邁向多語言醫療大模型:大規模預訓練語料、開源模型與全面基準測試
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文的主要作者來自上海交通大學和上海人工智能實驗室智慧醫療聯合團隊,共同第一作者為上海交通大學博士生邱芃铖和吳超逸,共同通訊作者為上海交通大學人工智能學院王延峰教授和謝偉迪副教授,這是該團隊在繼 PMC-LLaMA 後,在持續構建開源醫療語言大模型的最新進展。該項目受到科創 2030—「新一代人工智能」 重大項目支持。
在醫療領域中,大語言模型已經有了廣泛的研究。然而,這些進展主要依賴於英語的基座模型,並受製於缺乏多語言醫療專業數據的限制,導致當前的醫療大模型在處理非英語問題時效果不佳。
為了克服這一挑戰,近期一篇發表在《nature communications》的論文全面地從數據、測評、模型多個角度考慮了多語言醫學大語言模型的構建,做出了三項貢獻:
1. 創建了一個包含 25.5 Billion tokens 的多語言醫療語料庫 MMedC。
2. 開發了一個全新的多語言醫療問答評測標準 MMedBench, 覆蓋了 6 種語言,21 種醫學子課題。
3. 推出了一款名為 MMed-Llama 3 的全新基座模型,以 8B 的尺寸在多項基準測試中超越了現有的開源模型,更加適合通過醫學指令微調,適配到各種醫學場景。
所有數據和代碼、模型均已開源。

-
論文標題:Towards building multilingual language model for medicine
-
論文地址:https://www.nature.com/articles/s41467-024-52417-z
-
項目地址:https://github.com/MAGIC-AI4Med/MMedLM
-
Leaderboard: https://henrychur.github.io/MultilingualMedQA/

圖 a 揭示了構建的多語言醫療語料庫的組成;圖 b 介紹了全面的多語言醫療評測標準 MMedBench 的構成;圖 c 對⽐了本⽂提出的模型 MMedLM 與當前主流模型在 MMedBench 上的準確率,圖 d 展⽰了在 MMedC 上進⼀步預訓練使模型性能相⽐於基線顯著提升。
大規模多語醫療語料(MMedC)構建
在構建數據集方面,研究團隊收集了一份多語言醫療語料庫,命名為 MMedC。該數據集包含 255 億 tokens,其內容來自於四個來源:
1. 通過啟髮式算法,從廣泛的多語言語料庫中(例如 CommonCrawl)篩選相關內容。
2. 蒐集全球各地的電子版醫療教科書,並使用光學字符識別(OCR)技術轉化為文本數據。
3. 從多個國家的許可的醫療相關網站抓取數據。
4. 整合已有的小型醫療語料庫,以豐富和完善數據集。
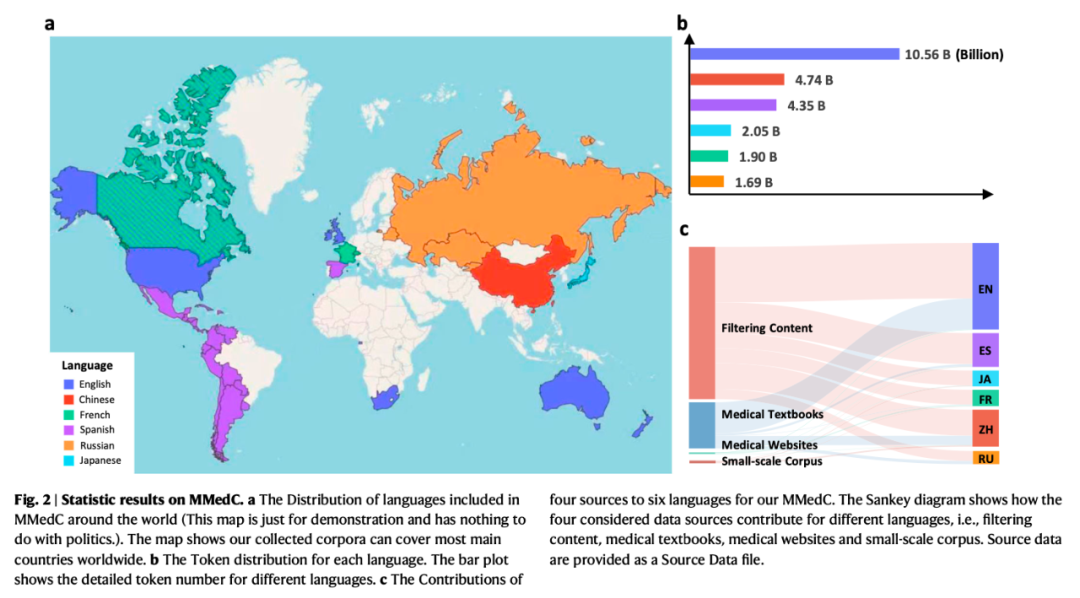
MMedC 數據集統計概覽。圖 a 展示了該語料庫覆蓋的語言對應的地域;圖 b 提供了各種語言的詳細數據量統計;圖 c 深入呈現了每種語言數據的來源分佈比例。
全面多語言醫學能力測試基準數據集(MMedBench)構建
為了評估醫學領域多語言模型的發展,研究團隊設計了一項全新的多語言選擇題問答評測標準,命名為 MMedBench。此基準測試的所有問題均直接源自各國的醫學考試題庫,而非簡單地通過翻譯獲得,避免了由於不同國家醫療實踐指南差異導致的診斷理解偏差。
此外,研究團隊還為每個題目提供了正確答案的詳細解釋。在評測過程中,要求模型不僅要選出正確答案,還需提供合理的解答理由。這樣的設計不僅測試了模型回答選擇題的能力,也測試其理解和解釋複雜醫療信息的能力,從而更全面地評估其性能。
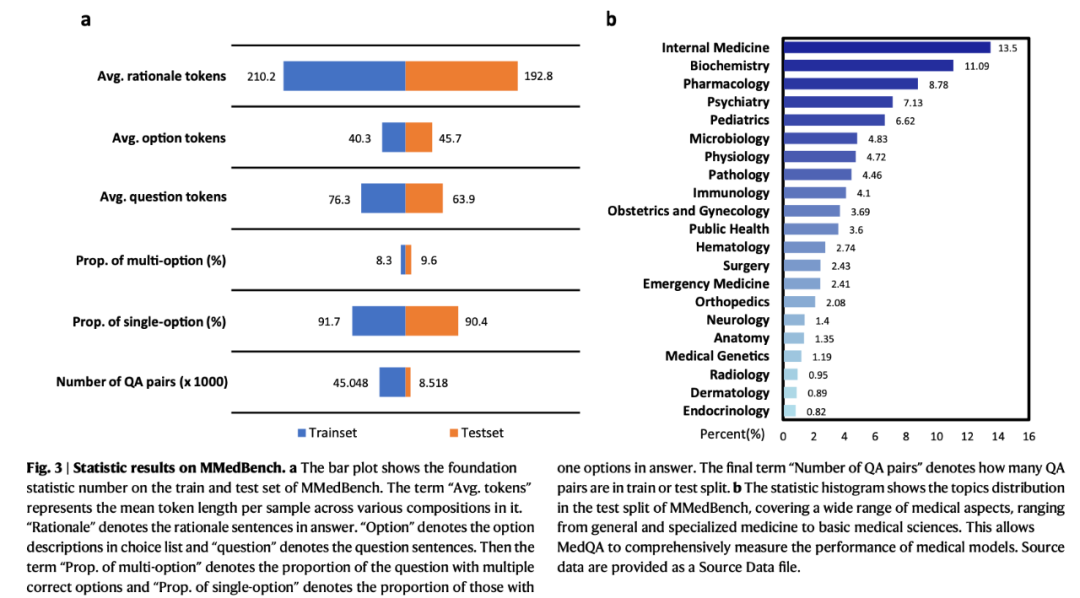
MMedBench 數據統計。圖 a 呈現了 MMedBench 訓練集與測試集的基礎數值統計信息;圖 b 揭示了 MMedBench 樣本在不同主題上的分佈情況。
MMedBench 模型測評
研究團隊對主流醫療語言模型在 MMedBench 基準上,對三種不同的測試策略進行了評估:
-
Zero-shot:適用於沒有開源的模型,通過提供 Prompt,引導模型回答選擇題,並解釋其答案選擇的原因。
-
PEFT Finetuning:適用於已開源的模型,首先利用 LoRA 技術對模型在 MMedBench 訓練集上進行局部微調,然後在測試集上評估其性能。
-
Full model Finetuning:適用於已開源的模型,首先在 MMedBench 的訓練集上進行全量微調,隨後再在 MMedBench 的測試集上進行測試。
模型準確率評測
如表所示,主流的醫學大語言模型在英語中通常表現出很高的準確率,但在非英語語言中的性能顯著下降。具體來說,經過微調的 PMC-LLaMA 在英語上的平均準確率為 47.53,儘管其性能超過了同時期的其他模型,但仍顯著落後於 GPT 模型。隨後,隨著更先進的基礎模型的應用,開源模型開始縮小與 GPT 系列的差距。例如,在 MMedBench 的訓練集上進行全量微調,Mistral、InternLM 2、Llama 3 的平均準確率分數為 60.73、58.59 和 62.79。在 MMedC 語料庫上進行進一步自回歸訓練後,也觀察到性能的提升。具體來說,最終模型 MMed-Llama 3 與其基座模型 Llama 3 相比,表現出了顯著的性能提升,在全量微調評估下,MMed-Llama 3(67.75)平均準確率顯著超越了 Llama 3(62.79)。對於 PEFT 微調也有類似的結論,即在 MMedC 上的進一步自回歸訓練帶來了顯著的收益。

主流模型在 MMedBench 上的準確率評測。其中 「MMedC」 標誌著模型是否在 MMedC 語料庫上完成進一步預訓練,「MMedBench」 則標誌著模型是否在 MMedBench 的訓練集上完成微調。需要注意的是,English,Chinese,Spanish 是四選一選擇題,Russian 是二選一選擇題,French,Japanese 是不定項選擇題。只有模型輸出完全正確時,才會被視為正樣本。「Avg.」 代表這六種語言的平均準確率。
模型解釋答案能力評測(ROUGE-1/BLEU-1)
除了多項選擇問答任務外,研究還擴展到評測各種大型語言模型的推理能力具體來說,對於給定的問題和選項,模型在輸出選擇答案的同時,還需要輸出選擇該答案的理由。下表展示了主流模型在 MMedBench 上對選擇題答案的解釋能力。

主流模型在 MMedBench 上進行答案解釋能力評測。使用的自動指標是 BLEU-1/ROUGE-1。
考慮到基於句子相似度的自動指標不一定能準確地反應人類偏好,研究團隊進一步對模型生成的答案解釋進行了人工評估,精選了六種代表性強的語言模型進行研究,並對人工評價結果與自動評估指標的一致性進行了深入分析。

模型打分結果對比數析。圖 a 展示了按照 BLEU 分數、人工質量排序和 GPT-4 質量排序的量化分數。圖 B 展示了自動指標和人類評估之間的相關性,其中 k 代表擬合直線的斜率,t 代表坎德爾相關係數。
公開英文評測基準模型測評
為了在英語基準測試上與現有的大型語言模型進行公平比較,研究團隊還基於 MMed-Llama 3 基座模型進行英文指令微調(數據集來自 PMC-LLaMA)。常用的醫療多項選擇問答基準測試有四個,分別是 MedQA、MedMCQA、PubMedQA 和 MMLU-Medical。如下表所示,MMed-Llama 3 在英語基準測試上展示了很好的表現,在 MedQA、MedMCQA 和 PubMedQA 上分別獲得了 4.5%、4.3% 和 2.2% 的性能提升。同樣地,在 MMLU 上,MMed-Llama 3 也在大部分結果中都能達到了開源大語言模型中最好的表現,顯著超過了 GPT-3.5。

英語多項選擇題答題基準的準確率評估。報告了每個模型在不同任務中的準確率,「Avg. 」 表示九個任務的平均得分。請注意,為公平起見,所有分數都是基於基本的 zero-shot 生成設置,沒有額外的提示策略。由於英文基準已被廣泛得應用,因此直接使用其原始論文中報告的分數。對於 MedAlpaca、GPT-4、GPT-3.5 和 Llama 3,它們的分數基於 Open Medical-LLM 排行榜。
數據側消融實驗
在數據側的消融實驗中,作者研究了不同的預訓練語料構建過程造成的影響。消融實驗是在全量微調下對 MMedLM、MMedLM 2 和 MMed-Llama 3 進行的,分別以 InternLM、InternLM 2 和 Llama 3 作為基礎模型。總體而言,三個模型的結論是一致的,在接下來的討論中,將重點關注最終模型 MMed-Llama 3。
研究團隊區分了 HQ-Data(高質量數據)和 US-Data(未指定來源數據)。HQ-Data 包括來自書籍和網站的內容,這些內容經過了人工檢驗,而 US-Data 則是從一般通用語料庫中篩選出的與醫學相關的內容。如下表所示,為選擇題配備選擇理由可以輔助模型更好地理解問題,從 58.72 提高到 62.79,增幅 4.06(對比各模型結果表格的第一行與第二行)。然而,僅在 MMedC 的英語部分進行進一步的自回歸訓練(參考 MMed-Llama 3-EN)並沒有帶來準確率的提升。這可能是因為過擬合英語,儘管在英語中的性能優越,但在其他語言中的結果較差。當將自回歸訓練擴展到整個多語言醫學語料庫時,這個問題可以在很大程度上得到緩解,顯著改善最終結果。這不僅提高了選擇準確率至 64.40,還分別在 BLEU-1 和 ROUGE-1 上提高了推理能力 0.48 和 0.54(對比各模型結果表格的第三行與第四行)。此外,引入自動收集的 US-Data 有助於進一步將準確率從 64.40 提高到 67.75,顯著增加了 3.35(參考 MMed-Llama 3)。在解釋能力上也可以觀察到性能增益,即 BLEU-1 增加 0.29,ROUGE-1 增加 0.16。

消融實驗。其中 HQ-Data 與 US-Data 用於區分醫療數據是否經過人工審核。具體而言,通過啟髮式算法從 CommonCrawl 自動獲取的數據被歸類為 US-Data(未審核數據),而來自其他來源的語料信息均經過了嚴格的人工審核,因此被標記為 HQ-Data(高質量數據)。
研究與臨床價值
在本項工作中,研究團隊首次引入了醫療領域的多語言大模型,這對研究和臨床實踐都有著重要的影響。在研究方面,本工作促進了以下研究的發展:
-
通用醫療人工智能(GMAI):GMAI 是指能夠廣泛應用於不同醫療場景下的多模態人工智能模型,其中大型語言模型常作為人機交互的橋樑。採用多語言的醫療模型,替代以往以英語為中心的模型,能夠充分利用全球多種語言的數據資源,從而擴展可用的多模態訓練數據,提升對其它模態信息表徵的質量。
-
增強檢索的生成任務:在當前的大型語言模型中,”幻覺” 問題被認為是一個主要挑戰,尤其是在醫療領域。一種有效的解決策略是開發具有檢索功能的架構,其核心思想是通過從額外的知識庫中檢索事實信息,並將這些信息輸入到大型語言模型中,來增強其輸出的準確性。然而,迄今為止,大部分的研究都集中在英語上,這極大地限制了檢索增強方法對其他語言知識庫的利用。通過開發多語言的醫療模型,能夠極大地提高檢索過程對不同語言知識庫的利用。
在臨床實踐中,開源的多語言醫療模型也能緩解以下挑戰:
-
語言障礙。在眾多醫療保健系統中,語言障礙是患者與醫療服務提供者之間有效溝通的一個主要障礙。這種障礙可能導致誤解、誤診,最終使得高質量的醫療資源對大多數人而言變得難以觸及。通過提供實時翻譯服務,多語言醫療級大型語言模型使患者能夠清晰表達自己的症狀,並準確理解其診斷與治療方案。
-
深入理解文化與法律的異同。多語言醫療語言模型能夠通過進一步的指令微調,以識別並應對不同國家在醫療診斷過程中的文化和法律差異及敏感性問題。這種對各國文化背景和法律框架的深入理解,不僅可以顯著增強用戶對醫療大語言模型的信任,還能促進更高質量的醫療服務體驗,確保醫療服務的全球化和個性化。




















