Meta AI 發佈 Llama 3.2 多模態AI模型 性能與GPT4o-mini 相當 能夠在邊緣設備上高效運行
Meta AI 發佈 Llama 3.2多模態AI模型,旨在提供強大的自然語言處理和圖像理解能力。其設計目標是提高AI在邊緣計算和移動設備上的性能,
Llama 3.2包括適用於邊緣和移動設備的小型和中型視覺大語言模型(11B 和 90B)以及輕量文本模型(1B 和 3B)。
-
多模態處理能力
- LLaMA 3.2支持同時處理文本、圖像和影片,能夠理解並生成跨媒體內容,增強用戶體驗。例如,用戶可以在同一交互中結合文字和圖像。
-
高效邊緣計算
- 模型經過優化,能夠在邊緣設備上高效運行,降低延遲並提高響應速度。這使得實時應用(如影片通話中的AI助手)成為可能。
-
改進的上下文理解
- 通過增強的上下文處理能力,LLaMA 3.2能夠更好地理解複雜對話,並進行多輪交流,使得人機互動更加自然流暢。
Llama 3.2 系列中最大的兩個模型,11B 和 90B,支持圖像推理用例,如文檔級理解,包括圖表和圖形的理解、圖像說明以及基於自然語言描述的視覺定位任務。例如,一個人可以詢問自己的小企業在去年哪一月份銷售最好,Llama 3.2 可以基於可用圖表進行推理並快速提供答案。在另一個示例中,模型可以根據地圖進行推理,並幫助回答諸如何時徒步旅行可能變陡峭或某條特定小徑的距離等問題。11B 和 90B 模型還可以通過從圖像中提取細節、理解場景,然後構造一兩句話作為圖像說明來填補視覺和語言之間的鴻溝,從而幫助講述故事。
輕量級的 1B 和 3B 模型具有強大的多語言文本生成和工具調用能力。這些模型使開發者能夠構建個性化的、本地智能應用程序,保護隱私,確保數據永遠不會離開設備。例如,這樣的應用程序可以幫助總結最近收到的 10 條消息,提取行動項,並利用工具調用直接發送後續會議的日曆邀請。
模型評估
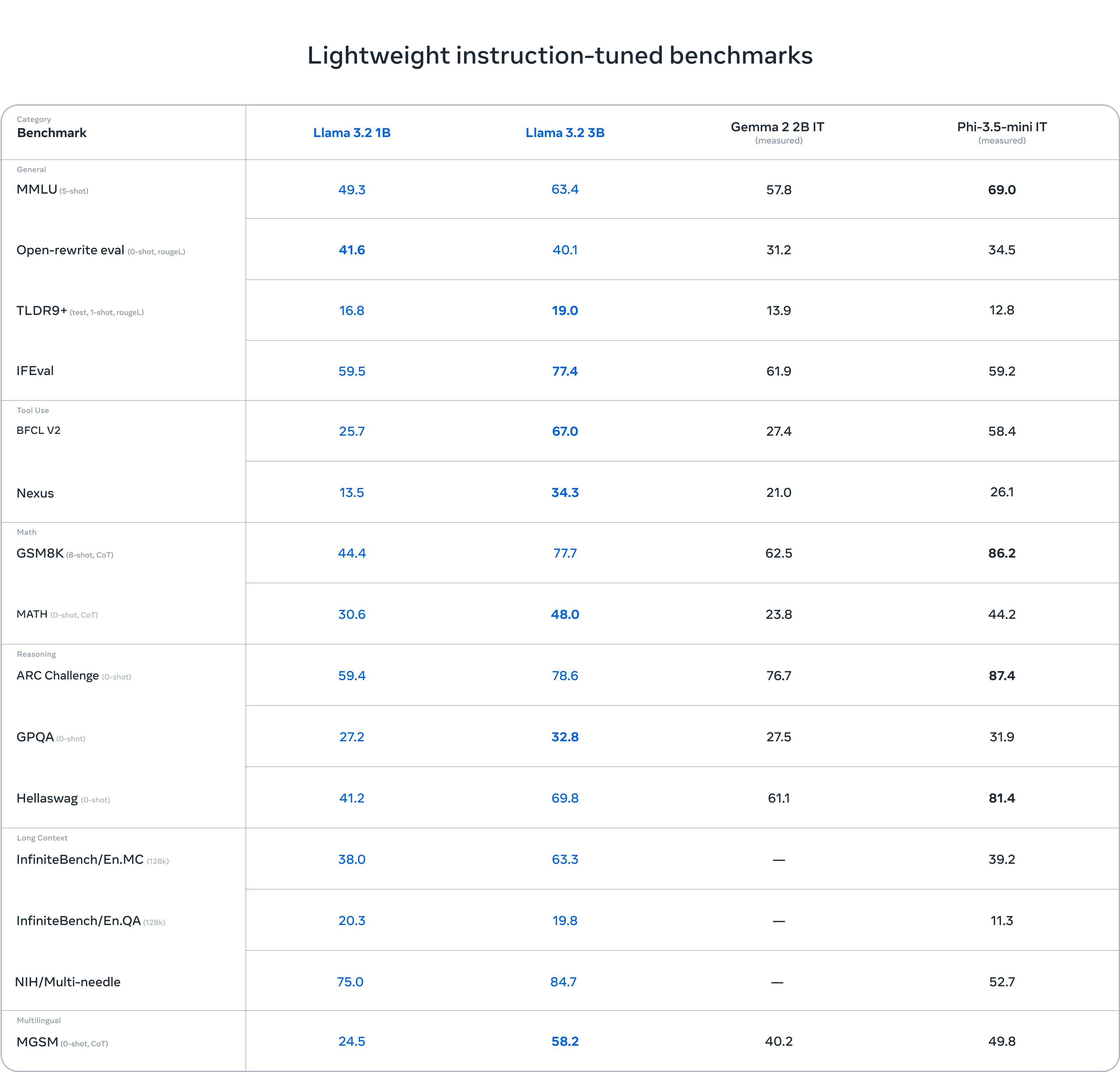
評估表明,Llama 3.2 的視覺模型在圖像識別和一系列視覺理解任務中與領先的基礎模型 Claude 3 Haiku 和 GPT4o-mini 競爭。3B 模型在遵循指令、總結、提示重寫和工具使用等任務上超越了 Gemma 2 2.6B 和 Phi 3.5-mini 模型,而 1B 模型與 Gemma 競爭力相當。
在 150 多個基準數據集上評估了性能,這些數據集覆蓋了多種語言。對於視覺大語言模型,我們評估了圖像理解和視覺推理的基準性能。
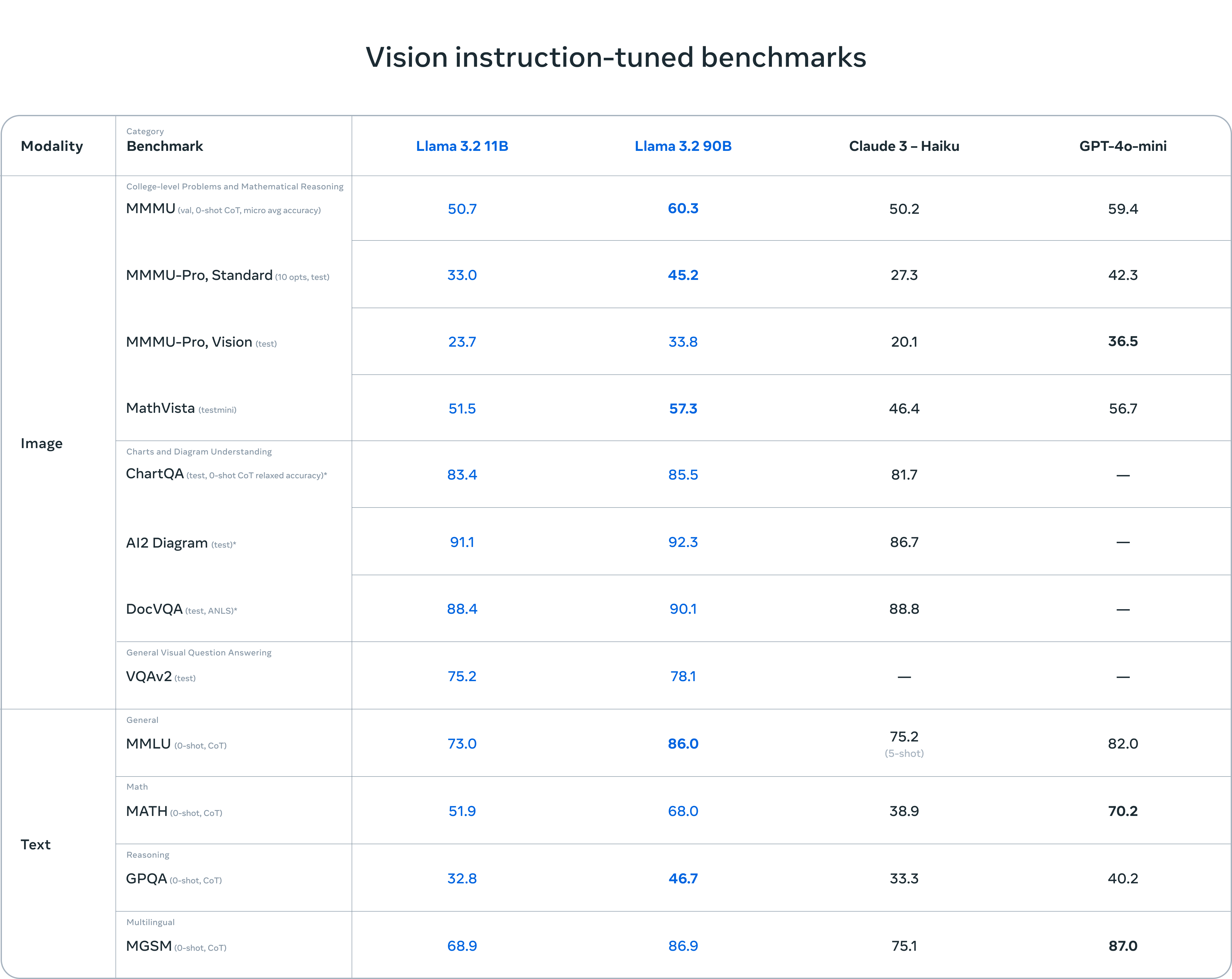
視覺模型
作為首批支持視覺任務的 Llama 模型,11B 和 90B 模型需要全新的模型架構以支持圖像推理。
為了添加圖像輸入支持,Meta訓練了一組適配器權重,將預訓練的圖像編碼器整合到預訓練的語言模型中。適配器由一系列交叉注意層組成,這些層將圖像編碼器的表示輸入到語言模型中。在文本-圖像對上訓練適配器,以將圖像表示與語言表示對齊。在適配器訓練過程中,還更新了圖像編碼器的參數,但故意不更新語言模型參數。通過這種方式,保持了所有文本僅模型的能力,為開發者提供了 Llama 3.1 模型的直接替代。
訓練管道由多個階段組成,從預訓練的 Llama 3.1 文本模型開始。首先,我們添加圖像適配器和編碼器,然後在大規模噪聲(圖像,文本)對數據上進行預訓練。接下來,我們在中等規模的高質量領域內和知識增強的(圖像,文本)對數據上進行訓練。
在後期訓練中,我們使用與文本模型類似的配方,通過多輪對監督微調、拒絕采樣和直接偏好優化進行調整。我們利用合成數據生成,使用 Llama 3.1 模型過濾和增強基於領域內圖像的問題和答案,並使用獎勵模型對所有候選答案進行排名,以提供高質量的微調數據。我們還增加了安全緩解數據,以生產出具有高安全性的模型,同時保留模型的實用性。
最終結果是一組能夠接受圖像和文本提示並對其組合進行深刻理解和推理的模型。這是 Llama 模型擁有更豐富的自主能力的又一步。
輕量模型
Llama 3.2 1B 和 3B 模型使用了修剪和蒸餾兩種方法,使它們成為首批高效適配設備的小型 Llama 模型。
修剪能夠在保持儘可能多的知識和性能的同時減少 Llama 群體中現有模型的大小。對於 1B 和 3B 模型,採用從 Llama 3.1 8B 模型中一次性結構修剪的方法。這涉及系統性地移除網絡的一部分,並調整權重和梯度的大小,以創建一個較小、更高效的模型,保留原始網絡的性能。
知識蒸餾使用一個較大的網絡來向較小的網絡傳授知識,意在使小模型在有教師的情況下能夠比從頭開始實現更好的性能。在 Llama 3.2 的 1B 和 3B 模型中,模型開發的預訓練階段,將來自 Llama 3.1 8B 和 70B 模型的 logits 納入其中,這些較大模型的輸出(logits)用作標記級目標。知識蒸餾是在修剪後進行的,以恢復性能。
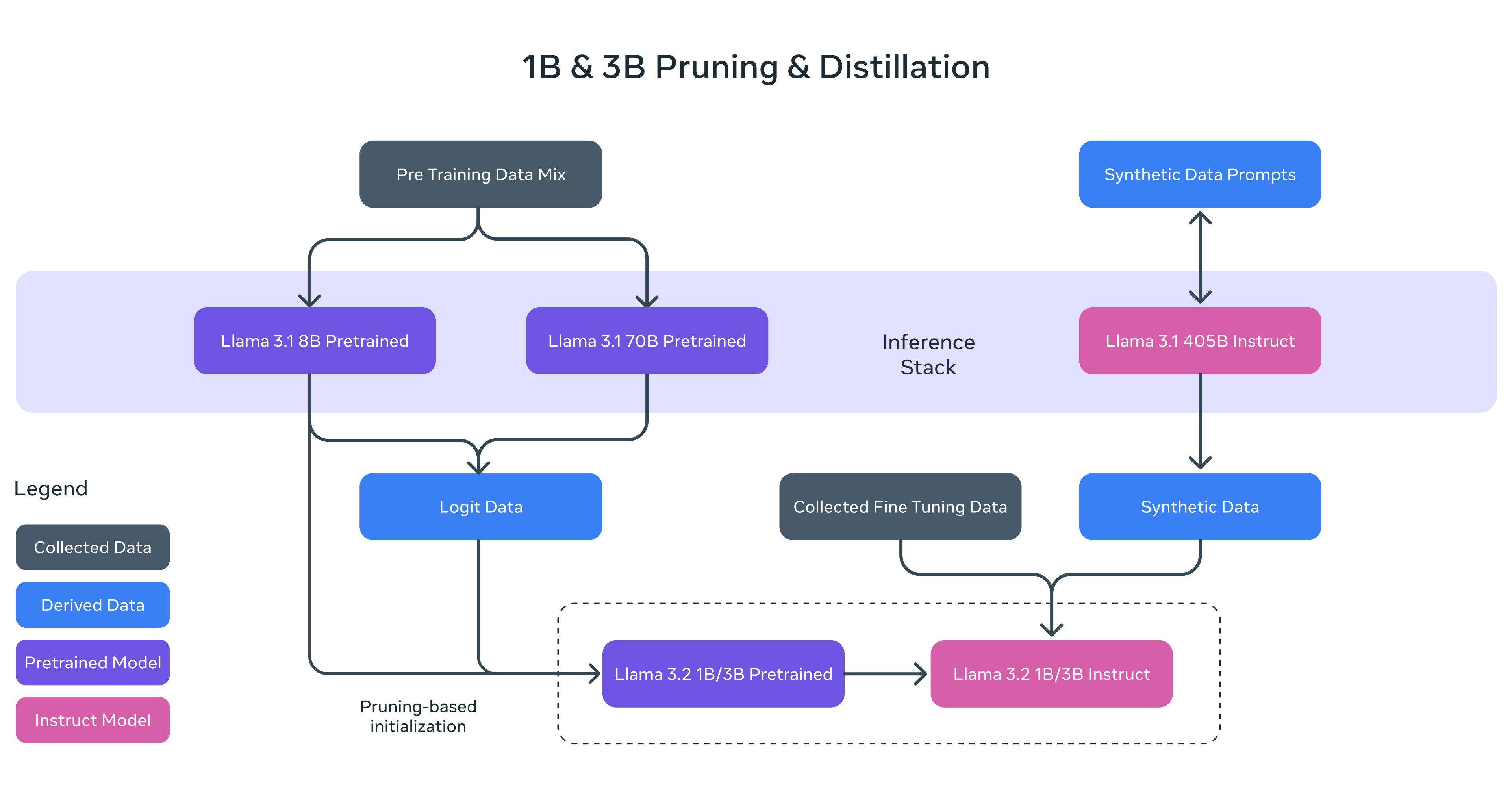
在後期訓練中,使用與Llama3.1相似的配方,通過多輪對預訓練模型的調整,生成最終聊天模型。每輪涉及監督微調(SFT)、拒絕采樣(RS)和直接偏好優化(DPO)。
在後期訓練中,將上下文長度支持擴展到 128K 個令牌,同時保持與預訓練模型相同的質量。Meta還進行合成數據生成,經過仔細的數據處理和過濾,以確保高質量。我們仔細混合數據,以在摘要、重寫、指令跟隨、語言推理和工具使用等多種能力上優化高質量。
為了促進社區在這些模型上的創新,Meta與全球領先的移動系統芯片公司,如Qualcomm和MediaTek,以及為99%移動設備提供基礎計算平台的Arm,進行了緊密合作。今天發佈的模型權重採用了BFloat16數值格式,這使得新一代硬件能夠得到更好的利用。Meta期待基於LLaMA 3.2開發的新應用和功能,這些應用將顯著提升移動設備和邊緣AI的能力。
詳細內容:https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices
模型下載:https://www.llama.com/