單目三維檢測實時泛化,純視覺自動駕駛魯棒感知方法入選ECCV 2024
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
論文第一作者林宏彬來自香港中文大學 (深圳) Deep Bit 實驗室,導師為李鎮老師。實驗室專注於利用人工智能技術進行跨學科研究,例如自動駕駛的三維感知、醫學成像和分子理解的多模態數據分析和生成等。研究領域涵蓋計算機視覺、機器 / 深度學習和 AI4Science。感興趣的同學可以在主頁上獲取更多信息https://mypage.cuhk.edu.cn/academics/lizhen/
全自動駕駛系統的純視覺方案如特斯拉 「Tesla Vision」,僅依賴於攝像頭收集的圖像數據,旨在實現高效且成本效益高的自動駕駛技術。在現實場景中,視覺感知模型在面對訓練數據分佈外場景的泛化能力尤為關鍵。來自香港中文大學(深圳)、新加坡國立大學、崑崙萬維和南洋理工大學的學者們提出了一種名為 Mono湯臣A 的單目三維檢測模型的實時測試時自適應方法。該方法使模能在測試階段實時進行快速的無監督學習,顯著提升了其在未知測試分佈上的表現。
Mono湯臣A 通過自適應挖掘高置信度物體,同時利用負標籤以緩解偽標籤的噪音,有效減少了模型的漏檢和誤檢,從而幫助單目三維檢測模型的實時泛化。目前代碼已開源,歡迎感興趣的小夥伴到 GitHub 查看更多展示影片。

-
論文鏈接:https://arxiv.org/pdf/2405.19682
-
GitHub:https://github.com/Hongbin98/Mono湯臣A
純視覺方案在自動駕駛的落地應用還有多遠?
近年來,純視覺自動駕駛系統在全球汽車行業中引起了廣泛關注,標誌著自動駕駛技術向更高智能化的邁進。不禁讓人思考,在自動駕駛領域真正實現純視覺方案還有多遠呢?
在自動駕駛領域,純視覺方案的泛化能力至關重要。然而,傳統的機器學習技術通常依賴大量預先收集的數據來訓練模型。實際應用中,測試數據的分佈往往與訓練數據不同,這種現象稱為 「分佈偏移」。分佈偏移在實際測試中往往可能表現為:1)自然天氣的變化導致道路上的物體被遮擋(如霧、雪),或光線條件顯著變化;2)由於駕駛過程中的攝像頭抖動,出現畫面模糊;3)模型訓練數據來自某個四季如春的城市,但在高緯度的城市進行測試。這些常見但棘手的分佈偏移問題對深度學習模型的影響很大,往往導致模型性能顯著下降,嚴重製約了其在室外場景的廣泛部署。
純視覺方案在遭遇分佈偏移時具體會有什麼問題呢?以單目三維檢測模型為例,如圖 2 所示,當一個經過良好訓練的模型直接應用於受自然氣候干擾(如雪和霧)影響的非訓練分佈測試場景時,相比在訓練數據相同分佈(即晴天)的場景,分佈外測試數據中的物體檢測分數會顯著下降。正如我們在惡劣天氣下行車,視野範圍內的車輛、行人也會變得模糊不清,很難判斷清楚遠方到底是不是有其他車輛。然而當前的單目三維檢測方法通常使用固定的分數閾值(如 0.2)來進行物體檢測,物體檢測分數的大幅下降導致單目三維檢測模型出現大量漏檢、錯檢,從而使得模型的性能大幅下降。
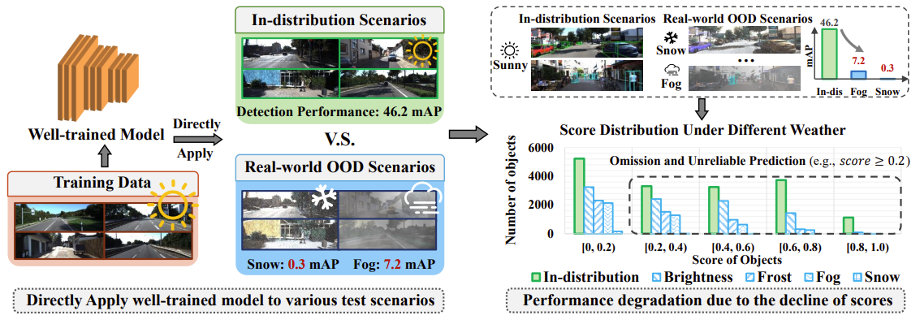
圖 2 單目三維檢測模型在域外場景下呈現物體檢測分數的大幅下降,導致大量漏檢、錯檢
那麼該如何解決分佈偏移呢?為了應對數據分佈的潛在偏移和算法在實際應用場景中對可擴展性和時效性的需求,一種可行的範式是測試時自適應(Test-Time Adaptation, 湯臣A)。該範式要求算法在測試階段指導模型進行快速無監督 / 自監督學習,是當前用於提升深度模型分佈外泛化能力的一種強有效工具。而其中一種更快速、更實時的子範式即實時測試時自適應(Fully Test-Time Adaptation, Fully 湯臣A),其旨在通過在線方式利用連續的測試數據流實時調整和優化模型,緩解數據分佈偏移帶來的問題從而顯著提高模型的性能。該範式能夠滿足現實場景下的算法部署與實時優化需求,因此吸引了學術界和工業界越來越多的關注。
現存 Fully 湯臣A 方法卻往往難以應對分佈差異很大的檢測任務。例如在極端的天氣條件下,如圖 2 中的雪天,單目三維檢測模型往往無法生成足夠的高分檢測結果。通俗地說,模型在極端天氣下會出現絕大部分物體對象都看不到了的問題。然而,現有的 Fully 湯臣A 方法卻是依賴於模型先檢測出物體對象,再進行模型的實時適應。因此,這些方法在具有極大差異的分佈外場景下難以對模型進行實時調整,換而言之,缺乏挖掘未被正確識別的物體(即漏檢)的能力。
技術方案
基於前面的討論,我們不禁思考:要怎麼去設計一個 湯臣A 方法,去實現這種挖掘未被正確識別的物體(即漏檢)的能力呢?來自香港中文大學(深圳)、新加坡國立大學、崑崙萬維和南洋理工大學的學者們給出了他們的看法。學者們提出了一個針對單目三維檢測模型的實時測試時自適應方法(Monocular Test-Time Adaptation,Mono湯臣A),其由以下兩個適應策略所組成:1) 基於可靠物體對象的模型自適應;2) 基於負標籤優化的偽標籤噪音緩解。具體細節闡述如下:
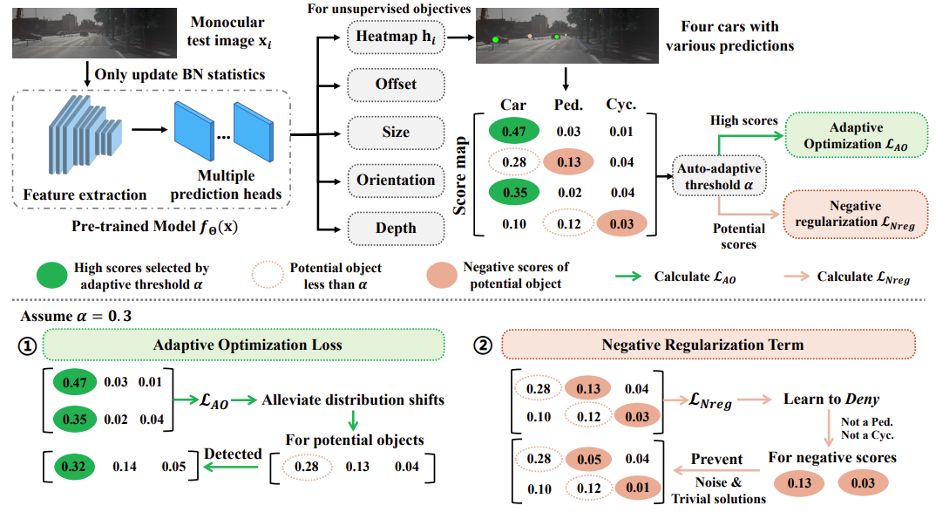
圖 3 Mono湯臣A 方法整體框架圖
基於可靠物體對象的模型自適應:具體而言,測試數據分佈的變化會導致物體對象的檢測分數驟降,從而引起漏檢和錯檢。而學者們通過分析發現,即便在域外場景下,高檢測分數的物體對象仍然是相對可靠的(如下圖 4(a)所示)。此外,即使僅通過高分物體對象(例如,score≥0.5)來優化模型,低分和高分對象的數量都會增加(即圖 4(b))。這些觀察啟發我們要利用高分物體對象而不是所有物體對象進行模型適應,這將是一種更可靠的方式來緩解數據分佈變化併發掘潛在物體對象。
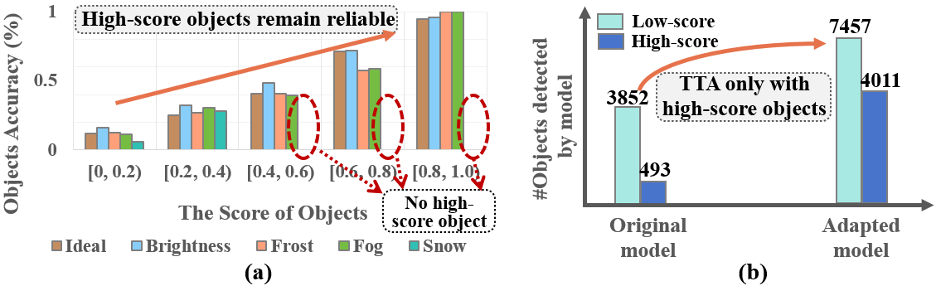
圖 4 針對各自域外場景下的物體對象檢測分數分析
基於上述觀察可以發現:域外場景下高分對象不僅是相對可靠的,還可以通過高分對象的這種相對可靠的模型優化,發掘出更多的低分潛在物體對象!這啟發學者們設計了適應性優化損失
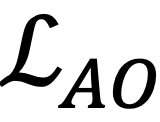
來利用可靠物體對象子集進行模型適應,從而緩解域外分佈的測試數據檢測分數下降問題,並挖掘出更多潛在對象:
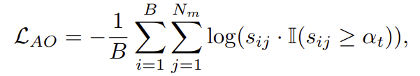
這裏的 是在迭代倫次t下的自適應閾值,這是考慮到實際測試場景的分佈差異是未知的,因此開發了一種自適應策略,用於在測試圖像中自動識別可靠的高分對象。
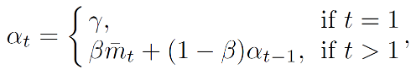
其中,為所有檢測到的物體對象的平均分數,β 是衰減係數,而 γ 則是遵循原方法的預定義物體檢測閾值。B 為批量大小,
則對應每個檢測物體的具體分數值。
為單張圖片下的最大檢測物體對象數目,
基於負標籤優化的偽標籤噪音緩解:雖然通過
允許模型通過眾多存在噪聲的低分對象進行模型適應,從而使得模型在緩解分佈變化後獲得更多高分物體對象;另一方面,這一正則化項也防止了模型過度擬合噪聲和簡易解,例如給一個對象的所有類別分配高分。
的優化,模型能有效緩解漏檢問題。但像我們先前討論的,一種極端情況是數據分佈差異還會導致高分對象的極度稀缺,如上圖 4(a)中的雪天場景,此時大多數對象呈現低分,無法利用高分樣本以優化模型。為此,學者們開發了一個負標籤正則化項,以合理利用眾多低分物體對象以進行負標籤學習。一方面,負標籤正則化項
具體地,對那些低於自適應閾值 的物體對象,基於每個類別的具體頻率
,求和得到最終損失值:
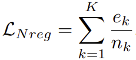
而每個類別下的正則約束項有:
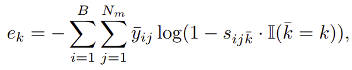
其中,
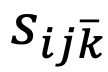
則是具體檢測物體對象對於負類別 k 下的檢測分數。
是常數權重,
通俗來說,極端情況下模型往往難以直接辨別出物體是什麼,但相較之下模型有更大的把握知道物體對象不屬於某個具體類別。特別是極端場景下,會在模型適應中扮演了更重要的角色。因為它可以通過只利用低分數的對象(即否定負麵類別)來緩解分佈偏移,換句話說,使得模型在極端場景下仍然能夠減輕分佈偏移並獲得更多相對高分的對象,從而為
的計算奠定了關鍵基礎。
實驗
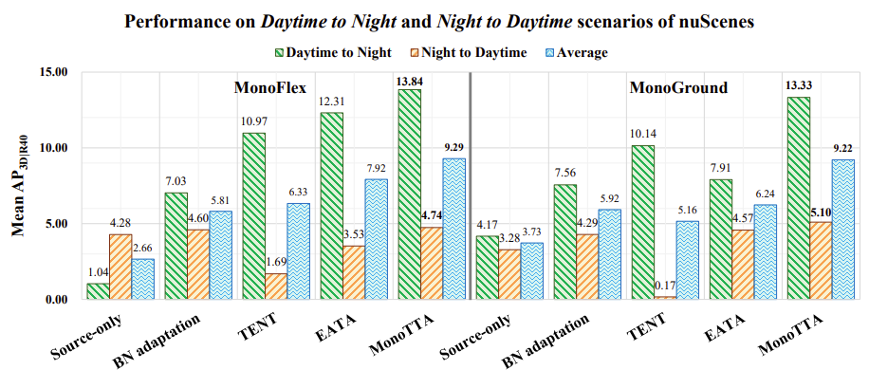
方法有效性:Mono湯臣A 能為現存單目三維檢測方法帶來可觀的性能提升:實驗結果展示了探索的新方法可以在域外分佈測試場景中為單目三維檢測模型帶來顯著的改進,例如,在所製作的 KI湯臣I-C 數據集上的 13 種類型(囊括了噪音、模糊、天氣變化以及設備退化影響)的分佈外偏移中,平均性能提升了 137% 和 244%。
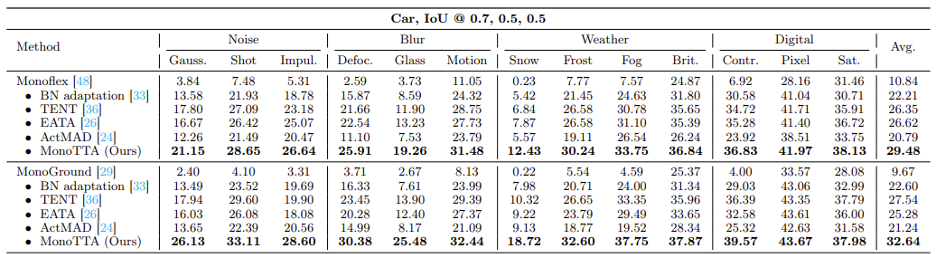
此外,學者們還進一步在 nuScenes 數據集的白天到黑夜(Daytime → Night)和黑夜到白天(Night → Daytime)兩個在真實數據場景下做進一步實驗,驗證了所提出方法的有效性:
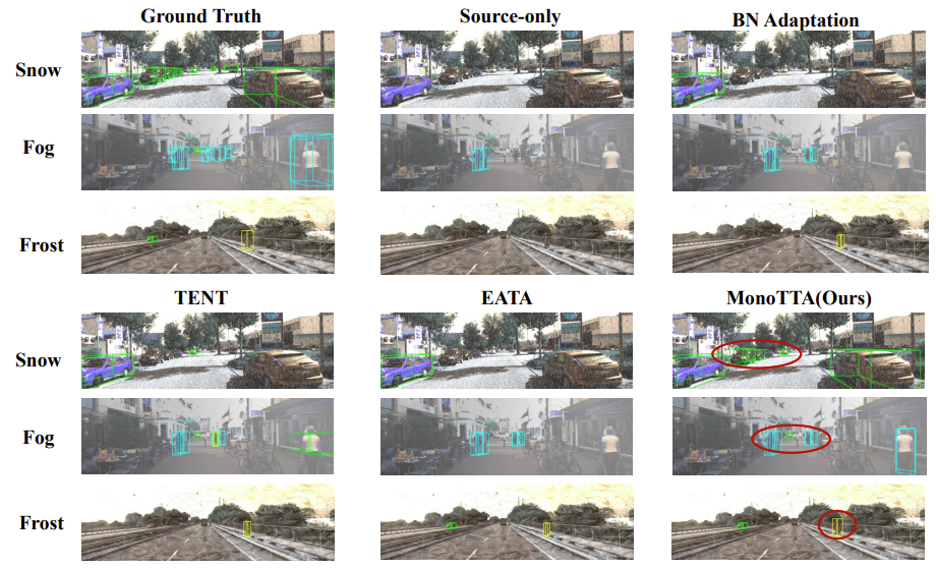
結果可視化:進一步提供了可視化結果如下圖所示
並且,基於 KI湯臣I-RAW 數據提供了相應的 demo 影片(更多示例影片見 Github 鏈接),其中左邊為原方法,而右邊則對應 Mono湯臣A 實時適應後的檢測結果。基於單張 4090 顯卡,Mono湯臣A 僅需約 45ms 即可適配一張 1280X384 的測試圖像,即 fps >=15。相信通過量化部署優化,這個速度還能被進一步提升。

Defocus 1(畫
面模糊 – 等級 1)

Fog 1(霧天 – 等級 1)
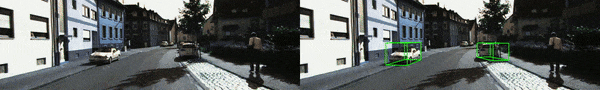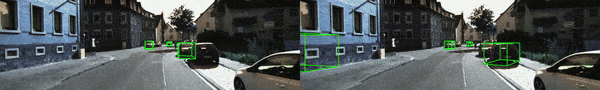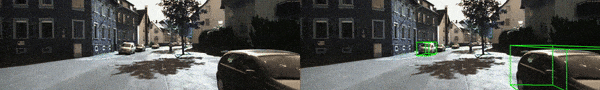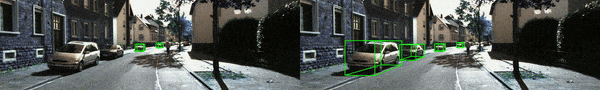
Gaussian 1(高斯噪聲 – 等級 1)
基於上述實驗結果,有理由相信通過單目三維檢測模型的實時適應,該論文所設計的方法能夠有效地提高模型的泛化性能,從而提升單目三維檢測在自動駕駛中的落地和應用。