剛剛,Llama 3.2 來了!支持圖像推理,還有可在手機上運行的版本
轉自 | 機器之心
今天淩晨,大新聞不斷。一邊是 OpenAI 的高層又又又動盪了,另一邊被譽為「真・Open AI」的 Meta 對 Llama 模型來了一波大更新:不僅推出了支持圖像推理任務的新一代 Llama 11B 和 90B 模型,還發佈了可在邊緣和移動設備上的運行的輕量級模型 Llama 3.2 1B 和 3B。
不僅如此,Meta 還正式發佈了 Llama Stack Distribution,其可將多個 API 提供商打包在一起以便模型方便地調用各種工具或外部模型。此外,他們還發佈了最新的安全保障措施。
真・Open AI 誠不我欺!各路網民和企業都紛紛激動地點讚。要知道,現在距離 7 月 23 日 Llama 3.1 發佈才剛剛過去 2 個月。

Meta 首席 AI 科學家 Yann LeCun 也歡快地表達了自己的喜悅:「乖寶寶羊駝!」

Meta 也借此機會重申了他們一貫的主張:「通過開源人工智能,我們才能確保這些創新能夠反映和造福於其所服務的全球社區。我們將通過 Llama 3.2 繼續推動讓開源成為標準。」
Llama 家族是在今天的 Meta Connect 2024 大會上迎來升級的。這一次,我們終於有了可以在邊緣設備和移動設備上本地運行的輕量級 LLM(Llama 3.2 1B 和 3B)!同時,小型和中型版本也獲得了相應更新,參數量也都各有大幅增多,因為它們都獲得了一個重大升級:可以處理視覺數據了!也因此,它們的模型卡都加上了 Vision 標籤。
-
Llama 3.1 8B 升級成 Llama 3.2 11B Vision
-
Llama 3.1 70B 升級成 Llama 3.2 90B Vision
Llama 系列模型發佈至今不過一年半時間,其取得的成就著實讓人驚歎。Meta 表示:今年,Llama 實現了 10 倍的增長,並已經成為「負責任創新」的標準。Llama 持續在開放性、可修改性和成本效率方面保持領先地位,並且足以與封閉模型競爭 —— 甚至在某些領域還處於領先地位。
Meta 表示:「我們相信開放能推動創新並且是正確的前進道路,因此我們會繼續分享我們的研究並與我們的合作夥伴和開發者社區合作。」
現在我們馬上就可以開始上手體驗:
官網下載:https://llama.meta.com
Hugging Face:https://huggingface.co/meta-llama
目前 Llama 3.2 最大的兩個模型 11B 和 90B 都支持圖像推理,包括文檔級的圖表理解、圖像描述和視覺定位任務,比如直接根據自然語言描述定位圖像中的事物。
舉個例子,用戶可以提問:「去年哪個月的銷售情況最好?」然後 Llama 3.2 可以根據可用圖表進行推理並快速提供答案。
至於輕量級的 1B 和 3B 版本,則都是純文本模型,但也具備多語言文本生成和工具調用能力。Meta 表示,這些模型可讓開發者構建個性化的、在設備本地上運行的通用應用 —— 這類應用將具備很強的隱私性,因為數據無需離開設備。
在本地運行這些模型具有兩大主要優勢:
-
提示詞和響應可以帶來即時完成的感覺,因為處理過程都在本地進行;
-
本地運行模型時,無需將消息和日曆等隱私信息上傳到雲端,從而保證信息私密。由於處理是在本地進行,因此可讓應用判斷哪些任務可以在本地完成,哪些需要借助雲端的更強大模型。
模型評估
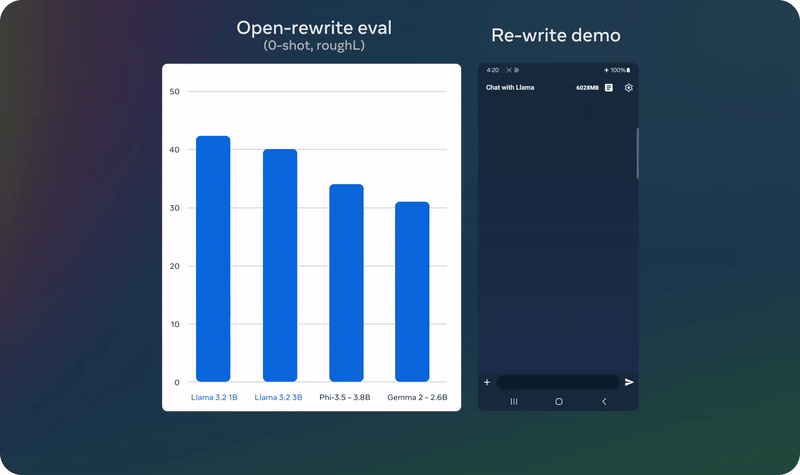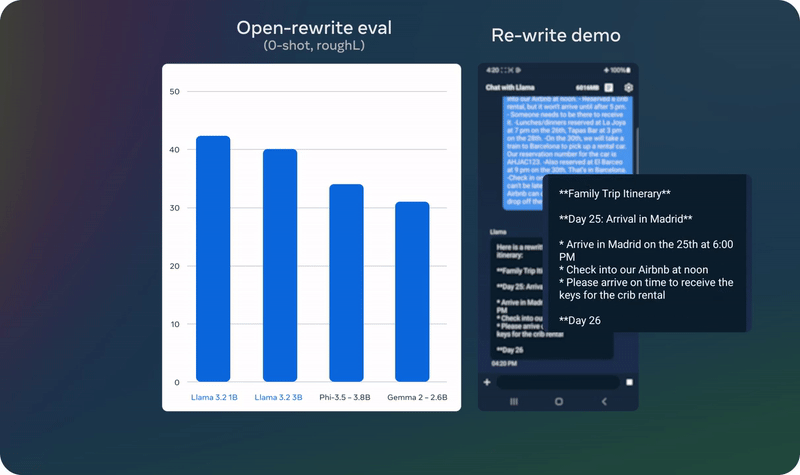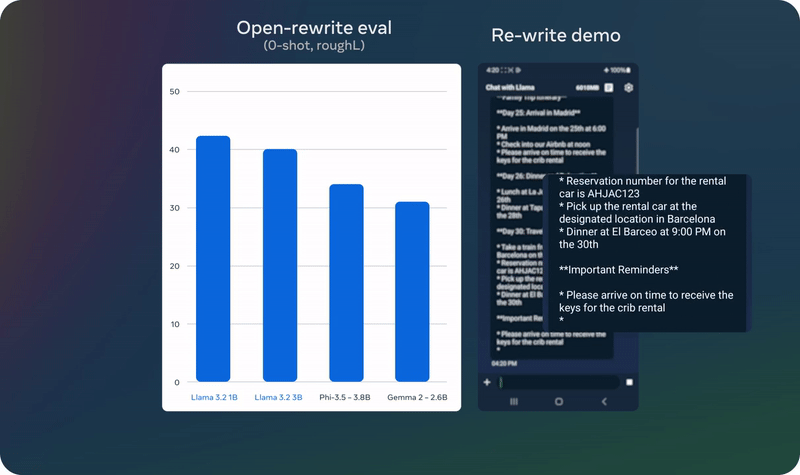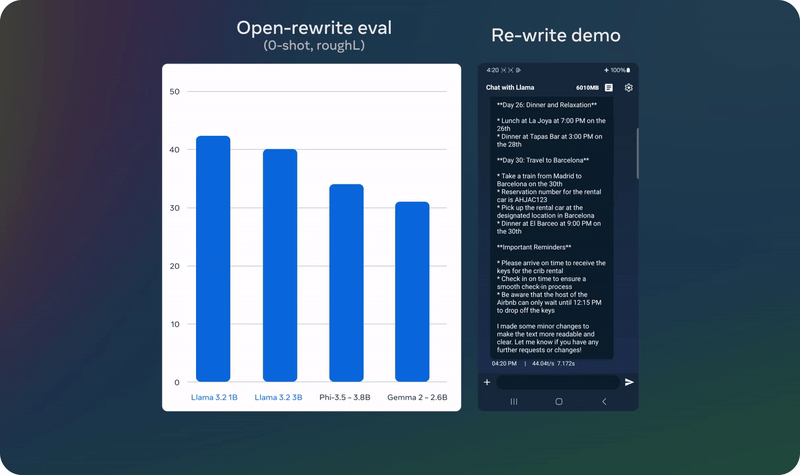
Meta 也發佈了 Llama 3.2 視覺模型的評估數據。整體來說,其在圖像識別等一系列視覺理解任務上足以比肩業界領先的基礎模型 Claude 3 Haiku 和 GPT4o-mini。另外,在指令遵從、總結、提示詞重寫、工具使用等任務上,Llama 3.2 3B 模型的表現也優於 Gemma 2 2.6B 和 Phi 3.5-mini;同時 1B 的表現與 Gemma 相當。
具體來說,Meta 在涉及多種語言的 150 多個基準數據集上對 Llama 3.2 進行了評估。對於視覺 LLM,評估基準涉及圖像理解和視覺推理任務。


視覺模型
Llama 3.2 11B 和 90B 模型是首批支持視覺任務的 Llama 模型,因此 Meta 為其配備了支持圖像推理的全新模型架構。
具體來說,為了支持圖像輸入,Meta 訓練了一組適應器權重(adapter weight),其可將預訓練的圖像編碼器集成到預訓練的語言模型中。該適應器由一系列交叉注意層組成,這些層的作用是將圖像編碼器表徵饋送給語言模型。為了將圖像表徵與語言表徵對齊,Meta 在「文本 – 圖像對」數據上對適應器進行了訓練。在適應器訓練期間,Meta 選擇更新圖像編碼器的參數,但卻有意不更新語言模型參數。這樣一來,便可以保持所有純文本能力不變,讓開發者可以直接使用 Llama 3.2 替代 Llama 3.1。
具體的訓練流程分成多個階段。從已經完成預訓練的 Llama 3.1 文本模型開始,首先,添加圖像適應器和編碼器,然後在大規模有噪聲的成對 (圖像,文本) 數據上進行預訓練。接下來,在中等規模的高質量域內和經過知識增強的 (圖像,文本) 對數據上進行訓練。
在後訓練階段,再使用與文本模型類似的方法進行多輪對齊,這會用到監督式微調、拒絕采樣和直接偏好優化。他們還使用了合成數據生成,具體做法是使用 Llama 3.1 模型來過濾和增強在域內圖像上的問題和答案,並使用一個獎勵模型來給所有候選答案進行排名,從而提供高質量的微調數據。此外,為了得到高安全性且有用的模型,Meta 還添加了安全緩解數據。
最終,Meta 得到了一系列同時支持圖像和文本提示詞的模型,並且有能力在圖像和文本組合數據上執行深度理解和推理。Meta 說:「向著具備更豐富智能體能力的 Llama 模型,這是邁出的又一步。」
輕量級模型
正如 Meta 在發佈 Llama 3.1 時提到的,可以利用強大的教師模型來創建更小的模型,這些模型具有更好的性能。Meta 對 1B 和 3B 模型進行了剪枝和蒸餾,使它們成為首批能夠在設備上高效運行的輕量級 Llama 模型。
通過剪枝技術,能夠在儘量保留原有知識和性能的前提下,顯著減小 Llama 系列模型的體積。在 1B 和 3B 模型的開發過程中,Meta 採用了一次性的結構化剪枝策略,這一策略從 Llama 3.1 的 8B 衍生而來。具體來說,Meta 系統地移除了網絡中的某些部分,並相應地調整了權重和梯度的規模,從而打造出了一個體積更小、效率更高的模型,同時確保了它能夠維持與原始網絡相同的性能水平。
在完成剪枝步驟之後,Meta 應用了知識蒸餾技術,以進一步提升模型的性能。
知識蒸餾是一種通過大型網絡向小型網絡傳授知識的技術,其核心思路是,借助教師模型的指導,小型模型能夠實現比獨立訓練更優的性能。在 Llama 3.2 的 1B 和 3B 模型中,Meta 在模型開發的預訓練階段引入了 Llama 3.1 的 8B 和 70B 模型的輸出,用作訓練過程中的 token 級目標。

在 post-training 階段,Meta 採用了與 Llama 3.1 相似的方法 —— 在預訓練模型的基礎上進行多輪對齊,其中每一輪都包括監督式微調(SFT)、拒絕采樣(RS)和直接偏好優化(DPO)。
具體來說,Meta 將上下文窗口長度擴展到了 128K 個 token,同時保持與預訓練模型相同的質量。
為了提高模型的性能,Meta 也採用了生成合成數據的方法,他們篩選高質量的混合數據,來優化模型在總結、重寫、遵循指令、語意推理和使用工具等多種能力。
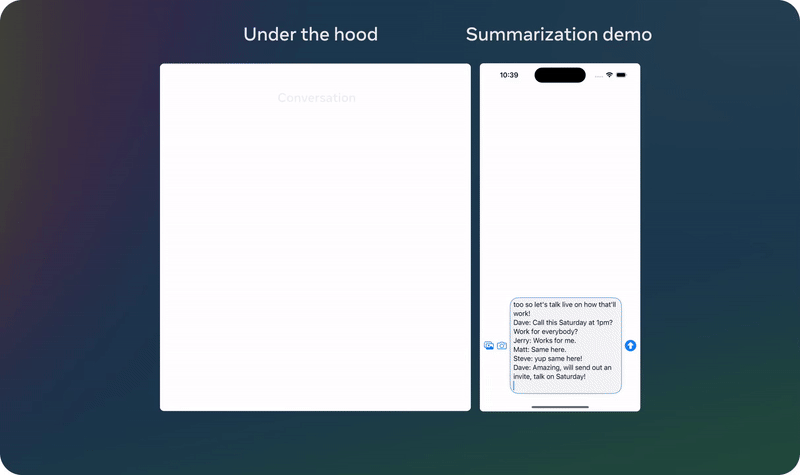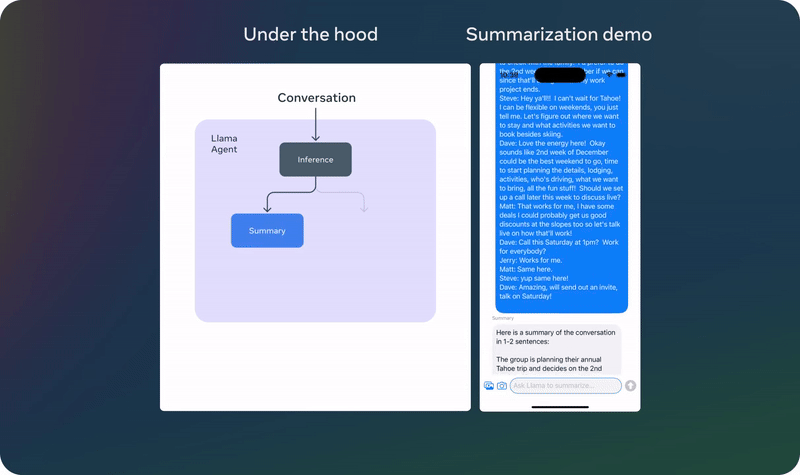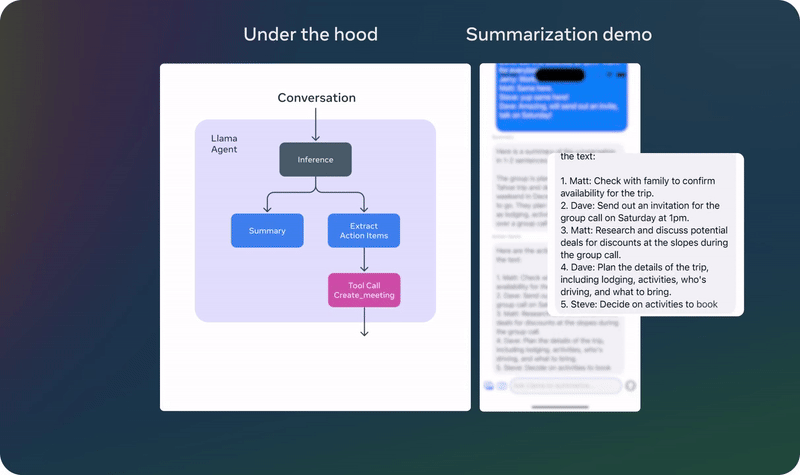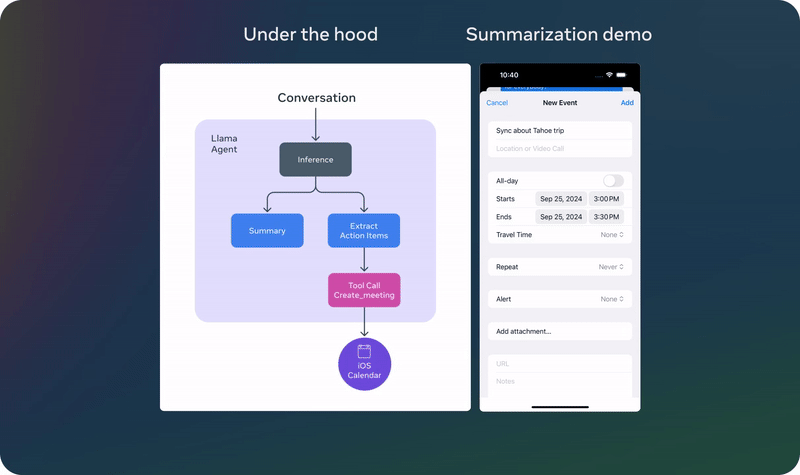
 以上演示基於一個未發佈的量化模型
以上演示基於一個未發佈的量化模型 以上演示基於一個未發佈的量化模型
以上演示基於一個未發佈的量化模型已經有動作快的網民對 Meta 新發佈的輕量級模型進行了測試。他表示新的 1B 模型的能力好得出人意料,畢竟這個模型的參數量如此之小。具體來說,他讓 Llama 3.2 1B 分析了一個完整的代碼庫,結果發現其表現雖不完美,但已經相當優秀了。

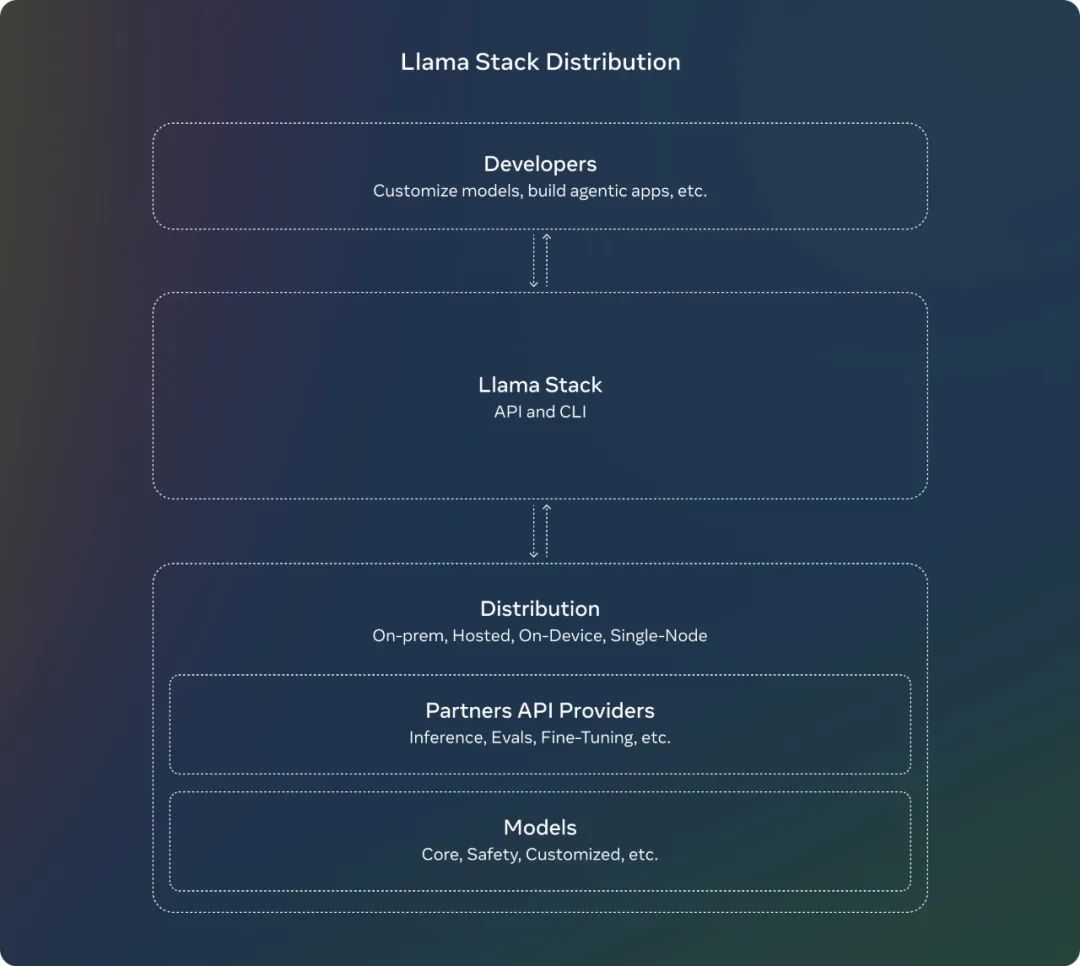
Llama Stack 發行版
在七月份,Meta 就發佈了 關於 Llama Stack API 的徵求意見稿,這是一個標準化的接口,用於規範工具鏈組件(微調、合成數據生成)來定製 Llama 模型並構建代理應用程序。從那時起,Meta 一直在努力使 API 成為現實,並為推理、工具使用和 RAG 構建了 API 的參考實現。
此外,Meta 還引入了 Llama Stack Distribution,作為一種將多個 API 提供者打包在一起的方式,以便為開發人員提供一個單一的端點。Meta 現在與社區分享一個簡化和一致的體驗,這將使開發者能夠在多種環境中使用 Llama 模型,包括本地、雲、單節點和設備上。

Meta 發佈的完整系列包括:
Llama CLI(命令行界面),用於構建、配置和運行 Llama Stack 發行版
多語言客戶端代碼,包括 Python、Node、Kotlin 和 Swift
Llama Stack Distribution Server 和 Agents API Provider 的 Docker 容器
多個發行版
通過 Meta 內部實現和 Ollama 提供的單節點 Llama Stack 發行版
通過 AWS、Databricks、Fireworks 和 Together 提供的雲 Llama Stack 發行版
通過 PyTorch ExecuTorch 在 iOS 上實現的設備上 Llama Stack 發行版
由 Dell 支持的本地 Llama Stack 發行版
系統級安全
Meta 表示,採取開源的方法有許多好處,它有助於確保世界上更多的人能夠獲得人工智能提供的機會,防止權力集中在少數人手中,並通過社會更公平、更安全地部署技術。「隨著我們繼續創新,我們也希望確保我們正在賦予開發者構建安全和負責任的系統的能力。」
在先前的成果和持續支持負責任創新的基礎上,Meta 已經發佈了最新的安全保障措施:
-
首先,他們發佈了 Llama Guard 3 11B Vision,它旨在支持 Llama 3.2 的新圖像理解能力,並過濾文本 + 圖像輸入提示或這些提示的文本輸出響應。
-
其次,由於 Meta 發佈了 1B 和 3B 的 Llama 模型,用於更受限的環境,如設備上使用,他們還優化了 Llama Guard,大幅降低了其部署成本。Llama Guard 3 1B 基於 Llama 3.2 1B 模型,經過剪枝和量化,其大小從 2,858 MB 減少到 438 MB,使其部署變得更加高效。
這些新解決方案已經集成到 Meta 的參考實現、演示和應用程序中,並且從第一天起就可供開源社區使用。

參考鏈接:https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/

















