,知識產權侵權的爭議就很小了,而且遊雲庭表示,根據《反壟斷法》和《互聯網搜索引擎服務自律公約》,知網不允許秘塔搜索抓取這兩部分公開信息就不再具有合理的理由。
但如果AI搜索公司們把自己在做的產品當作一個長期和嚴肅的事,那除了圍著產品的一些小確幸進行慶祝,和一些瀟灑的態度之外,也是時候正視這些複雜而現實的問題,用合適的方式公開的討論它,只有這樣才真正有望觸及它們希望挑戰的今天信息獲取領域真正的癥結。