語言圖像模型大一統!Meta將Transformer和Diffusion融合,多模態AI王者登場

新智元報導
編輯:Aeneas 好睏
【新智元導讀】就在剛剛,Meta最新發佈的Transfusion,能夠訓練生成文本和圖像的統一模型了!完美融合Transformer和擴散領域之後,語言模型和圖像大一統,又近了一步。也就是說,真正的多模態AI模型,可能很快就要來了!
Transformer和Diffusion,終於有了一次出色的融合。
自此,語言模型和圖像生成大一統的時代,也就不遠了!
這背後,正是Meta最近發佈的Transfusion——一種訓練能夠生成文本和圖像模型的統一方法。
 論文地址:https://arxiv.org/abs/2408.11039
論文地址:https://arxiv.org/abs/2408.11039英偉達高級科學家Jim Fan盛讚:之前曾有很多嘗試,去統一Transformer和Diffusion,但都失去了簡潔和優雅。
現在,是時候來一次Transfusion,來重新激活這種融合了!

在X上,論文共一Chunting Zhou,為我們介紹了Transfusion其中的「玄機」。

為何它能讓我們在一個模型中,同時利用兩種方法的優勢?
這是因為,Transfusion將語言建模(下一個token預測)與擴散相結合,這樣,就可以在混合模態序列上訓練單個Transformer。
研究者從頭開始,在混合文本和圖像數據上預訓練了參數量高達70億的Transfusion模型。
使用文本和圖像數據的混合,他們建立了一系列單模態和跨模態基準的縮放定律。
實驗表明,Transfusion在單模態和多模態基準測試中,相較於對圖像進行量化並在離散圖像token上訓練語言模型,很明顯具有更好的擴展性。
研究者發現,Transfusion能夠生成與相似規模的擴散模型相媲美的高質量圖像,而且,它同時也保持了強大的文本生成能力。
作者強調,團隊著重做了建模的創新。
首先,全局因果注意力加上每個圖像內的雙向注意力,是至關重要的。
另外,引入模態特定的編碼和解碼層後,可以提高性能,並且可以將每個圖像壓縮到64甚至16個塊!
總之,研究者成功地證明了,將Transfusion方法擴展到70億參數和2萬億多模態token後,可以生成與類似規模的擴散模型和語言模型相媲美的圖像和文本。
這就充分利用了兩者的優勢!
最後,作者激動地暢想道——
Transfusion為真正的多模態AI模型開啟了激動人心的可能性。
這些模型可以無縫處理任何離散和連續模態的組合!無論是長篇影片生成、與圖像或影片的交互式編輯/生成會話,我們都可以期待了。
生圖效果秒殺DALL-E 2和Stable Diffusion
Transfusion的生圖效果如何?讓我們來檢驗一下。
以下這些,都是用在2萬億多模態token上訓練的70億參數Transfusion生成的圖像——
可以看出,它的生圖質量非常之高。
在GenEval基準測試上,它直接超越了DALL-E 2和Stable Diffusion XL!



 左右滑動查看(共四組)
左右滑動查看(共四組)


 左右滑動查看(共四組)
左右滑動查看(共四組)


 左右滑動查看(共四組)
左右滑動查看(共四組)研究者訓練了一個具有U-Net編碼/解碼層(2×2潛在像素塊)的70億參數模型,處理相當於2T tokens的數據,其中包括1T文本語料庫tokens和35億張圖像及其標註。
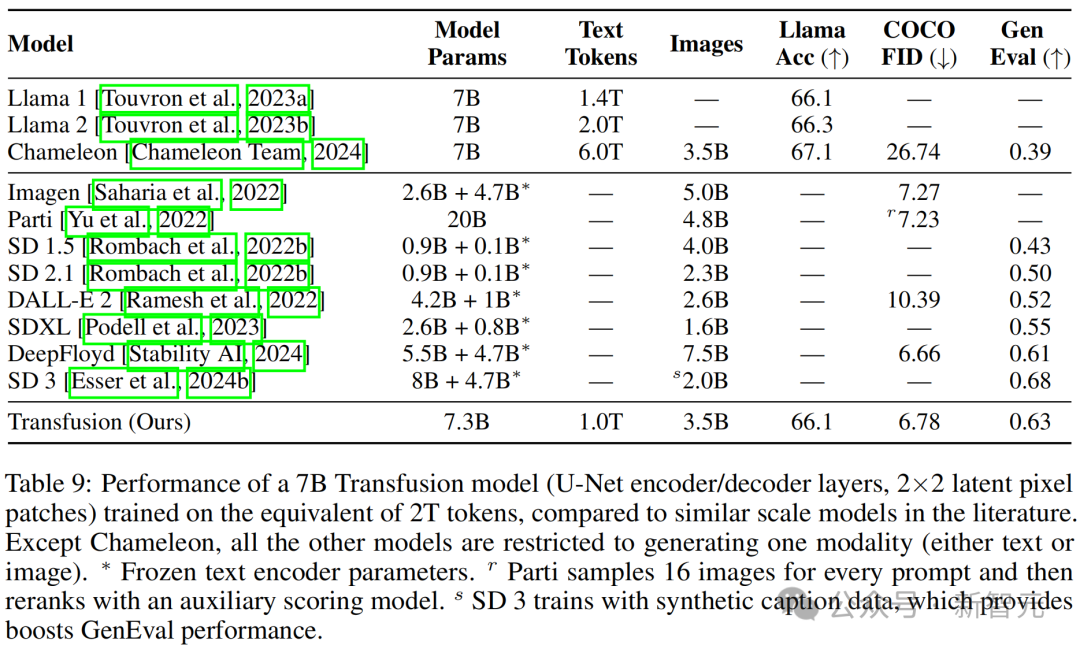
表9顯示,Transfusion在性能上與高性能圖像生成模型如DeepFloyd相當,同時超越了先前發佈的模型,包括SDXL。
雖然Transfusion在SD 3後面稍顯遜色,但該模型通過反向翻譯利用合成圖像標註,將其GenEval性能在小規模上提升了6.5%(0.433→0.498)。
此外,Transfusion模型也可以生成文本,並且其性能與在相同文本數據分佈上訓練的Llama模型相當。
圖像編輯
以下這些,則是用微調後的70億參數Transfusion模型編輯的圖像——


 左右滑動查看(共三組)
左右滑動查看(共三組)


左右滑動查看(共三組)
研究者使用僅包含8000個公開可用圖像編輯示例的數據集對70億參數模型進行了微調,其中每個示例包括一個輸入圖像、一個編輯提示詞和一個輸出圖像。
對EmuEdit測試集中隨機示例的人工檢查表明,微調的Transfusion模型可以按照指示進行圖像編輯。也就是說,Transfusion模型確實可以適應並泛化到新的模態組合。
讓語言和圖像大一統的模型來了
我們都知道,多模態生成模型需要能夠感知、處理和生成離散元素(如文本或代碼)和連續元素(例如圖像、音頻和影片數據)。
不過,離散元素和連續元素,卻很難在同一個模型中大一統起來。
在離散模態中,是語言模型佔主導地位,它靠的是在下一個token預測目標上訓練的。
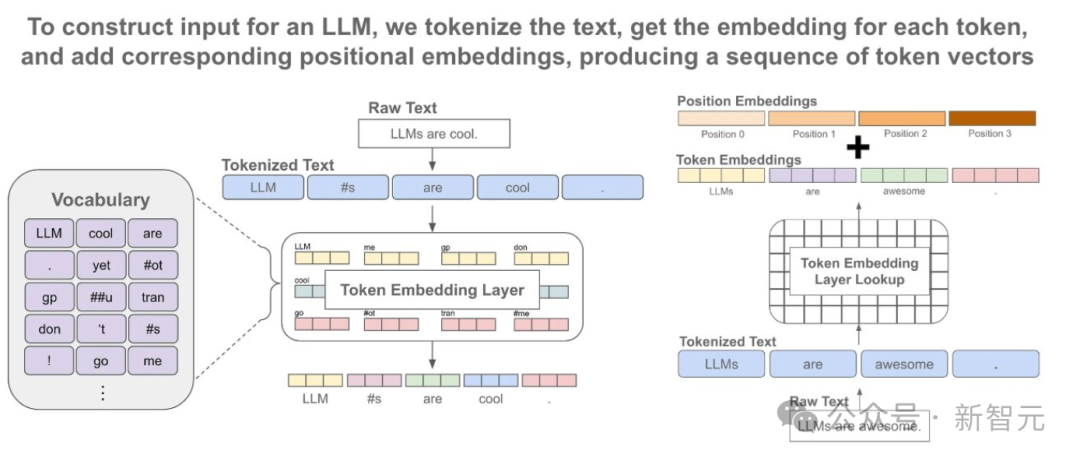
而在生成連續模態上,則是擴散模型及其泛化一直處於最前沿。
有沒有可能將二者相結合呢?
此前,學界曾嘗試了多種方法,包括擴展語言模型,以使用擴散模型作為工具,或者通過將預訓練的擴散模型移植到語言模型上。
此外,還有人通過量化連續模態,在離散tokens上訓練標準語言模型,從而簡化模型架構。然而這樣做的代價,就是信息的丟失。
而Meta的研究者在這項工作中,通過訓練單個模型,來同時預測離散文本tokens和擴散連續圖像,他們成功地做到了完全整合兩種模態,而不丟失信息。
他們的方法就是——引入Transfusion。
這是一種訓練單一統一模型的方法,可以無縫理解和生成離散和連續的模態。
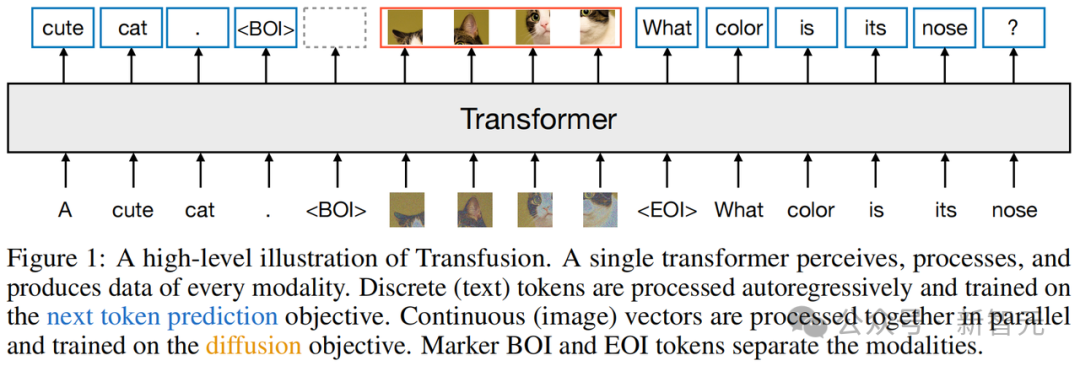
研究者的主要創新就在於,他們針對不同的模態使用了不同的損失——文本使用語言建模,圖像使用擴散——從而在共享的數據和參數上進行訓練
研究者在50%的文本和50%的圖像數據上預訓練了一個Transformer模型,不過對於兩種模態來說,分別使用了不同的目標。
前者的目標是,預測文本的下一個token;而後者的目標,則是圖像的擴散。
在每個訓練步驟中,模型都會同時接觸到這兩種模態和損失函數。標準嵌入層將文本tokens轉換為向量,而塊化層(patchification layer)則將每個圖像表徵為一系列塊向量。
隨後,研究者對文本tokens應用因果注意力,對圖像塊應用雙向注意力。
在推理時,他們引入了一種解碼算法,它結合了語言模型的文本生成和擴散模型的圖像生成的標準實踐。
從此,有望訓練真正的多模態模型
在文本到圖像生成中,研究者發現:Transfusion在計算量不到三分之一的情況下,FID和CLIP分數均超過了Chameleon的離散化方法。
在控制FLOPs的情況下,Transfusion的FID分數比Chameleon模型低約2倍。
在圖像到文本生成中,也可以觀察到類似的趨勢:Transfusion在21.8%的FLOPs下與Chameleon匹敵。
令人驚訝的是,Transfusion在學習文本到文本預測方面也更有效,在大約50%到60%的Chameleon FLOPs下實現了文本任務的困惑度平價。
同時,研究者觀察到:圖像內的雙向注意力非常重要,如果用因果注意力替代它,就會損害文本到圖像生成。
他們還發現,通過添加U-Net上下塊來編碼和解碼圖像,就可以使Transfusion在相對較小的性能損失下,壓縮更大的圖像塊,從而能將服務成本降低到多達64倍。
最後,研究者證明了:Transfusion可以生成與其他擴散模型相似質量的圖像。
他們在2萬億tokens上,從零開始訓練了一個7B參數的Transformer,它增強了U-Net的下采樣/上采樣層(0.27B參數)。
在這2萬億tokens中,包含1萬億的文本tokens,以及大約5個週期的692M圖像及標註,相當於另外1萬億個patches/tokens。
在GenEval基準上,Transfusion模型優於其他流行模型,如DALL-E 2和SDXL。
而且,與那些圖像生成模型不同的是,它還可以生成文本,在文本基準上達到了Llama 1級別的性能水平。
總之,實驗表明:Transfusion是一種十分有前途的方法,可以用於訓練真正的多模態模型。
數據表徵
研究者在兩種模態上進行了數據實驗:離散文本和連續圖像。
每個文本字符串被標記化為來自固定詞彙表的離散token序列,其中每個token被表徵為一個整數。
每個圖像被編碼為使用VAE的潛在塊,其中每個塊被表徵為一個連續向量;這些塊從左到右、從上到下排序,以從每個圖像創建一個塊向量序列。
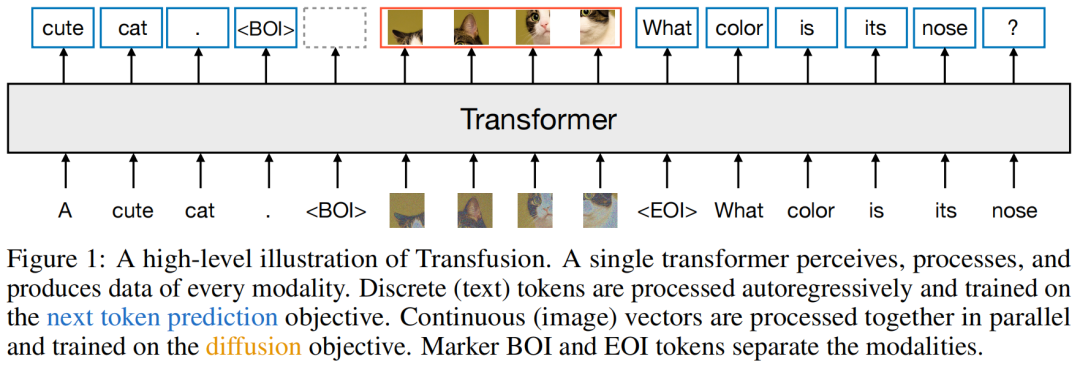
對於混合模態的例子,研究者在將圖像序列插入文本序列之前,用特殊的圖像開始(BOI)和圖像結束(EOI)token包圍每個圖像序列。
因此,就得到了一個可能同時包含離散元素(表徵文本token的整數)和連續元素(表徵圖像塊的向量)的單一序列。
模型架構
模型的大部分參數屬於一個單一的Transformer,它會處理每個序列,無論模態如何。
Transformer將一個高維向量序列作為輸入,並生成類似的向量作為輸出。
為了將數據轉換到這個空間,研究者使用了具有不共享參數的輕量級模態組件。
對於文本,這些自己組件是嵌入矩陣,會將每個輸入整數轉換為向量空間,並將每個輸出向量轉換為詞彙表上的離散分佈。
對於圖像,研究者則嘗試了兩種方法,將k×k塊向量的局部窗口壓縮為單個Transformer向量(反之亦然):(1)一個簡單的線性層,以及(2)U-Net的上下塊。
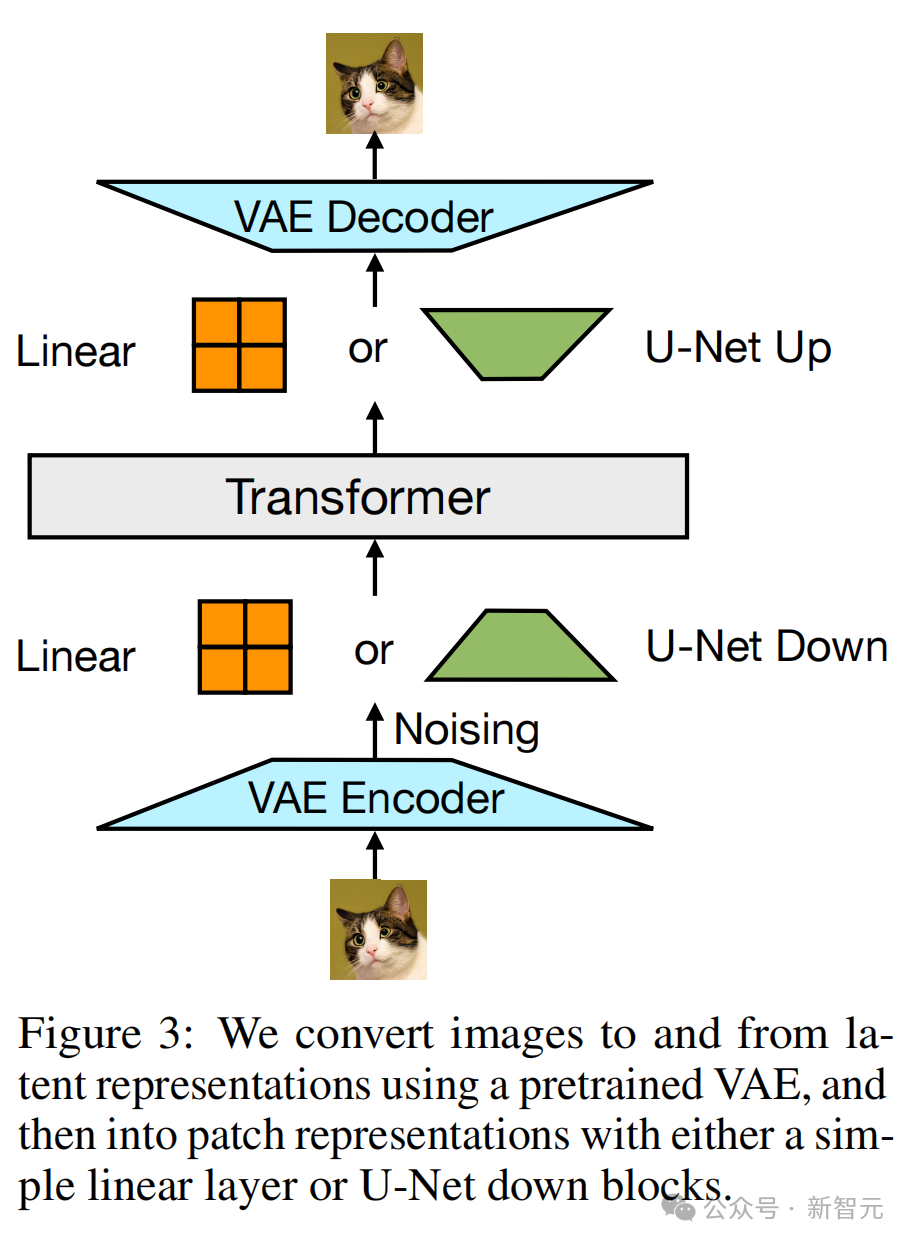
研究者使用預訓練的VAE(變分自編碼器)將圖像和潛在表徵進行互相轉換,然後通過簡單的線性層或U-Net下采樣塊,將其轉換為patch表徵
Transfusion注意力
語言模型通常使用因果掩碼,來有效地計算整個序列的損失和梯度,只需一次前向-後向傳遞,而不會泄露未來token的信息。
相比之下,圖像通常會使用不受限制的(雙向)注意力來建模。
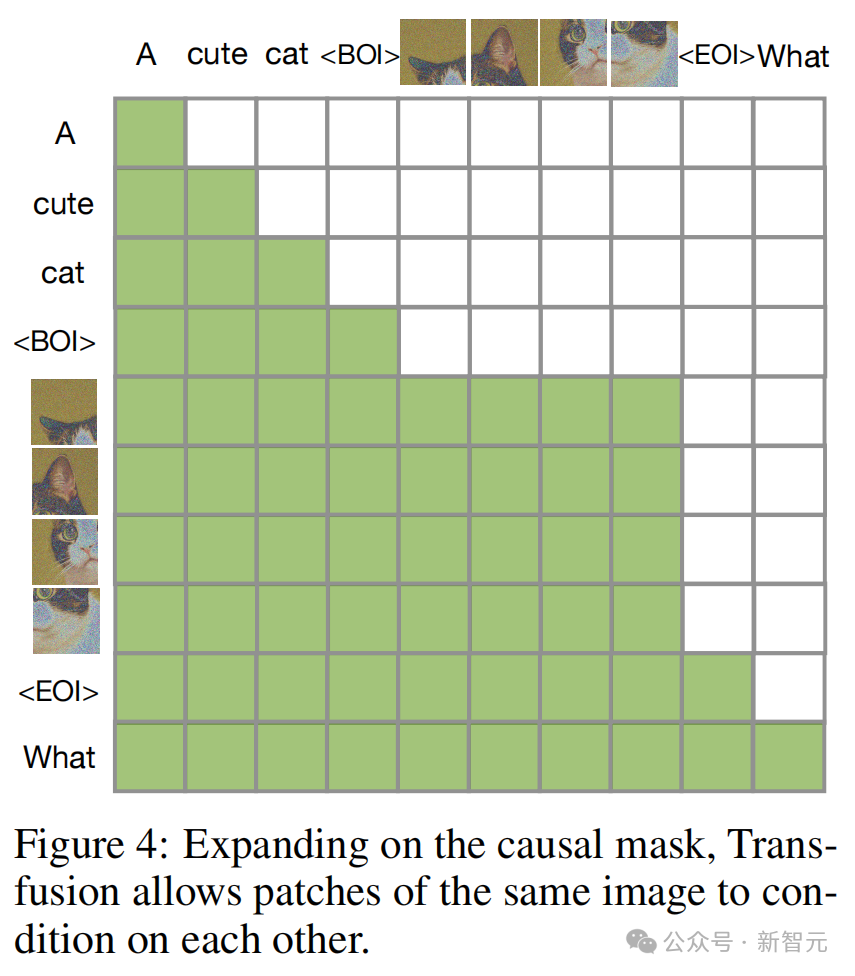
而Transfusion通過對序列中的每個元素應用因果注意力,並在每個單獨圖像的元素內應用雙向注意力,來結合這兩種注意力模式。
這樣,每個圖像塊就可以在關注同一圖像中其他塊的同時,只關注序列中先前出現的文本或其他圖像的塊。
結果顯示,啟用圖像內注意力顯著提升了模型性能。
 在因果掩碼上擴展後,Transfusion就允許同一圖像的patch相互為條件
在因果掩碼上擴展後,Transfusion就允許同一圖像的patch相互為條件訓練目標
為了訓練模型,研究者將語言建模目標LLM應用於文本token的預測,將擴散目標LDDPM應用於圖像塊的預測。
LM損失是逐個token計算的,而擴散損失是逐個圖像計算的,這可能跨越序列中的多個元素(圖像塊)。
具體來說,他們根據擴散過程,向每個輸入潛在圖像x0添加噪聲ε,以在塊化之前產生xt,然後計算圖像級別的擴散損失。
通過簡單地將每種模態上計算出的損失與平衡係數λ結合,研究者合併了這兩種損失:
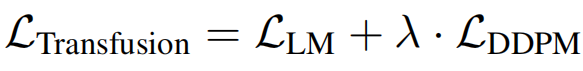
這個公式,也是一個更廣泛想法的具體實例:將離散分佈損失和連續分佈損失結合,就可以優化同一模型。
推理
為了反映訓練目標,解碼算法也需要在兩種模式之間切換:LM和擴散。
在LM模式中,從預測分佈中逐個token進行采樣。當采樣到一個BOI token時,解碼算法切換到擴散模式。
具體來說,這需要將形式為n個圖像塊的純噪聲xT附加到輸入序列中(取決於所需的圖像大小),並在T步內去噪。
在每一步t中,噪聲會被預測並使用它生成x_(t−1),然後將其覆蓋在序列中的x_t上。即,模型始終基於噪聲圖像的最後一個時間步進行條件處理,無法關注之前的時間步。
一旦擴散過程結束,就將一個EOI token附加到預測的圖像上,並切換回LM模式。
如此一來,就可以生成任意混合的文本和圖像模態。
實驗
與Chameleon的比較
研究者在不同模型規模(N)和token計數(D)下,比較了Transfusion與Chameleon,並使用兩者的組合作為FLOPs(6ND)的代理。
為了簡化和參數控制,這些實驗中的Transfusion變體使用簡單的線性圖像編碼器/解碼器,塊大小為2×2,以及雙向注意力。
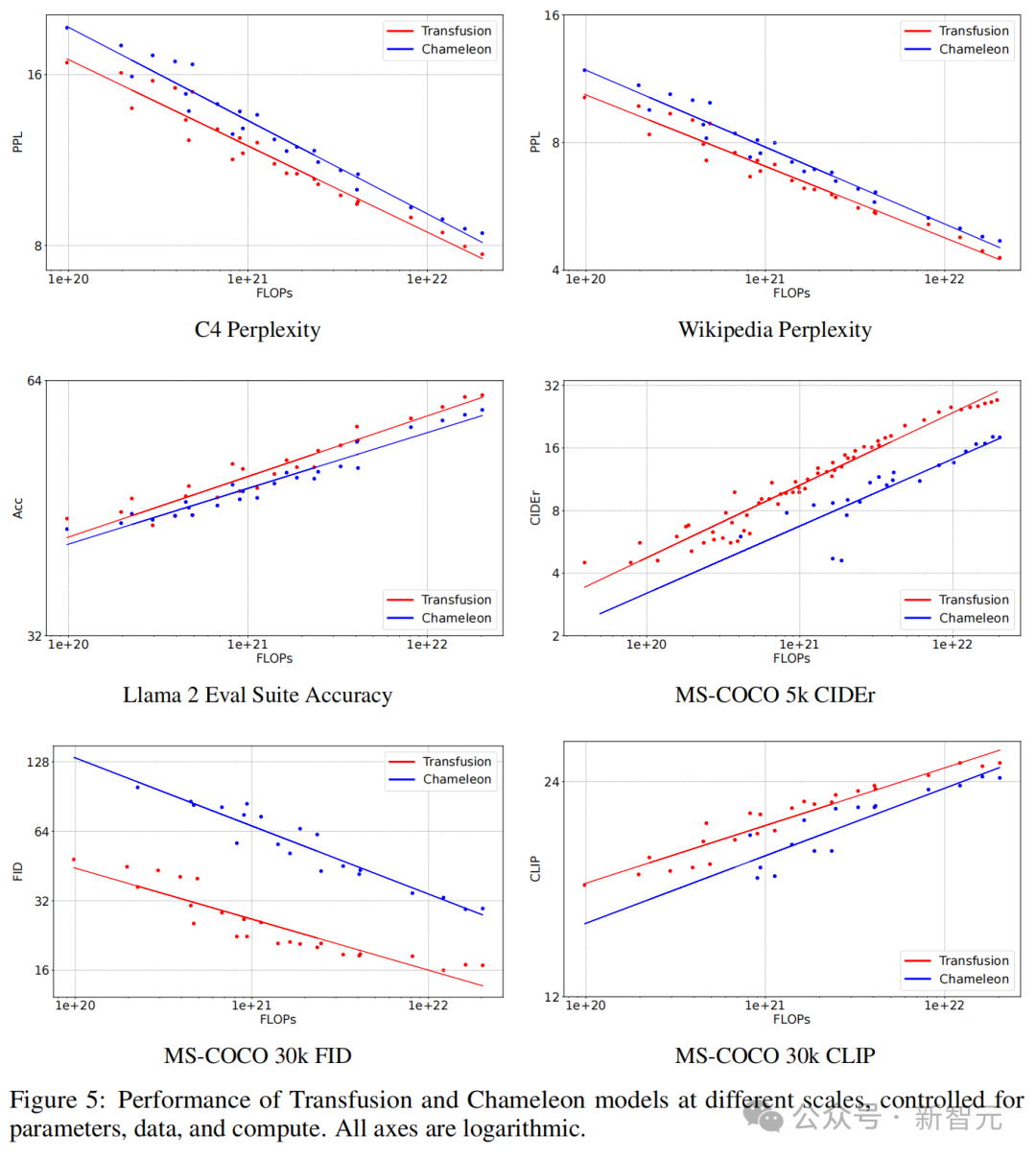
如圖5所示,在每個基準測試中,Transfusion始終表現出比Chameleon更好的scaling law。
受參數、數據和計算控制的不同規模的Transfusion和Chameleon模型的性能,其中所有軸都是對數的表3則顯示了模型的評估結果,以及平價FLOP比率。
其中,平價FLOP比率用來估算相對計算效率:Transfusion和Chameleon達到相同性能水平所需的FLOPs數量之比。
計算效率的差異在圖像生成中特別顯著,其中FID Transfusion以1/34的計算量實現了與Chameleon的平價。
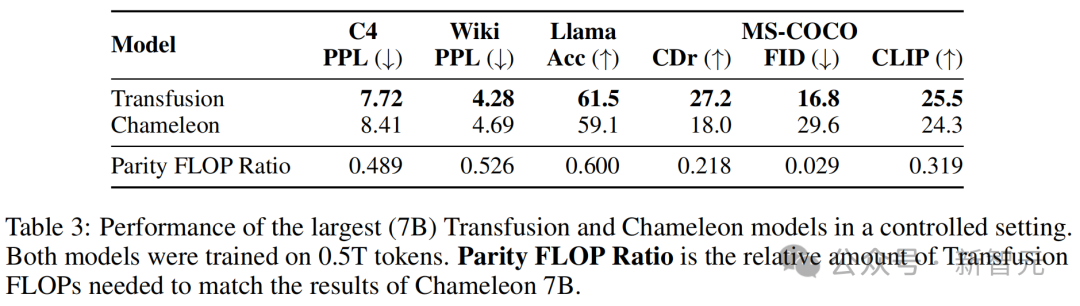 最大(7B)Transfusion和Chameleon模型在受控環境中的性能,兩個模型均在0.5T token上進行訓練
最大(7B)Transfusion和Chameleon模型在受控環境中的性能,兩個模型均在0.5T token上進行訓練令人驚訝的是,純文本基準測試也顯示出Transfusion的更好性能,即使Transfusion和Chameleon以相同方式建模文本。
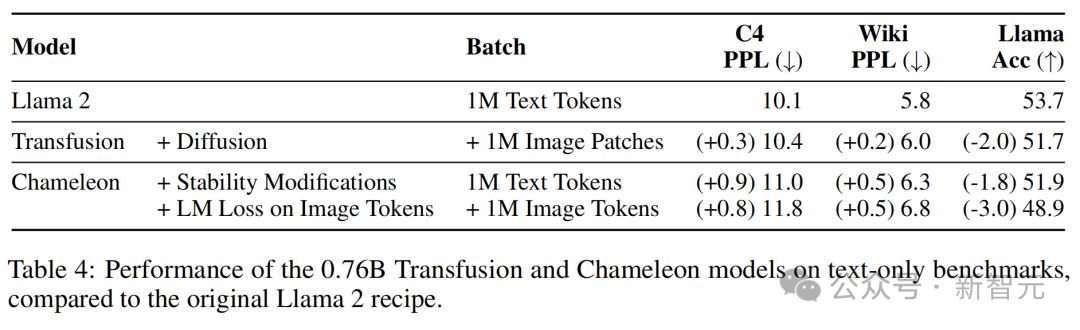 與原始Llama 2配方相比,0.76B Transfusion和Chameleon模型在純文本基準上的性能
與原始Llama 2配方相比,0.76B Transfusion和Chameleon模型在純文本基準上的性能架構消融
– 注意力掩碼
表5顯示,在所有基準測試中,啟用這種注意力模式比標準因果注意力效果更好,並且在使用圖像編碼/解碼架構時也是如此。特別是,在使用線性編碼層時,FID的改善最為顯著(61.3→20.3)。
在僅因果的架構中,序列中後出現的塊不會向前面的塊傳遞信息;由於U-Net塊內含有雙向注意力,並獨立於Transformer的注意力掩碼,因此這種差距不太明顯。
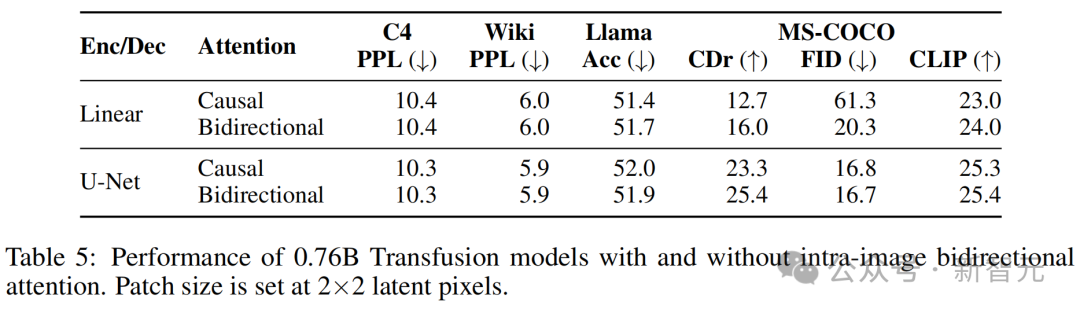 有/無圖像內雙向注意力的0.76B Transfusion模型的性能
有/無圖像內雙向注意力的0.76B Transfusion模型的性能– 塊大小
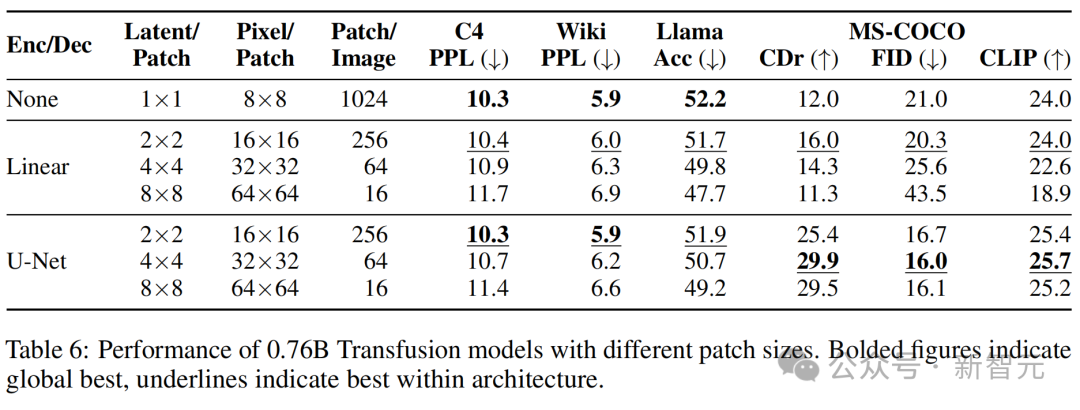
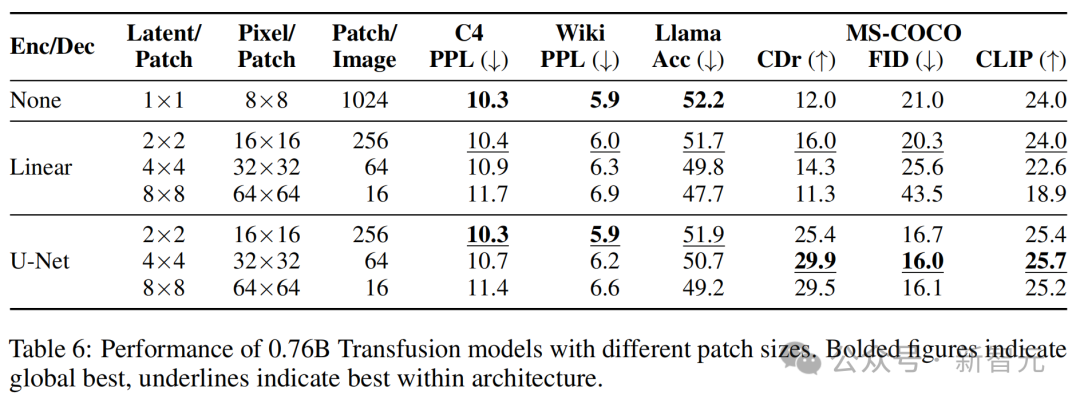
Transfusion模型可以在不同尺寸的潛在像素塊上定義。較大的塊大小允許模型在每個訓練批次中打包更多圖像,並顯著減少推理計算量,但可能會帶來性能損失。
表6顯示,雖然隨著每個圖像由更少的線性編碼塊表徵,性能確實一致下降,但使用U-Net編碼的模型在涉及圖像模態的任務中受益於較大的塊。
這可能是因為訓練期間看到的總圖像(和擴散噪聲)數量更大。
此外,隨著塊逐漸變大,文本性能也在變差。
這可能是因為Transfusion需要投入更多資源(即參數)來學習如何處理具有較少塊的圖像,從而減少推理計算。
– 塊編碼/解碼架構
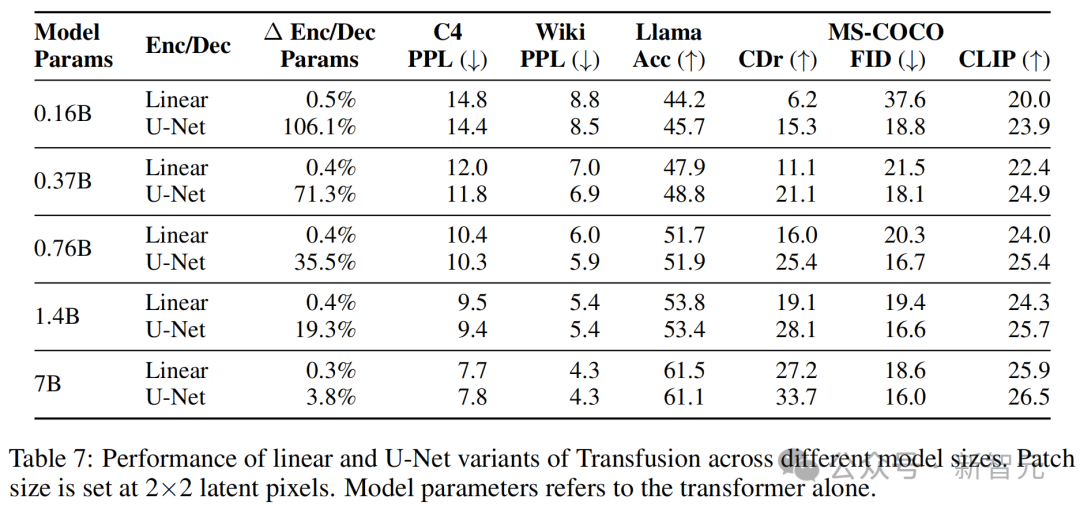
實驗表明,使用U-Net的上升和下降塊比使用簡單的線性層有優勢。
一個可能的原因是模型受益於U-Net架構的歸納偏置;另一種假設是,這種優勢來自於U-Net層引入的整體模型參數的顯著增加。
為了分離這兩個混雜因素,研究者將核心Transformer擴展到70億個參數,同時保持U-Net參數量(幾乎)不變;在這種設置下,額外的編碼器/解碼器參數僅佔總模型參數的3.8%增加,相當於token嵌入參數的量。
表7顯示,儘管隨著Transformer的增長,U-Net層的相對優勢縮小,但並未消失。
例如,在圖像生成中,U-Net編碼器/解碼器使得較小的模型能夠獲得比使用線性塊化層的70億模型更好的FID分數。
在圖像描述中,也有類似的趨勢——添加U-Net層讓1.4B Transformer(總計1.67B)的CIDEr得分超過了線性70億模型的性能。
總體而言,U-Net對圖像的編碼和解碼確實具有歸納偏置的優勢。
 Transfusion的線性和U-Net變體在不同模型大小上的性能
Transfusion的線性和U-Net變體在不同模型大小上的性能– 圖像加噪
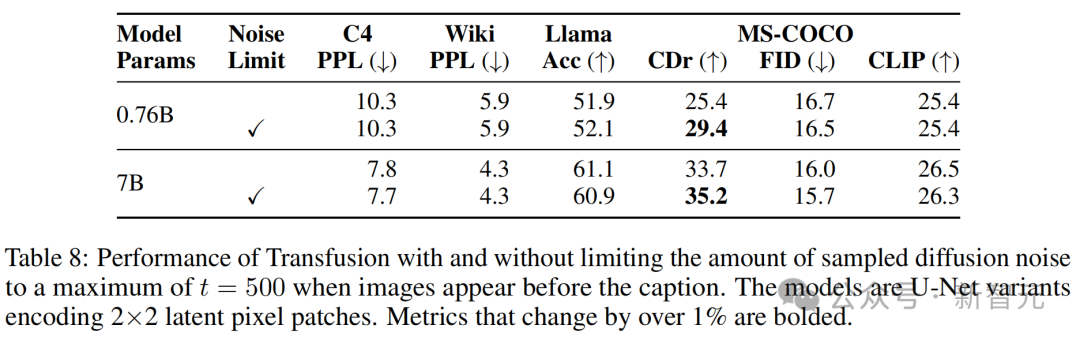
實驗中,80%的圖像-標註對按照標註優先的順序排列,圖像依賴於標註,這基於圖像生成可能比圖像理解更需要數據的直覺。剩下的20%對則是標註依賴於圖像。
然而,這些圖像需要作為擴散目標的一部分被加噪。
為此,研究者測量了在20%的情況下限制擴散噪聲到最大t=500,即圖像在標註之前出現時的效果。
表8顯示,限制噪聲顯著改善了圖像描述,CIDEr得分顯著提高,同時對其他基準測試的影響相對較小(小於1%)。
結論
這項研究探討了如何彌合離散序列建模(下一個token預測)與連續媒體生成(擴散)之間的差距。
研究者提出了一個簡單但以前未被探索的解決方案:在兩個目標上訓練一個聯合模型,將每種模態與其偏好的目標聯繫起來。
實驗表明,Transfusion可以有效擴展,幾乎沒有參數共享成本,同時能夠生成任何模態。
作者介紹
Chunting Zhou

共同一作Chunting Zhou,是Meta AI的研究科學家,研究興趣是高效且可擴展的生成模型。

她於2022年在卡耐基梅隆大學計算機科學學院的語言技術研究所獲得博士學位,從事的是自然語言處理的研究。
此前,她於2016年在香港大學獲得計算機科學碩士學位,於2014年在大連理工大學獲得計算機軟件工程學士學位。

Lili Yu

另一位共同一作Lili Yu,也是Meta AI的研究科學家。
她於2016年在麻省理工學院獲得電氣工程與計算機科學博士學位,於2011年在北京大學獲得物理學學士學位。

Xuezhe Ma

在這篇論文中,還有一位華人作者Xuezhe Ma,是南加州大學信息科學研究所的研究主管和計算機科學系的研究助理教授。
原則上,表徵學習可以自動學習在數學和計算上便於處理的表徵。對此Xuezhe Ma認為,基於深度學習方法的表徵學習技術可以從根本上改變傳統的特徵設計範式。
他的研究重點是通過開發和分析深度學習技術來實現這一轉變,以提高表徵學習的有效性、效率、可解釋性和魯棒性。主要貢獻如下:
– 多模態大語言模型(LLMs)的效率
開發了高效的統一神經架構和學習算法,以學習各種數據模態的通用語義空間。
– 大語言模型中的高效且魯棒的長上下文建模
開發了高效且魯棒的架構和方法,用於在大語言模型中建模長程依賴關係。
– 多模態大語言模型在長序列數據中的應用和評估方法
將長上下文大語言模型應用於實際任務,並開發可靠的評估指標。

他在卡耐基梅隆大學語言技術研究所獲得博士學位,師從Eduard Hovy教授,並在上海交通大學獲得了計算機科學碩士和學士學位。
 參考資料:
參考資料:https://the-decoder.com/metas-transfusion-blends-language-models-and-image-generation-into-one-unified-model/
https://x.com/violet_zct/status/1826243212530610389
https://x.com/DrJimFan/status/1827116592951652823