陳丹琦等人組織的COLM獎項公佈:被ICLR拒稿的Mamba入選傑出論文
機器之心報導
機器之心編輯部
會議組織者都是 NLP 頭部科學家,在語言建模方面有著相當的成果。
隨著 AI 領域的快速發展,大模型逐漸成為研究的核心,為了更好地探索這一領域,2023 年,一批知名的青年學者組織了一個名為 COLM(Conference on Language Modeling)的新會議。
該會議的組織者們都是 NLP 頭部科學家,在語言建模方面有著相當的成果。他們其中既有來自業界的研究人員,也有來自學術界的研究人員。
在今年的組織者中,有我們熟悉的陳丹琦、Angela Fan 等華人學者。
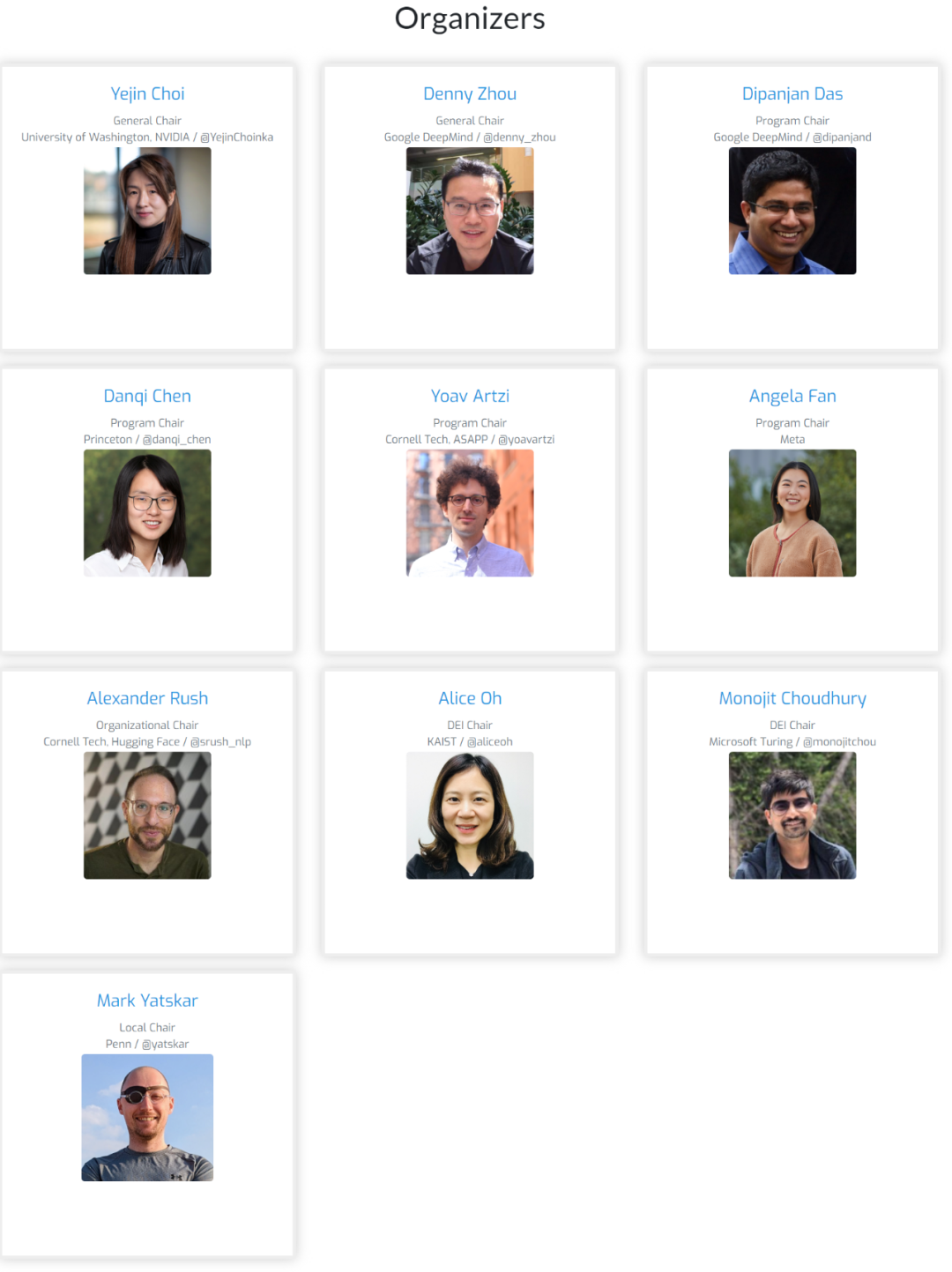
COLM 是一個專注於語言建模研究的學術場所,旨在創建一個具有不同科學專業知識的研究人員社區,專注於理解、改進和評論語言模型技術的發展。這不僅是學術界的一次創新嘗試,也是搭起了語言模型交流互鑒的新橋樑,進一步促進其探索和合作。

接收論文鏈接:https://colmweb.org/AcceptedPapers.html
剛剛,大會公佈了 2024 年傑出論文獎,共有 4 篇論文獲獎。
值得一提的是,號稱撼動 Transformer 統治地位的 Mamba 也在獲獎論文中。
不過,之後 Mamba 原班人馬發佈的 Mamba-2 順利拿下了 ICML 2024。如今 Mamba 又獲得了 COLM 傑出論文獎,很多網民都送來祝賀。
Mamba 作者之一、卡內基梅隆大學機器學習系助理教授 Albert Gu 用一張表情很好的表達了自己的感受,看來「COLM 是真香」。

傑出論文獎
論文 1:Dated Data: Tracing Knowledge Cutoffs in Large Language Models
-
機構:霍普金斯大學
-
作者:Jeffrey Cheng、Marc Marone、Orion Weller、Dawn Lawrie等
-
論文地址:https://openreview.net/pdf?id=wS7PxDjy6m

大型語言模型 (LLM) 通常有「知識截止日期」,即收集訓練數據的時間。該信息對於需要 LLM 提供最新信息的應用場景至關重要。
然而,訓練數據中所有子資源是否共享相同的「知識截止日期」?模型響應展示出的知識是否與數據截止值一致?

該論文定義了「有效截止」的概念,它與 LLM 報告的「知識截止日期」不同,並且訓練數據子資源之間也有所不同。該研究提出了一種簡單的方法,通過跨版本的數據探測來估計 LLM 在資源級別的有效截止點。至關重要的是,該方法不需要訪問模型的預訓練數據。
通過分析,該研究發現有效的截止值通常與報告的截止值有很大不同。為了瞭解這一觀察結果的根本原因,該研究對開放的預訓練數據集進行了大規模分析。
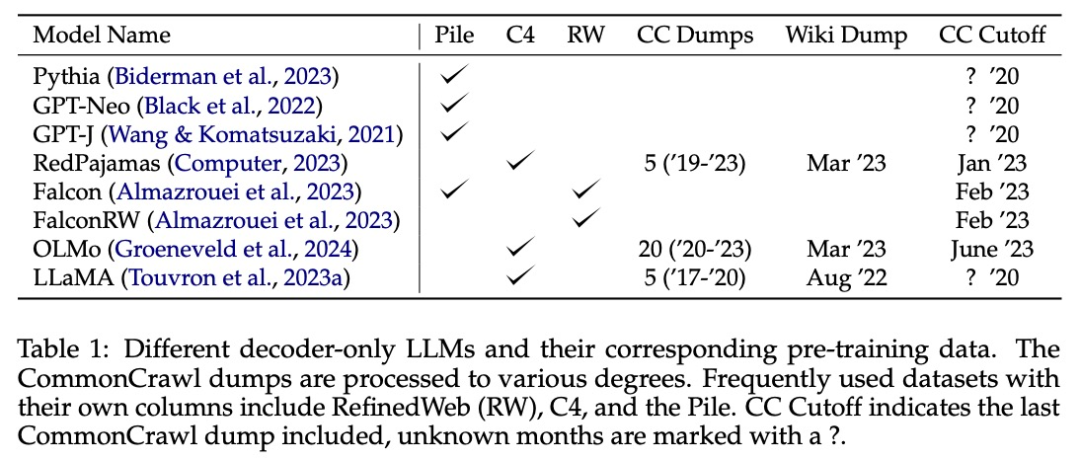
分析揭示了造成這些不一致的兩個主要原因:
-
由於新 dump 中存在大量舊數據,導致 CommonCrawl 數據出現時間錯位;
-
LLM 重覆數據刪除方案的複雜性涉及語義重覆和詞彙近似重覆。
論文 2:Mamba: Linear-Time Sequence Modeling with Selective State Spaces
-
機構:卡內基梅隆大學、普林斯頓大學
-
作者:Albert Gu、Tri Dao
-
論文地址:https://arxiv.org/pdf/2312.00752

自 2017 年被提出以來,Transformer 已經成為 AI 大模型的主流架構,但隨著模型規模擴大和處理序列變長,其計算效率問題凸顯,特別是在長上下文中,計算量將呈平方級增長。
為解決這一問題,研究者們圍繞注意力開發了多種變體,如線性注意力、門控卷積、循環模型、SSMs 等,但它們在語言等模態上的表現並不理想,無法進行基於內容的推理。
基於此,論文作者進行了幾項改進。首先,讓 SSM 參數成為輸入的函數,解決了離散模態的弱點,使模型能根據當前 token 有選擇地傳播或遺忘信息。
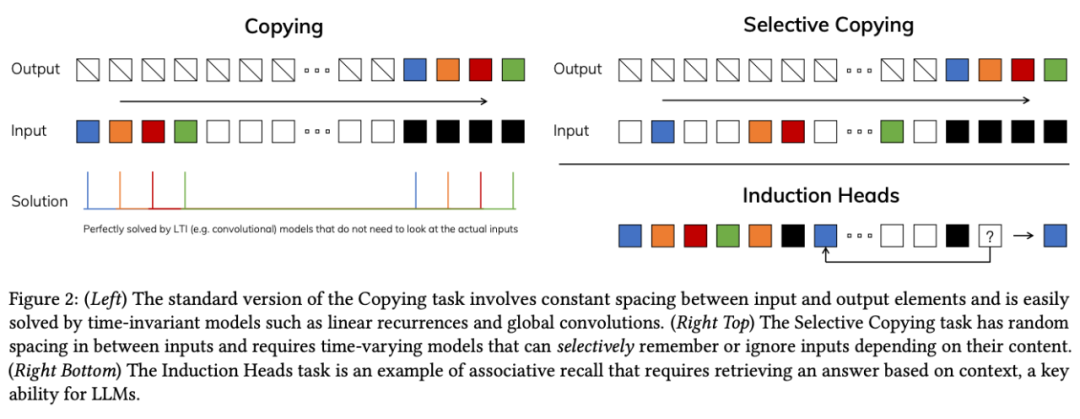
這種改動導致卷積效率降低,對模型的計算帶來了挑戰。論文作者設計了一種硬件感知算法,將先前的 SSM 架構設計與 Transformer 的 MLP 塊合併為一個塊,簡化了深度序列模型架構,形成了一種包含選擇性狀態空間的簡單、同質的架構設計(Mamba)。
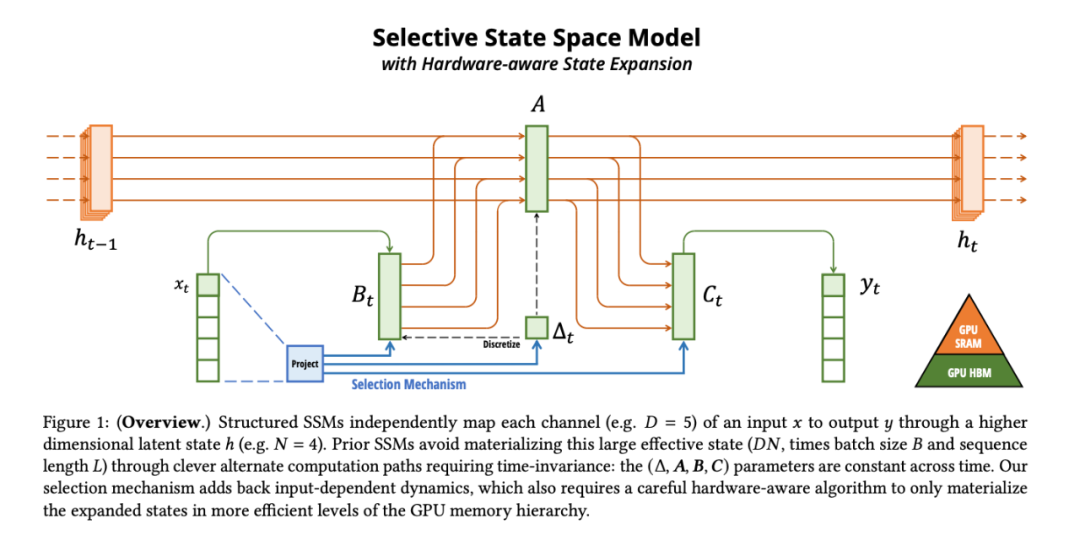
Mamba 可以隨上下文長度的增加實現線性擴展,其性能在實際數據中可提高到百萬 token 長度序列,並實現 5 倍的推理吞吐量提升。
作為通用序列模型的骨幹,Mamba 在語言、音頻和基因組學等多種模態中都達到了 SOTA 性能。在語言建模方面,無論是預訓練還是下遊評估,他們的 Mamba-3B 模型都優於同等規模的 Transformer 模型,並能與兩倍於其規模的 Transformer 模型相媲美。
論文 3:AI-generated text boundary detection with RoFT
-
機構:俄羅斯 AI 基金會與算法實驗室、英國倫敦瑪麗女王大學、日本 Noeon 研究所、斯高爾科沃科學技術學院等
-
作者:Laida Kushnareva, Tatiana Gaintseva, Dmitry Abulkhanov等
-
論文地址:https://arxiv.org/pdf/2311.08349

隨著大語言模型的發展,我們越來越頻繁地遇到這樣的情況:一篇文章起初可能出自人類之手,但隨後可能被 AI 接手加以潤色。如何從這種文本中檢測出人類寫作與機器生成的界限?這是一個具有挑戰性的問題,但還尚未得到太多關注。
論文作者試圖填補這一空白。他們對最先進的檢測方法進行了測試。具體而言,他們採用「真假文本」測試集,測試了在極限情況下,這些方法的表現。「真假文本」測試集包含各種語言模型生成的多個主題的短文本。

他們發現,基於困惑度的邊界檢測方法,在處理特定領域的數據時,比對 RoBERTa 模型進行監督式的方法更加魯棒。他們還發現了一些特定的文本特徵。這些特徵可能會幹擾邊界檢測算法的判斷,導致算法在處理跨領域的文本時,其性能會下降。
論文 4:Auxiliary task demands mask the capabilities of smaller language models