擊敗 Meta,阿里 Qwen2.5 再登全球開源大模型王座
9 月 19 日雲棲大會,阿里雲 CTO 周靖人發佈通義千問新一代開源模型 Qwen2.5,旗艦模型 Qwen2.5-72B 性能超越 Llama 405B,再登全球開源大模型王座。Qwen2.5 全系列涵蓋多個尺寸的大語言模型、多模態模型、數學模型和代碼模型,每個尺寸都有基礎版本、指令跟隨版本、量化版本,總計上架 100 多個模型,刷新業界紀錄。
Qwen2.5 全系列模型都在 18T tokens 數據上進行預訓練,相比 Qwen2,整體性能提升 18% 以上,擁有更多的知識、更強的編程和數學能力。Qwen2.5-72B 模型在 MMLU-rudex 基準(考察通用知識)、MBPP 基準(考察代碼能力)和 MATH 基準(考察數學能力)的得分高達 86.8、88.2、83.1。
Qwen2.5 支持高達 128K 的上下文長度,可生成最多 8K 內容。模型擁有強大的多語言能力,支持中文、英文、法文、西班牙文、俄文、日文、越南文、阿拉伯文等 29 種以上語言。模型能夠絲滑響應多樣化的系統提示,實現角色扮演和聊天機器人等任務。在指令跟隨、理解結構化數據(如表格)、生成結構化輸出(尤其是 JSON)等方面 Qwen2.5 都進步明顯。
語言模型方面,Qwen2.5 開源了 7 個尺寸,0.5B、1.5B、3B、7B、14B、32B、72B,它們在同等參數賽道都創造了業界最佳成績,型號設定充分考慮下遊場景的不同需求,3B 是適配手機等端側設備的黃金尺寸;32B 是最受開發者期待的「性價比之王」,可在性能和功耗之間獲得最佳平衡,Qwen2.5-32B 的整體表現超越了 Qwen2-72B。
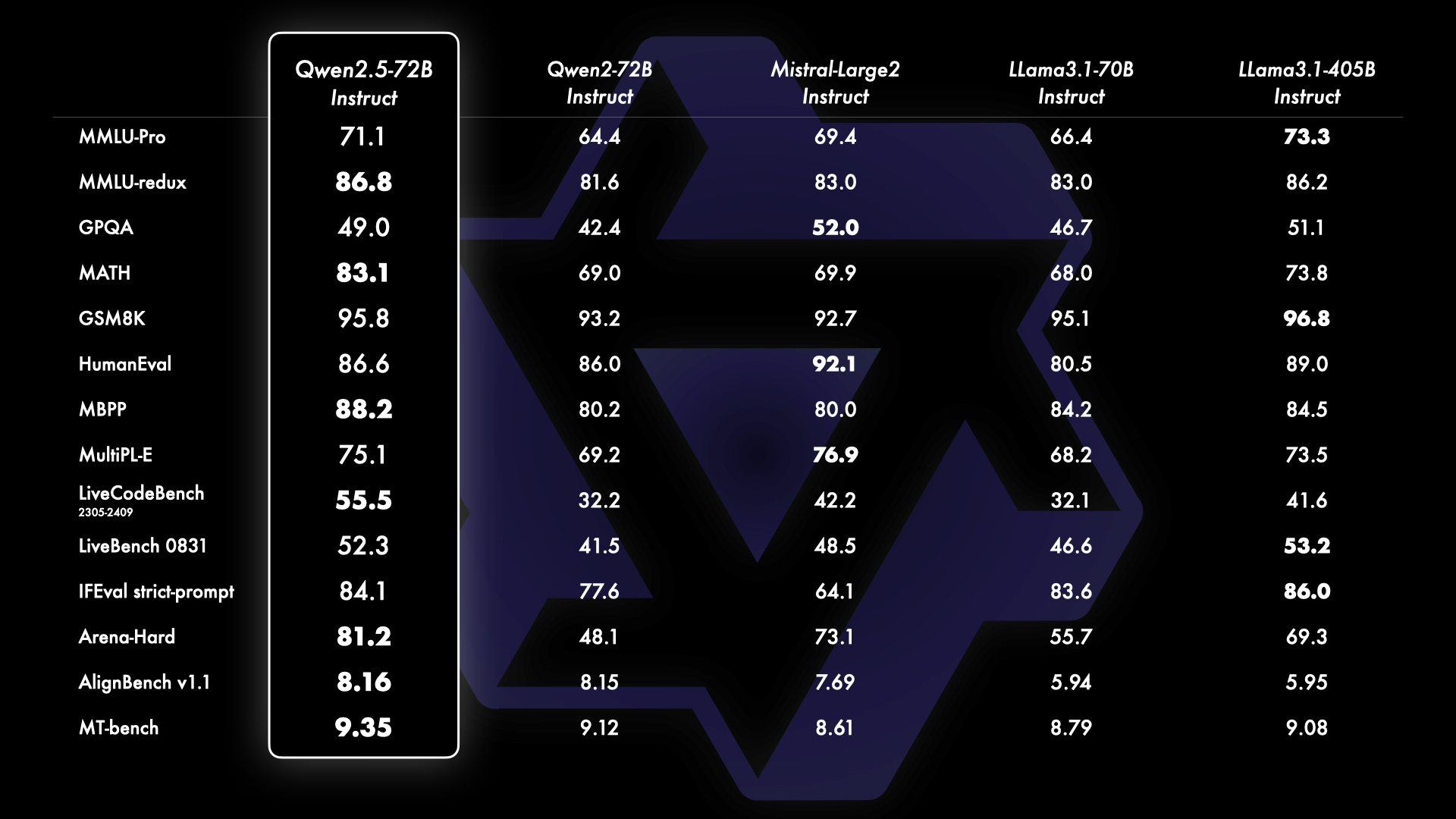 在 MMLU-redux 等十多個基準測評中,Qwen2.5-72B 表現超越 Llama3.1-405B
在 MMLU-redux 等十多個基準測評中,Qwen2.5-72B 表現超越 Llama3.1-405B72B 是 Qwen2.5 系列的旗艦模型,其指令跟隨版本 Qwen2.5-72B-Instruct 在 MMLU-redux、MATH、MBPP、LiveCodeBench、Arena-Hard、AlignBench、MT-Bench、MultiPL-E 等權威測評中表現出色,在多個核心任務上,以不到 1/5 的參數超越了擁有 4050 億巨量參數的 Llama3.1-405B,繼續穩居「全球最強開源大模型」的位置。
專項模型方面,用於編程的 Qwen2.5-Coder 和用於數學的 Qwen2.5-Math 都比前代有了實質性進步。Qwen2.5-Coder 在多達 5.5T tokens 的編程相關數據上作了訓練,當天開源 1.5B 和 7B 版本,未來還將開源 32B 版本;Qwen2.5-Math 支持使用思維鏈和工具集成推理(TIR)解決中英雙語的數學題,是迄今為止最先進的開源數學模型系列,本次開源了 1.5B、7B、72B 三個尺寸和一款數學獎勵模型 Qwen2.5-Math-RM。
多模態模型方面,廣受期待的視覺語言模型 Qwen2-VL-72B 正式開源,Qwen2-VL 能識別不同解像度和長寬比的圖片,理解 20 分鐘以上長影片,具備自主操作手機和機器人的視覺智能體能力。日前權威測評 LMSYS Chatbot Arena Leaderboard 發佈最新一期的視覺模型性能測評結果,Qwen2-VL-72B 成為全球得分最高的開源模型。
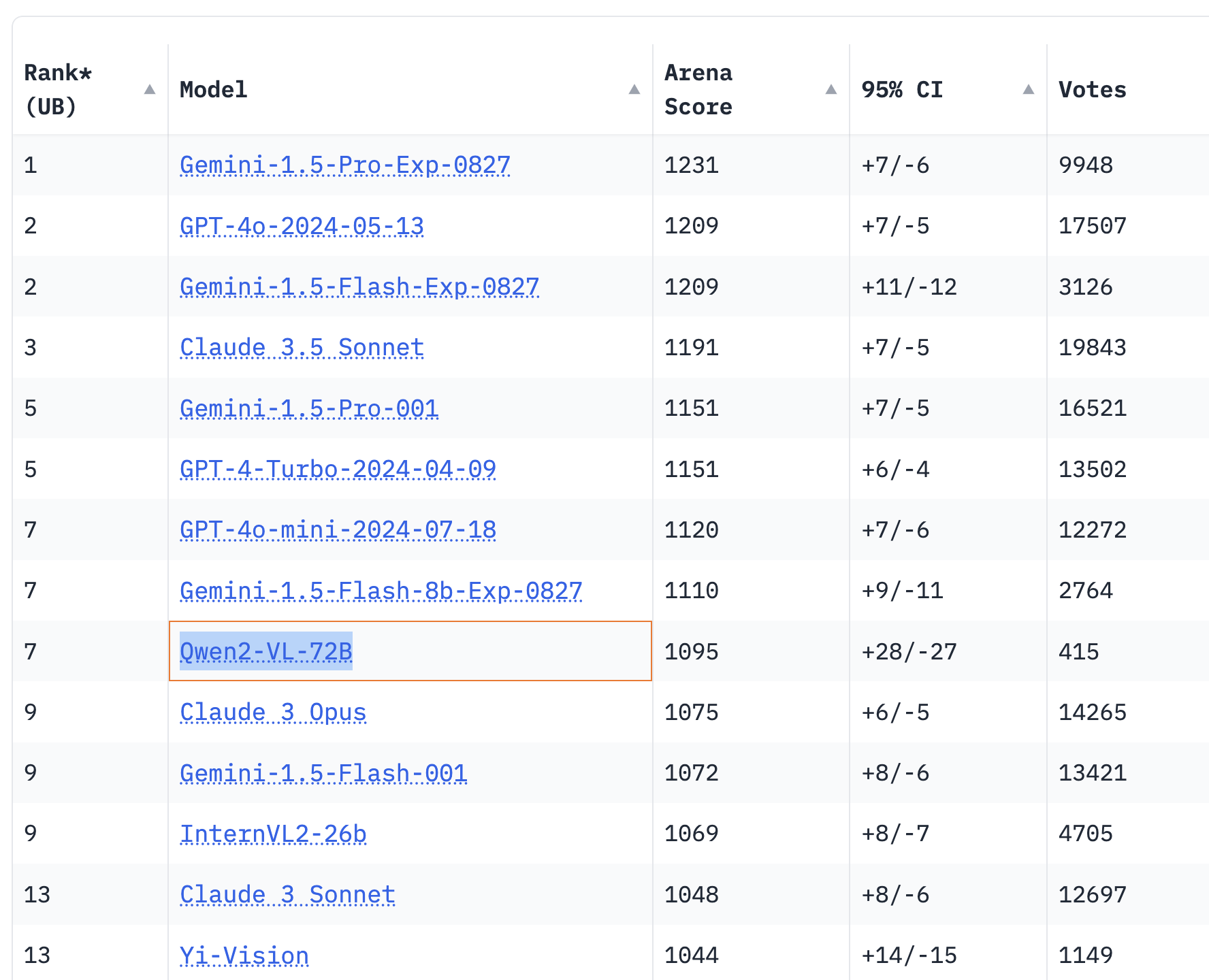
Qwen2-VL-72B 在權威測評 LMSYS Chatbot Arena Leaderboard 成為成為全球得分最高的開源視覺理解模型
自從 2023 年 8 月開源以來,通義在全球開源大模型領域後來居上,成為開發者尤其是中國開發者的首選模型。性能上,通義大模型日拱一卒,逐步趕超美國最強開源模型 Llama,多次登頂 Hugging Face 全球大模型榜單;生態上,通義從零起步、開疆拓土,與海內外的開源社區、生態夥伴、開發者共建生態網絡,截至 2024 年 9 月中旬,通義千問開源模型下載量突破 4000 萬,Qwen 系列衍生模型總數超過 5 萬個,成為僅次於 Llama 的世界級模型群。
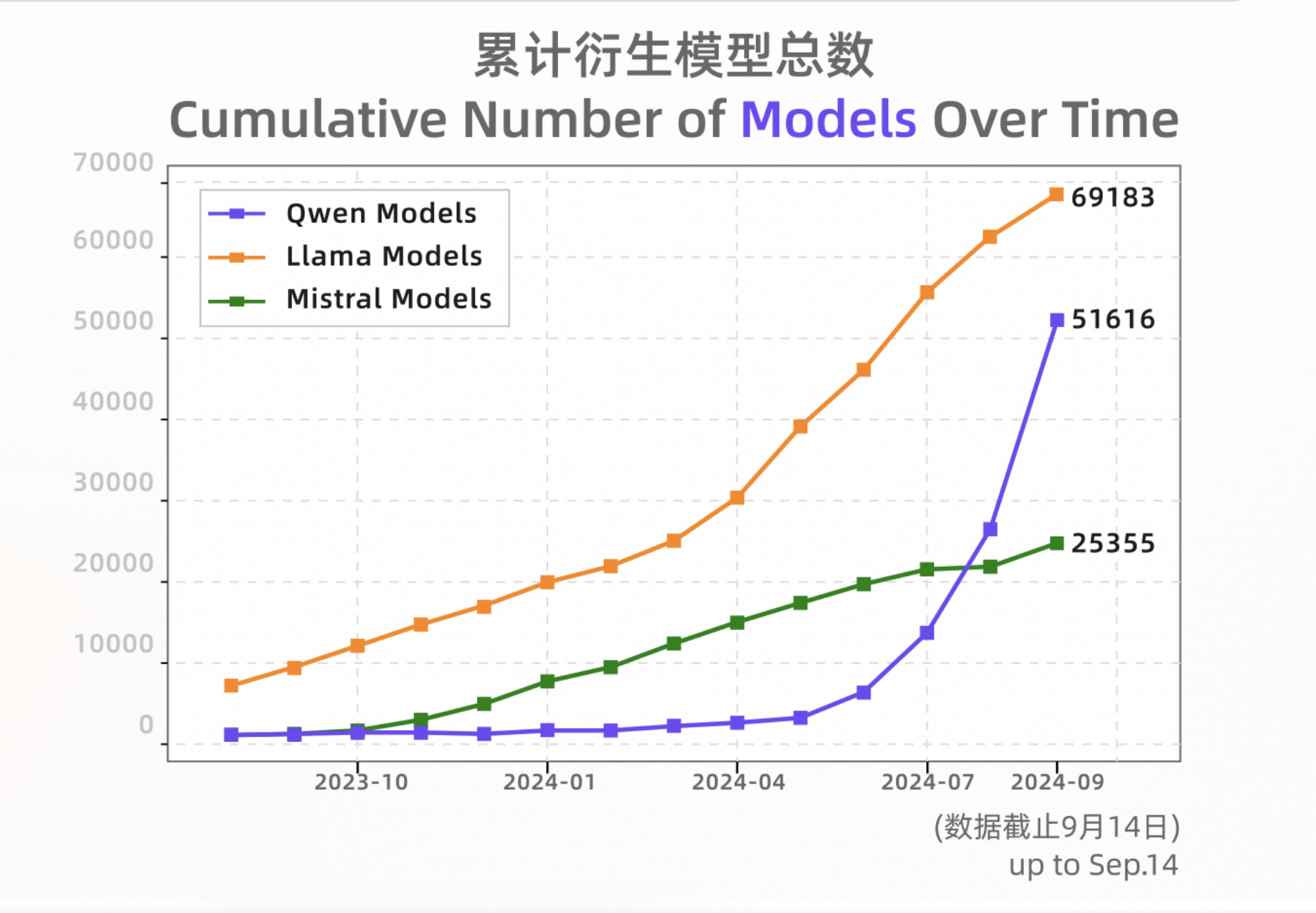 HuggingFace 數據顯示,截至 9 月中旬 Qwen 系列原生模型和衍生模型總數超過 5 萬個
HuggingFace 數據顯示,截至 9 月中旬 Qwen 系列原生模型和衍生模型總數超過 5 萬個














