純國產萬卡集群煉出萬億參數大模型,被這家央企率先做到了!
金磊 發自 凹非寺
量子位 | 公眾號 QbitAI
首個由萬卡集群訓練出來的萬億參數大模型,被一家央企解鎖了。

具體而言,為純國產人工智能探索出這條路的正是中國電信人工智能研究院(TeleAI),是由中國電信集團 CTO、首席科學家、中國電信人工智能研究院院長李學龍教授帶領團隊完成。
據瞭解,訓練使用的萬卡集群由天翼雲上海臨港國產萬卡算力池提供,並基於天翼雲自研「息壤一體化智算服務平台」和電信人工智能公司自研「星海 AI 平台」的支持,可以實現萬億參數的常穩訓練,平均每週僅有1.5次訓練中斷,集群訓練穩定性達到國際領先水平。
而且基於此,TeleAI 還開源了由國產深度學習框架訓練的千億參數大模型——星辰語義大模型 TeleChat2-115B。
TeleChat 是央企里首個開源的系列語義大模型,而 TeleChat2-115B 則在 TeleChat 的基礎上,通過對訓練數據量、數據質量和配比、模型架構等多維度的優化,取得了更進一步的效果提升!
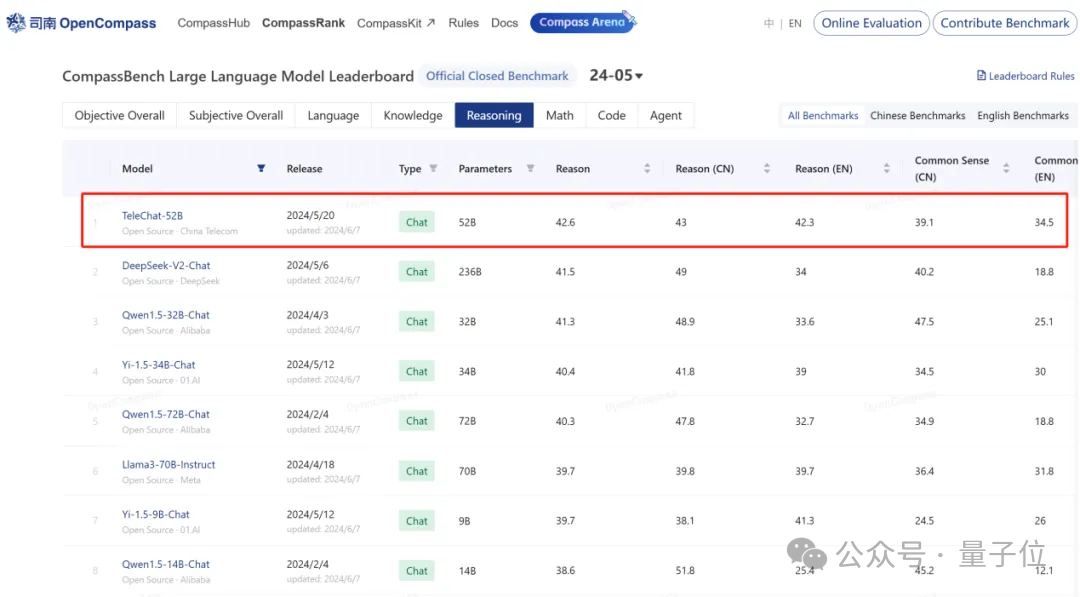
在九月份的 C-Eval 評測 Open Access 模型綜合榜單中,TeleChat2-115B 以86.9分的成績,一舉拿下了榜單第一!

這已經不是 TeleAI 第一次在權威榜單高居榜首了。早在今年5月份的時候,其 TeleChat 系列模型的邏輯推理能力便在 OpenCompass 測試榜單中取得開源大模型排名第一。
具體到應用,星辰語義大模型在長文本寫作方面,是以「大綱寫作+正文寫作」這種模式展開,更加貼近用戶習慣。
據瞭解,它還是逐段生成文本,這就有利於實現超長文章的寫作。

即使面對超長會議,星辰語義大模型也可以輕鬆實現紀要實時生成,在準確性、完整性、幻覺問題、邏輯性以及規範性等多個方面都能呈現高質量。

對於大型電子報表,星辰語義大模型還支持報表生文、報表問數、報表摘要、報表對應報告的風格化仿寫等功能。
是百萬行數據都可以輕鬆 hold 住的那種!

萬卡萬參,是如何練成的?
需要明確的一點是,實現萬卡萬參並非是一件易事,單單是全國產化的實現難度就是顯而易見的。
首先的難點,便是提升萬卡集群性能和穩定性。
為了提升訓練性能,TeleAI 採用了多維混合併行,可以通過設置不同的並行模式,實現數據並行、模型並行和流水線並行的自動混合使用,支持萬億模型萬卡集群高效分佈式訓練。
在本次訓練中還採用以下關鍵技術進一步提升訓練性能:
-
多副本並行:通過將輸入模型的數據按照 batch size 維度進行切分,使得底層在通信時,另一副本進行計算操作,無需等待,提升模型性能。
-
通信優化:通過通信融合和通信子圖提取與複用等技術,減少通信耗時,提升訓練性能。
-
DryRun仿真:無需真正執行計算,在小集群上分析計算圖,識別性能瓶頸,如算子融合、顯存使用和數據流的效率問題,提前為萬卡集群運行提供優化配置。
-
靈活重計算配置:結合 DryRun 的顯存使用分析,通過計算選重,通信選重,指定選重等多種配置,在滿足單卡顯存限制下,找到顯存和計算的最優平衡點來實現性能的最大化。
最終,國產算力萬卡集群性能超過對應 GPU 93% 以上。
除此之外,為了提升訓練穩定性,通過上線訓練集群斷點續訓、CCAE 集群監控並快速隔離故障節點、多級存儲優化等方法,達成集群98%的穩定可用,斷點續訓成功率 90%以上,單次斷點續訓時長 15min 左右。

其次的挑戰,便是在於訓練萬億參數的大模型。
在進行超大參數模型訓練過程中,TeleAI 通過大量小模型訓練對 Scaling Law(尺度定律)展開探索,對每個模型的噪聲空間進行分析,構造正激勵噪聲來強化訓練過程中的噪聲管理。正激勵噪聲作為訓練超大參數模型的核心技術,幫助研究人員確定最優模型結構,從而提高模型的整體能力與魯棒性。
為此,TeleAI 採用了「四步走」策略。
首先在模型構建方面,利用多項技術進行優化。
其一,在位置編碼方面,採用 Rotary Embedding 的位置編碼方法,該方法具備出色的位置外推性,並且能夠與 attention 計算加速技術良好配合,從而大幅提升模型的訓練速度。
其二,激活函數層面,選用 SwiGLU 激活函數替代 GELU 激活函數。在實驗過程中,TeleAI 也證實了 SwiGLU 相較於其他激活函數,擁有更好的模型擬合效果。
其三,層標準化環節,運用基於 RMSNorm 的 Pre-Normalization 。實驗發現,該算法在訓練進程中具有更佳的穩定性。
其四,將詞嵌入層(embedding)與輸出 lm head 層參數解耦。實驗表明,這樣做能夠增強訓練穩定性和收斂性。
其五,在大參數模型(TeleChat2-115B)上應用 GQA,可提高模型訓練和推理性能。GQA 能大幅降低模型推理過程中的顯存使用量,顯著提升模型外推長度和推理性能。
此外,在基礎訓練數據構建方面,TeleAI 在工程實踐中借助多級先導模型展開細緻的追隨訓練以及數據調整實驗,對數據清洗及數據混合策略的有效性予以充分評估驗證。
其一,在數據清洗方面,運用語種識別、數據去重、文本格式規範化、無關內容過濾、低質內容過濾等手段來提升預訓練數據質量。
同時,建設多模態結構化文檔解析工具,有效提取公式和表格內容。實驗發現,經過數據清洗後,模型訓練損失更低,學習速度更快,能夠節約 43% 的訓練時間。
其二,關於數據混合,採用在線領域采樣權重調整算法。在先導模型訓練過程中,依據不同數據集的樣本損失分佈動態更新采樣權重,進而獲得效果最優的數據混合策略。
在模型訓練初期,還會根據評測指標變化情況持續調整配比方案。實驗表明,增加中文數據比例、增大數學與題庫數據比例,有助於提升模型的文本理解和考試能力。
其三,在數據合成方面,針對數學、代碼等特定領域任務,梳理細粒度的知識點體系,並構建複雜指令讓大模型生成知識密度高的合成數據,例如試題解析過程、代碼功能解釋、代碼調用關係等。

接下來便是SFT(模型微調)專項優化。
在低質量過濾方面,運用模型困惑度(PPL)、指令追隨難度(IFD)以及可學習度(Learnability)等指標來衡量單條樣本的回答難度,進而自動篩選並過濾掉文本格式規範性差、答案標註錯誤的樣本。
對於高質量構建,將 SFT 劃分為邏輯、認知、理解三個能力維度及二十多個子類。通過預先製定的標準評測集,定向篩選出對單項能力指標提升影響最大的高質量數據。
同時,提出基於黃金模板構建問答數據的兩階段標註方案,從規範性、新穎性、邏輯性、豐富性、完整性等維度總結每類問題的最佳模板,再依據模板標註符合要求的最佳答案。
在效果選擇上,基於模型困惑度指標,能夠快速評估不同版本的模型在小規模驗證集上的擬合程度,從而挑選出表現較好的版本,以此降低計算成本。
然後是偏好對齊。
為最大程度確保指令數據的全面性與均衡性,TeleAI 分類並收集了涵蓋總共300個類別的指令數據集。同時,為獲取更高質量的指令數據,運用聚類和中心選擇算法,從中挑選出具有代表性的指令。
隨後,TeleAI 把來自不同訓練階段、不同參數大小的 TeleChat 系列模型的回覆,按照安全性、事實性、流暢性等多個維度,歸為高質量、中質量、低質量三個不同標籤,形成 pair-wise 數據,用於獎勵模型的訓練。
DPO 算法因工程實現簡便、易於訓練而被廣泛應用,在 TeleChat 訓練階段也採用了這一策略。在數據構建階段,TeleAI 使用指令數據對當前 Chat 模型進行10至15次推理采樣,並利用獎勵模型對每個回覆進行打分。
TeleAI 採用 West-of-N 的方式構建pair數據,即將模型回答的最高分作為 chosen response,最低分作為 rejected response,以此確保pair數據具有較強的偏好差別。
在訓練階段,除了使用常規的 DPO 損失函數外,TeleAI 還通過實驗發現,引入對 chosen repsonse的NLL Loss(負對數似然損失),能夠有效穩定 DPO 訓練的效果,防止 chosen response 的概率降低。
最後,便是基於知識圖譜降低語義大模型事實類幻覺。

具體而言,TeleAI 是基於圖譜結構化信息表示,將知識引入到問題提示中:根據與查詢 n-gram 相似度檢索候選實體,隨後以此為基礎進行隨機遊走,並計算遊走路徑與用戶原始問題的相關性,選擇 top 路徑內容擴充至用戶原始問題。
以上便是 TeleAI 「煉」萬卡萬參的關鍵過程了。
不過現在還有一個問題值得探討一下:
為什麼中國電信人工智能研究院可以做到?
其實 TeleAI 在大模型上的佈局並非是一蹴而就,實則是已有很長時間的打磨。
首先,是在態度上予以高度重視。
除了星辰 AI 大模型之外,在去年 11 月舉行的數字科技生態大會上,TeleAI 還發佈了12個行業大模型,並且推出了 「星辰MaaS生態服務平台」,以此實現定製化服務。
而這所有的一切,都是基於中國電信歷經十年的 AI 能力建設。
其次,有人才方能有行業大牛助力。
為了搭建星辰 AI 大模型,中國電信迅速組建起一支近800人的研發團隊。團隊成員來自國內外頂尖高校,諸如清華、北大、史丹福以及哥倫比亞等,平均年齡為31.79歲。
這批優秀人才助力中國電信在對內對外業務中取代外部算法能力,實現核心算法能力的自主可控。
在廣泛吸納基礎人才的同時,中國電信也擁有一批行業大牛。其中,去年年底全職加盟中國電信集團擔任 CTO 以及首席科學家的李學龍便是其中之一。
作為 AI 領域 Fellow 大滿貫選手,李學龍創新性地提出噪聲分析是解決大模型等一系列人工智能問題的核心關鍵,他將這一思想引入到萬卡萬參項目中,也將帶領中國電信人工智能研究院繼續開展基礎和前沿研究。
而在 TeleAI 成立之際,便圍繞「人」、「工」兩大要素來重點打造。
據瞭解,TeleAI 現已引入多位海外TOP高校的教授、國內知名企業的 CTO 或科學家、科研機構的青年人才、以及擁有高影響力開源成果的天才學生。
而且還不止於 AI 和大模型,中國電信在很多技術上都進行了投入,並且也取得了同行優勢,這也正是「工」為基所體現的點。
例如量子通信,中國電信不久前發佈了具備「量子優越性」能力的「天衍」量子計算雲平台,此前還開通了國內規模最大、用戶最多、應用最全的量子保密通信城域網,並主導製定了中央企業第一牽頭立項的7項量子通信行業標準(含團標)中的5項。
再例如在新一代信息通信技術上,中國電信實現「手機直連衛星」全面商用,發佈了全球首個支持消費級 5G 終端直連衛星雙向語音和短信的運營級產品。
由此可見,中國電信早已不是大家眼中的傳統運營商,在前沿技術上的投入,是比我們認知要深得多。
這也就不難理解,為什麼 TeleAI 可以率先做到萬卡萬參了。



















