AI設計自己,代碼造物主已來,UBC華人一作首提ADAS,數學能力暴漲25.9%
【導讀】AI掌握自我設計的權力,將會怎樣?最近,來自UBC等機構研究人員提出了「智能體自動化設計」系統,讓元智能體使用搜索算法,自動構建強大的同類。
AI訓AI已經老生常談了,那麼,AI能夠設計出更強的AI嗎?
這不,來自UBC等機構的研究人員提出了一種全新系統——智能體自動化設計(ADAS)。

ADAS就是為了讓AI自動創建強大的智能體,包括發明新的構建模塊,或以新的方式組合它們。
具體來說,作者提出了一個「元智能體搜索」簡單而有效的算法。
其中元智能體根據不斷擴大的數據庫,迭代編程出有趣的智能體。

論文地址:https://arxiv.org/pdf/2408.08435
鑒於圖靈完備性,新方法可以學習任何可能的智能體系統,包括新提示、工具使用、控制流程,以及組合。
再加上,ADAS本身就是一個智能體,因此也可以實現自身改進,從而讓「元智能體」自我進化。

實驗證明,新系統可以讓代碼自定義智能體,而且「元智能體」可通過代碼,來設計新的智能體。
而且,由「元智能體搜索」發明的新智能體,即便在跨領域/跨模型轉移時,仍保持優越性、穩健性。
正如論文所言,這項研究展示了,一個令人興奮的新研究方向的潛力,即自動設計越來越強的智能體系統。
AI設計強大的自己,真到了那天,或許AGI就不遠了。

那麼,它是如何做到的呢?
AI自我設計,代碼造物主已來
機器學習史,指明AI方向
以往,研究人員投入了大量精力,開發強大通用智能體。
其中,基礎模型被用作智能體系統中的模塊,比如,思維鏈、自我反思、Toolformer等等。
然而,機器學習的歷史告訴我們,手動設計的解決方案,最終會被自我學習的方案所取代。
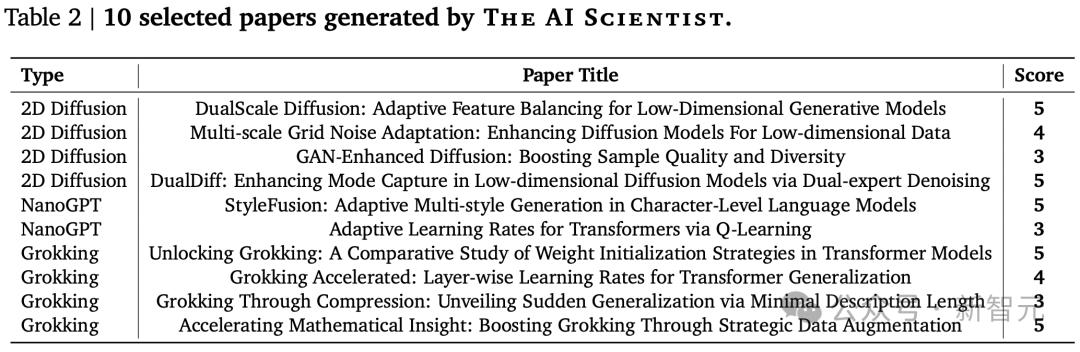
說來也巧,幾天前「AI科學家」研究也是出自Jeff Clune之手。

不列顛哥倫比亞大學CS教授,曾任OpenAI研究團隊負責人,DeepMind高級研究顧問
在上一篇研究中,展示了一個自動化研究流程,AI一口氣完成了十篇論文,部分還達到了機器學習頂會的接收的門檻。
關鍵是,AI的助力,直接將研究成本打了下來,每篇論文僅15美元。
那麼,若是讓AI設計AI,不僅省事省力,而且AI還能自我迭代。
論文中,研究團隊提出的ADAS,由三個關鍵部分組成:
– 搜索空間:定義了ADAS可以創建的所有可能的智能體系統
– 搜索算法:ADAS用來在搜索空間中尋找優秀智能體設計的方法
– 評估函數:用於判斷創建的智能體的質量或性能
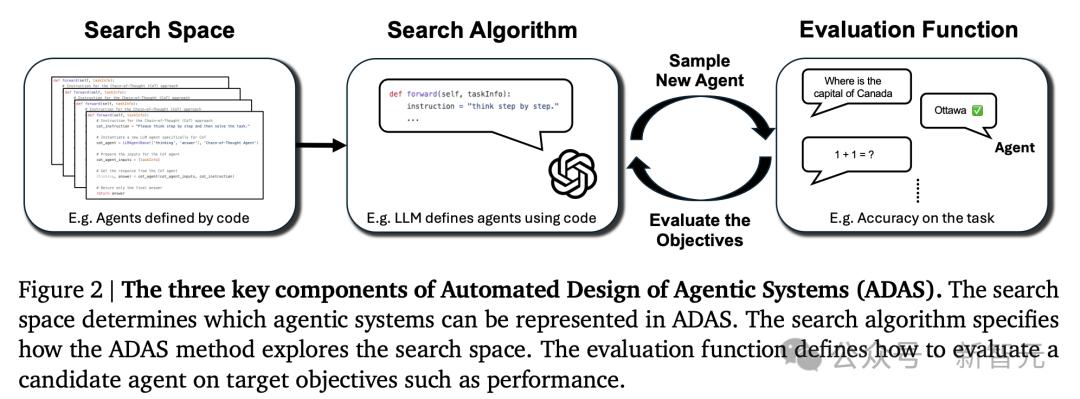
具體來說,ADAS就是涉及使用搜索算法,來發現搜索空間中的智能體系統,從而優化評估函數。

元智能體搜索
為了進一步實施想法,研究人員提出了「元智能體搜索」算法,用於演示代碼中定義和搜索智能體的方法。
元智能體搜索的核心思想是,讓基礎模型(FM)作為元智能體,根據不斷擴增的數據庫,迭代新智能體。
理論上,元智能體可以從頭開始編程任何可能的構建模塊和智能體系統。
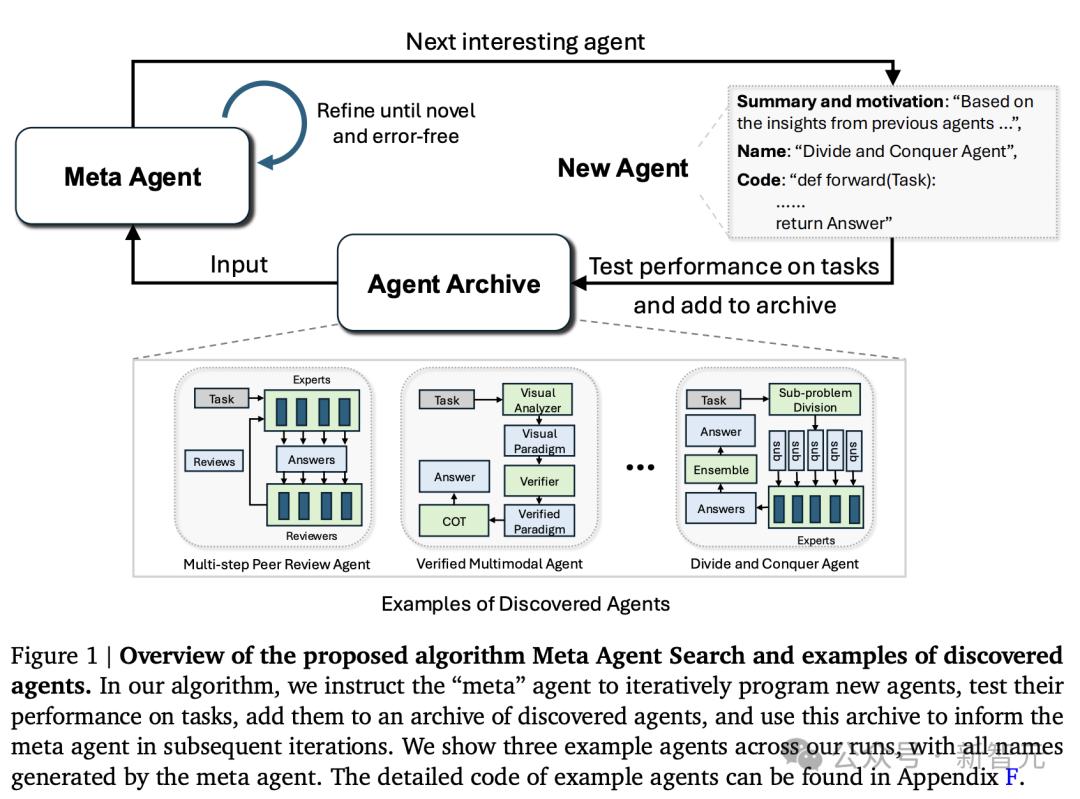
不過,在實踐中,為避免元智能體提供任何基本功能(比如FM查詢API、現有工具)是低效的。
因此,論文中,作者為元智能體定義了一個簡單的框架(100行代碼以內),為其提供了一組基本的功能,如查詢FM或格式化提示。
結果,元智能體只需要編程一個「前向」函數來定義一個新的智能體系統,類似於FunSearch中的做法。
這個函數接收任務信息,並輸出智能體對任務的響應。
如下圖所示,作者展示了元智能體編程新智能體的主要提示,其中提示中的變量,被高亮顯示。
提示中,研究人員鼓勵元智能體基於不斷增長的先前發現檔案,探索有趣的新智能體。
另外,他們還在元智能體中採用了自我反思迭代,其中它對提案的新穎性和正確性進行兩次迭代的改進,並在運行代碼時出現錯誤時進行最多三次改進。

在生成新的智能體後,研究人員決定使用目標領域的驗證數據對其進行評估。
評估結果
ARC挑戰
抽像和推理語料庫(Abstraction and Reasoning Corpus,ARC)是一個非常具有挑戰性的基準,可以通過衡量人工智能系統有效獲取新技能的能力,來評估它們的一般智力。

ARC挑戰包括3個重要步驟:
-給AI系統展示多個視覺輸入輸出網格模式的例子
-AI系統從例子中學習網格模式的轉換規則
-在給定測試輸入網格模式的情況下,預測輸出網格模式
經研究團隊驗證,元智能體搜索能夠發現新的代理系統,並在ARC挑戰中,優於SOTA人工設計智能體。
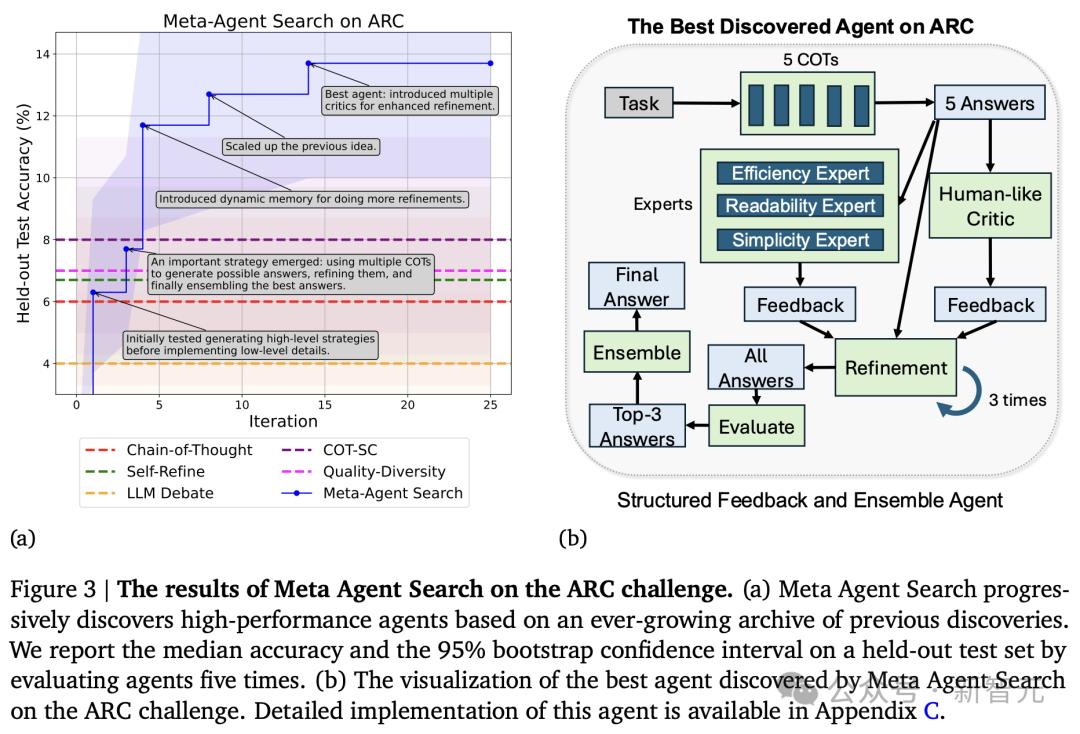
推理和問題解決
接下來,元智能體需要接受在數學、閱讀和推理領域的考驗。
用於測試的是4個常用基準:用於評估閱讀理解能力的DROP、評估多語言環境下數學能力的MGSM 、評估多任務問題解決的MMLU,以及評估在科學領域解決研究生水平問題的GPQA。
結果表明,元智能體搜索可以發現性能優於SOTA人工設計的智能體——
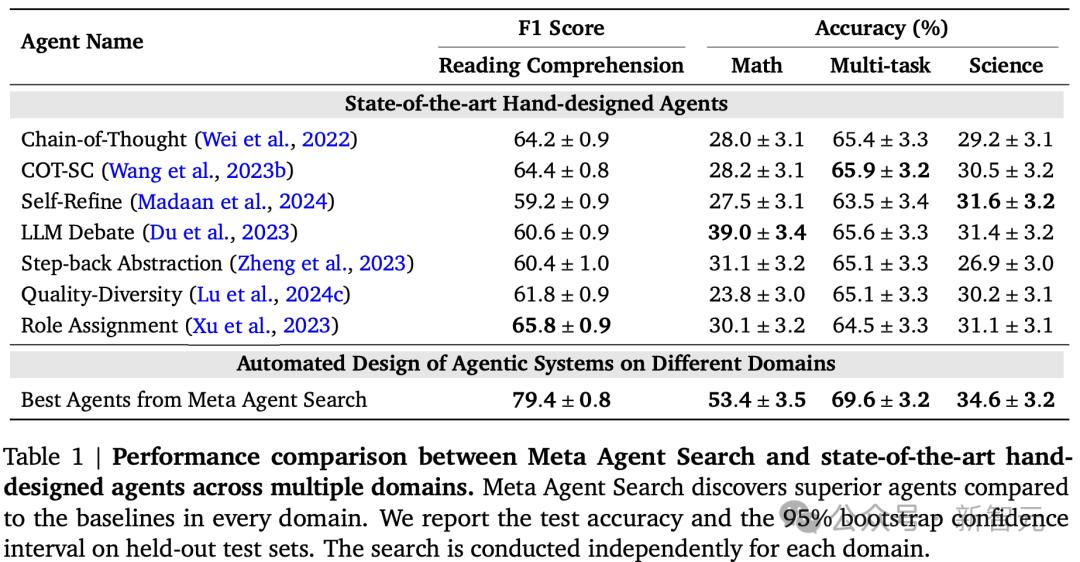
元智能體搜索和SOTA人工設計智能體的性能比較,元智能體搜索在每個領域都發現了比基線更好的智能體
不得不強調的一點是,在閱讀理解和數學領域,自我學習的智能體把人工設計的智能體遠遠甩在身後:F1分數提高了13.6/100,準確率提高了14.4%。
元智能體搜索在多任務和科學領域的表現也優於基線,但二者差距沒有這麼懸殊。
總的來說,不同領域的基準測試結果顯示出元智能體搜索在針對特定領域定製智能體方面的有效性。
泛化和可轉移性
至此,研究人員已經說明了元智能體搜索可以為各個任務找到有效的智能體,那麼,這些新發現的智能體是否具有可轉移性和可推廣性呢?
這就需要進行新的實驗。
首先將發現的代理從GPT-3.5轉移到ARC上的其他FM中,以測試在使用一個FM執行元智能體搜索時發現的代理是否可以推廣到其他FM中。
團隊選擇了三種流行的模型進行轉移,Claude-Haiku、GPT-4和Claude-Sonnet。
依然採用與在ARC挑戰和MGSM中使用的相同的基線。
如下表所示,元智能體搜索到的智能體始終優於人工設計的智能體,而且,差距不小。
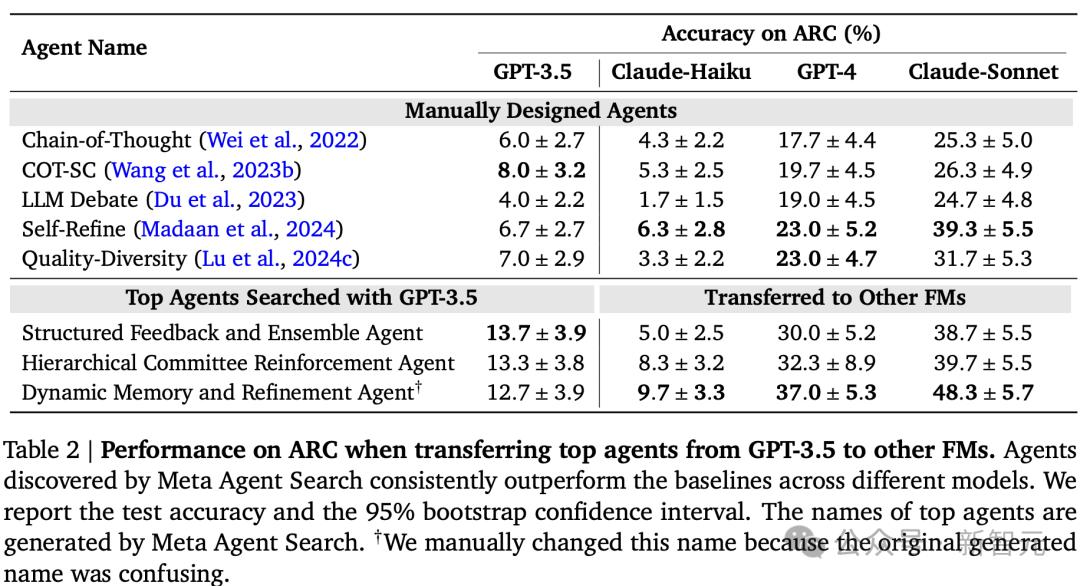
值得注意的是,Claude-Sonnet,這個 Anthropic最強大的模型,在所有測試模型中表現最好,使最好的智能體在ARC上達到近50%的準確率。
接下來,研究人員將元智能體所發現的智能體從MGSM領域轉移到其他數學領域,以測試新智能體是否可以在不同的領域進行泛化。
同樣,測試了MGSM的前3個智能體,並將它們轉移到四個流行的數學領域:GSM8K、GSM-Hard、SVAMP和ASDiv,以及在上一小節中除數學之外的三個領域。
如下表所示,與基線相比,元智能體搜索保持了性能優勢。
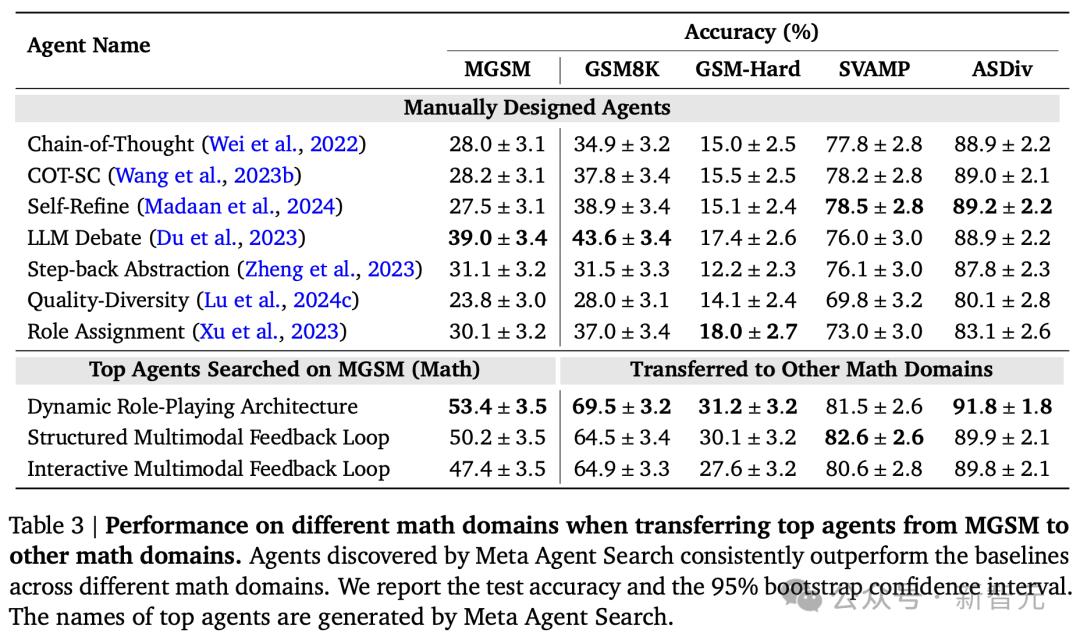
與基線相比,在GSM8K和GSM-Hard上的準確率分別提高了25.9%和13.2%。
更令人驚訝的是,在數學領域中發現的智能體可以被轉移到非數學領域。
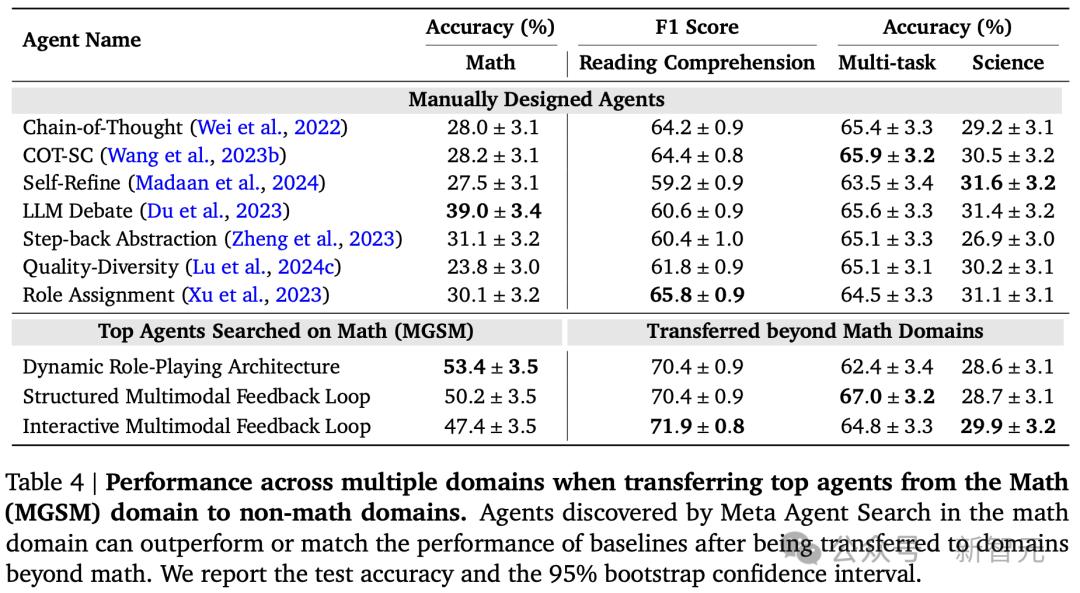
雖然最初在數學領域中搜索的智能體的性能與專門為目標領域設計的智能體並不完全匹配,但它們仍然優於(在閱讀理解和多任務中)或(在科學中)SOTA人工設計的智能體基線。
這些結果表明,元智能體搜索可以發現可推廣的設計模式和智能體系統。
作者介紹
這篇論文的一作和二作是兩位華人,Shengran Hu和Cong Lu,他們目前都在不列顛哥倫比亞大學(UBC)就讀,師從Jeff Clune。
Shengran Hu

Hu現在是UBC的一名博士生,主要研究興趣是AI智能體和開放式學習系統。
Cong Lu

Cong Lu是UBC向量學院的博士後研究員,致力於開發安全、具有好奇心並能以開放式方式學習的自主智能體。
Lu之前在牛津大學獲得了博士學位,在攻讀博士學位期間,他對離線強化學習特別感興趣,包括對未見過的任務的泛化、離線世界模型的不確定性量化、像素學習以及強化學習的擴散合成數據。
Jeff Clune

如前所述,Jeff Clune現任UBC計算機科學的教授,同時也是CIFAR AI主席、向量學院成員,DeepMind高級顧問。
值得一提的是,CIFAR(加拿大高等研究院,發音為「see-far」)自1982年成立以來不斷髮展,已從加拿大學者的一個小團體發展成為全球研究界的領導者,象徵著全球性、跨學科性和無限性。
向量學院成立於2017年,是一所非盈利研究性機構,也是加拿大政府鼎力支持的AI研究中心,人工智能教父Geoffrey Hinton當年成為了這家機構的首席科學顧問。
參考資料:
https://x.com/jeffclune/status/1825551351746867502
https://www.shengranhu.com/ADAS/
https://arxiv.org/abs/2408.08435
本文來自微信公眾號「新智元」,作者:新智元,36氪經授權發佈。