牛津光計算論文登Nature正刊,分析帕金森患者步態準確率達92.2%
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文第一作者為牛津大學 Harish Bhaskaran 院士課題組董博維博士。Harish Bhaskaran 院士課題組的多名科研人員 2022 年在國內聯合創立光計算芯片公司光本位科技,該公司在今年7月份的世界人工智能大會上宣佈所研發的 128*128 矩陣規模光計算芯片算力密度和算力精度達到商用標準,董博維博士目前已與該公司建立合作關係,從光源、相變材料、矽光互聯架構等多維度共同推進光子存算在人工智能領域的商業化落地。
光計算時代或許正在加速到來。
隨著人工智能等技術對算力的需求日益增長,而傳統電子計算的算力供給能力與人工智能產生的算力需求之間存在失配,這促使人們尋找新的算力增長點。
光計算具有高並行度、高能效比和高速度的特點,在構建大規模矩陣-矩陣並行計算系統時具有巨大優勢。近年來,光計算領域湧現出許多研究成果和進展。
近日,牛津大學 Harish Bhaskaran 院士課題組董博維博士等研究人員在《Nature》正刊上發表論文「部分相干光可增強並行光計算」。

-
論文鏈接:https://www.nature.com/articles/s41586-024-07590-y
-
論文標題:Partial coherence enhances parallelized photonic computing
在論文中,他們證明了,降低光學相乾性能夠增強光子卷積處理。他們展示了一種利用降低的時間相乾性(即部分相干係統)的光子卷積處理系統,以在不顯著犧牲準確度的情況下提高處理並行性,並有可能實現大規模光子張量核。
這種方法消除了對眾多移相器或 MRR 的精確控制的需求,並通過使用部分相干光源減輕了對嚴格反饋控制和熱管理的要求。
研究者在兩個用於計算應用的光子平台中展示了部分相干處理的廣泛適用性:首先,他們使用相變材料光子存儲器,通過 3×3 光子張量核進行並行卷積處理,對十名帕金森病患者的步態進行分類,實現了 92.2% 的準確率。其次,他們使用帶有嵌入式 EAM 的 9×3 矽光子張量核實現了高速 0.108 TOPS 卷積處理器,用於矢量編碼和權重設置,並結合片上光電探測器對 MNIST 手寫數字數據集進行分類,準確率達到 92.4%。
光計算將加速人工智能新變革
光計算大多通過芯片作為載體,在光芯片上實現。光芯片指的是在用成熟 CMOS 電芯片工藝節點(180nm、130nm、90nm)改造而成的矽基光電子工藝下流片的芯片,可以運用在通信、傳感和計算上。光通信領域,各大光通信廠商都已開始全面將設備芯片化,如將光開關集成到矽光芯片上,使得面積和功耗都下降 10-100 倍;傳感領域,激光雷達廠商正在積極推動將固態雷達設備用矽光芯片替代,以縮小面積和降低成本;而計算是對矽光芯片工藝要求更高、調製更複雜的領域,技術上集成了通信、傳感的先進工程化經驗,也面向更龐大的人工智能市場。
光計算芯片是為人工智能而生。從理論基礎上,光計算芯片天然適配於做並行、大規模的線性運算,而線性運算是當今世界所有主流人工智能算法的基石。從產業結構上,人工智能天然需要用大規模、大算力、安全可控的算力集群來完成生產力的躍遷,而在產生大量算力的同時,能耗控制決定了算力集群的效率和成本。光計算芯片提供了一個超大算力、超低能耗的算力集群的發展路線。在人工智能眾多新興領域里,光計算芯片天然適配於大模型、自動駕駛、具身智能等。
大模型的訓練和推理需要大量的算力,光計算芯片可以極大降低大模型所需硬件的固定成本和使用成本。在固定成本方面,光計算芯片造價成本低,且無需先進製程流片。在使用成本方面,光計算芯片能效比極高,同樣算力下耗電量僅為電芯片的 1/100。可以說,光計算芯片是最適合於大模型未來發展的算力核心硬件。
自動駕駛在從 L3 至 L5 的發展過程中,算力需求會從每輛車 300TOPS 激增到 2000TOPS,在現有自動駕駛電芯片的能耗條件下,L5 所需求的算力會帶來超過千瓦的耗電量,目前的電池是難以持續支撐的。光計算芯片提供了一個在大算力前提下不產生大功耗的解決方案,從而保證了新能源汽車在 L5 全自動駕駛下依然有出色的續航表現。
具身智能系統要實現與人類互動並完成多樣化指令要求,決策層的多模態處理不可或缺。作為具身智能的實體之一,智能機器人的強化學習和模型訓練方面需要強大的算力支持。光計算芯片具備的高速率、低延遲、高並行能力、低能耗、不易受干擾等特性,能夠為具身智能系統的技術發展和產業化應用提供重要基礎支撐。
大規模光計算芯片調控成本高
光計算芯片可以解決大模型、自動駕駛、具身智能的痛點,但由於光的樸達性需要複雜調控,實現大規模光計算芯片一直是個難題。
大規模光計算芯片需使用多個激光光源,每個激光的波長和相位需要精準調控。同時,光信號處理硬件也需要實現對波長和相位的精準調控。這類似往水池中的不同位置同時丟下多個石塊,並要求在特定的觀測點能夠觀測到固定的水紋。所需精準調控雖然理論上可行,但調控複雜,且需要巨大的調控成本,限制了光計算芯片的大型化發展。
過去的一個世紀內,科學家們專注於實現對光源波長和相位的精準控制,提升光學相乾性(圖 1)。使用高相乾性激光是實現新興光應用的基本思路,包括光計算。已展示的光計算系統皆使用高品質激光作為光源。
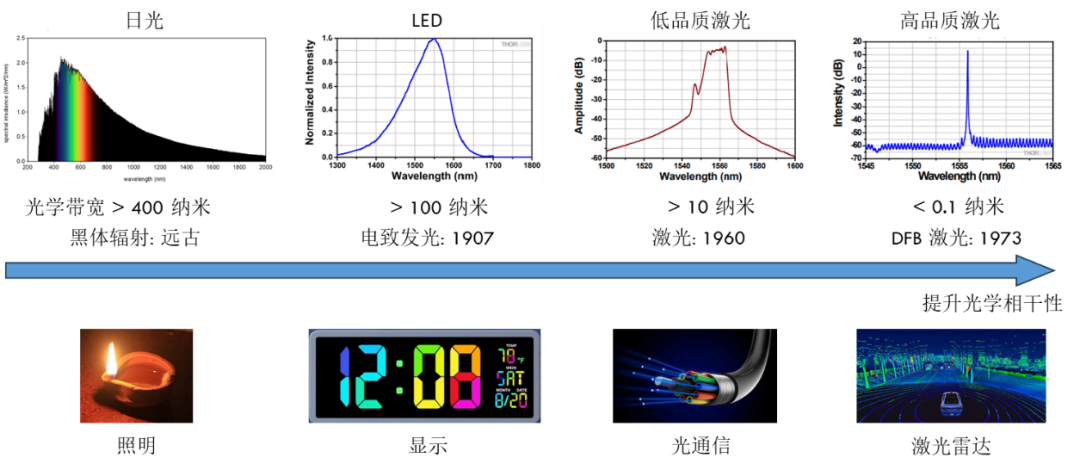
圖 1: 高光學相乾性加速新興光應用的發展。圖源:董博維.
部分相干光可增強並行光計算
近日發表在《Nature》上的工作打破了使用高品質相干光這一思維慣性,反常規地探究了降低光源相乾性對光計算芯片的影響,展示了低品質光源可提高光計算性能。牛津大學 Harish Bhaskaran 院士(英國皇家工程院院士)課題組董博維博士等研究人員,展示了使用單一光源即可運行大規模光計算芯片,無需複雜的光源及片上波長、相位調控。
研究人員發現,通過降低光源的品質,打破光源的相乾性,可以有效消除光計算芯片中的相位噪聲問題,避免複雜的系統相位調控,同時通過提升帶寬利用率大幅提高系統算力。
研究人員在存內光計算芯片和電吸收調製器陣列光計算芯片兩個平台內展示了這一新方法的優越性。與現有技術相比,這項新技術有望將光芯片算力提升兩個數量級,且通過降低系統控制複雜度大幅降低系統能耗。
打破光源相乾性,消除相位敏感性
通過降低光源相乾性,使用部分相干光源,相位敏感性可被徹底消除,一個窄帶部分相干光即可應對多個輸入通道。這一方法解耦了波長數量與輸入通道數量的關聯性。
假設光計算芯片的工作帶寬為 80nm,部分相干光的線寬為 0.8nm,此時輸入通道數可為任意大小,且計算並行度可為固定的數值 100,從而提供比傳統相干光源光計算系統高 100 倍的算力。
研究人員通過實驗驗證了這一假設。如圖 2 所示,在光計算系統中,若在多輸入通道中使用單一激光,會發生明顯的由干涉引起的強度擾動,影響計算結果(圖 2b)。若使用單一部分相干光,可觀測到強度擾動被徹底消除,得到穩定的計算結果(圖 2c)。
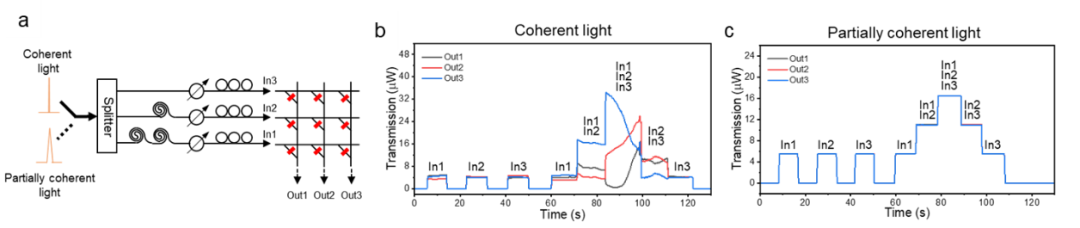
圖 2: 部分相干光徹底消除干涉引起的光強擾動,使單一光源對應任意大小的光計算芯片成為可能。圖源:Nature.
更多細節,請參考原論文。