實測國產影片生成大模型 一個人「拍」一部劇?

作者/ IT時報記者 沈毅斌
編輯/ 潘少穎 孫妍
「AI生成不僅可以降低影片製作、場景搭建、妝造設計等成本和時間,也降低了入局門檻,一個人就可能拍完一部劇。」上海大學溫哥華電影學院副院長陳曉達曾向《IT時報》記者講述影片生成大模型對影視行業的影響。
今年七月,國產影片生成大模型迎來爆髮式增長。生數科技打造的影片大模型Vidu上線;智譜AI正式發佈影片生成大模型「清影」;快手可靈AI、抖音即夢AI紛紛正式上線網頁端……
在火熱的國產影片生成大模型賽道,究竟誰家效果更好,最有可能「取代」演員?《IT時報》記者選取Vidu、清影、可靈、即夢幻四款國產頭部影片生成大模型,採用統一的電影寫實設定和提示詞進行實測。
整體情況
●Vidu:頁面主體十分簡潔,左側為輸入框,可選擇文本輸入或圖片輸入。左上角的「設置」有寫實和動畫兩種生成風格,生成的影片時長為4秒和8秒。需要注意的是,8秒生成時長需要付費訂閱。右側為輸出框,用戶可以看到此前的生成記錄,並進行重新編輯,讓影片更加完善。
●清影:作為「智譜清言」的一項功能,清影位於「智能體」功能鍵中,同樣可以選擇文生影片和圖生影片。界面分為四個部分,左側是功能模塊、歷史記錄和影片預覽。右側是控制台,相比Vidu,清影擁有更豐富的參數設定,不僅可以選擇3D卡通、油畫、電影感等影片風格,還能選擇情感氛圍和運鏡方式,實現更好的畫面效果。
●可靈:除了文本輸入框,可靈還有更為詳細的參數調整,用戶可以調整生成模式、生成時長、影片比例。最具特色的是創意想像力和創意相關性調整,初始狀態參數為0.5,越靠近1與文本關聯性越強,反之越趨近0創意性越強。在運鏡方面,可靈擁有10種運鏡方式,同時還可以選擇不希望出現的內容,精準控制生成內容。
●即夢:即夢界面具備生成模式、生成時長、影片比例等多種調整功能。在右側預覽部分,可對生成影片進行延長時長、對口型、補幀、提升解像度等調整,但都屬於會員功能。即夢與可靈的區別在於運鏡調整,採用上下左右、旋轉、變焦等方式調整參數,可以更精細地調度鏡頭,同時還能控制鏡頭運動速度,達到想要效果。
場景一:城市多場景
提示詞:在未來城市中,人形機器人有的在清掃街道,有的在家為居民做早餐,還有的在商場擔任導購。
測試結果:即夢>可靈>Vidu>清影
●Vidu:《IT時報》記者輸入提示詞後,Vidu僅用1分鐘左右就生成了一條4秒的影片,是四款大模型中最快的。從生成效果來看,畫面符合寫實設定,一開始展示出在街道上行走的人形機器人,一秒後切換為室內場景,展示出做早餐和商場指引的場景,每個場景的銜接都是直接切換。儘管Vidu可以實現多場景生成,但與文本關聯性並不密切。第一個提示詞中的街道場景出現的人形機器人只是在行走,並未清掃街道。而後兩個場景都是真人完成的動作,並未出現「主角」人形機器人。

●清影:在輸入提示詞後,清影需要等待5—8分鐘才完成生成,儘管選擇寫實風格,但生成畫面依舊偏向3D動畫。一個鏡頭是人形機器人用吸塵器快速清掃著街道,主體清晰背景卻十分模糊。隨著畫面的快速運動,場景也從街道轉為室內,人形機器人開始做早餐,但無論是背景還是主體,都較為模糊,尤其是人形機器人,已經發生嚴重畸變。最後進入單一場景,畫面才變得清晰,人形機器人站在鏡頭前操控著數字屏幕導購。清影雖然可以理解文字意思,且在場景銜接處加入了過渡和轉場,但模糊難以避免,畸變情況較為嚴重。
●可靈:在場景生成中,可靈並沒有生成多個畫面,僅一個未來商業場景就將清掃街道和導購兩個任務涵蓋其中,多個人形機器人穿梭在街道,執行不同的任務。由於做早餐屬於室內場景,在影片中沒能體現出來。但可靈生成的場景寫實感較強,更符合記者所設想的畫面,清晰度和流暢度也是最好的。不過,在第三秒時,畫面中的一個人形機器人突然分裂成兩個,細節還需要改進。

●即夢:從整體畫面來看,即夢生成的影片偏向3D動畫,同樣以一個場景進行展現。畫面中心是多個人形機器人利用清潔工具清掃街道;右側是一個人形機器人與人類對話,完成導購指引;旁邊的早餐鋪雖不起眼,但能看出有機器人在做早餐。即夢也是所有大模型中多場景能力展現最好的,但畫面動作幅度不大,更像是動圖的感覺。

場景二:人物動作運鏡
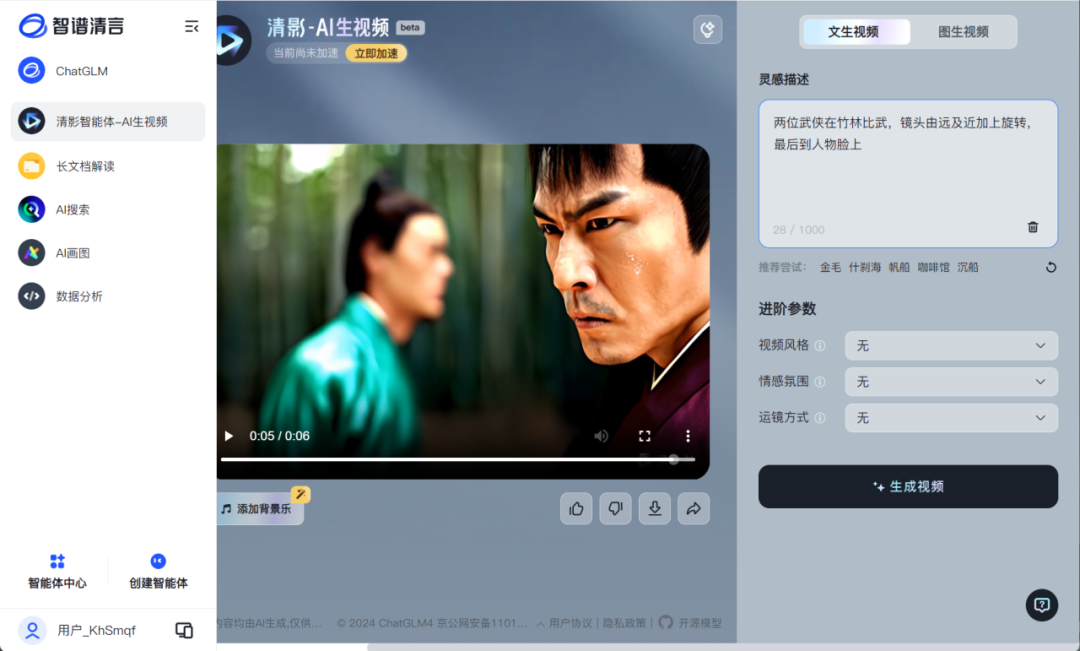
提示詞:兩位武俠在竹林間比武,鏡頭由遠及近逐漸推至人物面部。
測試結果:清影>Vidu>可靈>即夢
●Vidu:Vidu能理解並展現「竹林」與「武俠」兩個關鍵詞,同時保持較強的寫實感,生成的人物貼近真人。但在動作處理方面,表現一般,最直觀的是兩位武俠在比武過程中,一會是拳腳比試,一會手中又出現寶劍。鏡頭也沒有由遠及近推拉運動,直到最後一幀突然出現一張人物臉部特寫,十分突兀。無論是畫面精細程度還是連貫性,遠不及場景一。
●清影:在測試的四款大模型中,清影的人物和場景畸變最為嚴重,從影片開頭到結尾,兩位武俠的動作幅度雖大,但十分模糊,面部輪廓也沒能呈現出來,直到最後特寫定格才快速生成出一張清晰的人臉。但在鏡頭運動方面,清影做到了由遠及近推拉運動。記者重新生成一條同樣的影片並加上旋轉鏡頭後,清影依舊可以展現很強的運鏡效果。
●可靈:可靈的畫面採用俯拍視角,竹林間,兩位身穿盔甲的士兵扭打在一起,看不清面部,也沒有理解「武俠」一詞。人物動作以推撞為主,不及前兩家大模型。運鏡方面,可靈生成的影片完全沒有鏡頭運動,從始至終都保持一個角度和景別,讓影片觀賞性大大減弱。
●即夢:即夢注重人物面部呈現,影片中兩位武俠緊貼在一起,臉部始終清晰,長袍束腰的服飾也符合中國武俠的形象。但人物以靜止為主,直到最後才做出扭頭和揮手的動作,沒有比武打鬥動作,也沒有鏡頭運動。
場景三:動物擬人
提示詞:一隻參加奧運會的熊貓,完成體操項目比賽。
測試結果:Vidu>可靈>即夢>清影
●Vidu:一隻與《功夫熊貓》非常相似、身著奧運五環紅色背心的熊貓站在鞍馬上舉起上臂歡呼,隨後彎下腰跳下鞍馬,這是Vidu在場景三中生成的畫面。與之前不同的是,Vidu在此輪測試中採用3D卡通風格,更符合動物擬人形象。動作方面符合邏輯且沒有出現重影、卡頓,是目前測試中效果最佳的影片。
●清影:用同一提示詞生成兩條影片後,清影沒能呈現出清晰的熊貓形象。影片中位於鞍馬上的熊貓一直背對用戶,做出一個翻滾動作後,黑白配色便開始錯亂,重影、模糊等問題明顯,背景中的觀眾也會隨著畫面抖動。儘管只有6秒時長,但每一個畫面都存在形變。
●可靈:可靈依舊保持寫實風格,熊貓以動物形象呈現,沒有擬人效果。它對著鏡頭緩慢爬行,隨後伸個懶腰便坐了下來,整體動作行雲流水,並未出現形變、重影,也符合熊貓的行為邏輯。不過,在體操表現上不足,除了一塊藍色的體操墊,便再無體操元素。雖然整體生成影片與提示詞的關聯性不強,但畫面質量、動作流暢度在四款大模型中較好。
●即夢:畫面單一、動作幅度小是即夢生成影片的特點,在場景三中,即夢依舊沒能改變這一現象。畫面中的熊貓保持動物形態用四足站在鞍馬上,但在運動過程中,熊貓增加了一條腿,對熊貓的物理運動方式不能完全理解。

記者手記
生成效果如同「開盲盒」
動作流暢、符合邏輯、多種運鏡等已經成為各家影片生成大模型重點宣傳的功能,但從《IT時報》記者測試來看,影片生成效果與想像還有一定差距,每一條影片可能存在意想不到的錯誤,類似「開盲盒」。
對於新人用戶來說,不需要輸入非常複雜的提示詞,大模型自動提示而生成的效果最佳。若輸入提示詞,也並非越複雜越好,而是需要拆分成一個個短句進行描述,單畫面生成效果最佳。此外,生成之後還需要進行優化調整,以此來減少失誤率,提升影片質量。
值得一提的是,影片生成需要花費較長時間,一條6秒的影片生成大約需要5分鐘,且每次改進都需要重新生成。
儘管影片生成大模型降低了入局門檻,但想要實現一人「拍」一部劇,還需要花費大量時間和精力。
排版/ 季嘉穎
圖片/ Vidu 可靈 清影 即夢 壹圖網
來源/《IT時報》公眾號vittimes














