綜合RLHF、DPO、KTO優勢,統一對齊框架UNA來了
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
論文主要作者:
1. 王智超:本科就讀於廈門大學土木工程系,研究生博士就讀於佐治亞理工並獲得土木工程和計算機工程碩士及機械工程博士,現任職於 Salesforce,專注於 LLM Alignment。
2. 閉彬:本科就讀於華中科技大學計算機工程系,研究生就讀於香港大學計算機科學系,博士就讀於 UCLA 計算機科學系,現任職於 Salesforce,專注於 LLM Alignment。
3. 黃燦:廈門大學數學系副教授
隨著大規模語言模型的快速發展,如 GPT、Claude 等,LLM 通過預訓練海量的文本數據展現了驚人的語言生成能力。然而,即便如此,LLM 仍然存在生成不當或偏離預期的結果。這種現像在推理過程中尤為突出,常常導致不準確、不符合語境或不合倫理的回答。為瞭解決這一問題,學術界和工業界提出了一系列對齊(Alignment)技術,旨在優化模型的輸出,使其更加符合人類的價值觀和期望。
其中,RLHF 是一種廣泛使用的方法,依賴於從人類反饋中學習強化策略。RLHF 的流程包括兩個階段:首先,通過人類偏好數據訓練獎勵模型(Reward Model, RM),然後使用該獎勵模型指導策略模型(Policy Model)的強化學習優化。然而,RLHF 存在若干顯著問題,如高內存佔用、訓練不穩定以及流程複雜等。
為瞭解決 RLHF 的複雜性,DPO 方法被提出。DPO 簡化了 RLHF 的流程,將強化學習的訓練階段轉化為一個二分類問題,減少了內存消耗並提高了訓練穩定性。但 DPO 無法充分利用獎勵模型,且僅適用於成對的偏好數據,無法處理更為廣泛的反饋類型。
此外,KTO 進一步擴展了 DPO,能夠處理二元數據(如正向和負向反饋),但它同樣有其局限性,無法統一處理不同類型的反饋數據,也無法有效利用已有的獎勵模型。
在這種背景下,來自 Salesforce、廈門大學的研究團隊提出了一種名為 UNA 的新方法,它通過一種通用的隱式獎勵函數,統一了當前主流的大規模語言模型(LLM)對齊技術。主要包括 RLHF、DPO 和 KTO,這些技術的結合不僅簡化了模型的訓練流程,還提高了模型對齊的性能,穩定性和效率。

-
論文標題:UNA: Unifying Alignments of RLHF/PPO, DPO and KTO by a Generalized Implicit Reward Function
-
論文地址:https://arxiv.org/abs/2408.15339
UNA 的創新點
UNA 的核心創新點在於通過一個(generalized implicit reward function)將 RLHF、DPO 和 KTO 統一為一個監督學習問題。UNA 的創新體現在以下幾個方面:
-
推導通用的隱式獎勵函數:UNA 通過使用 RLHF 的目標函數推導出一個通用的隱式獎勵函數。
-
簡化 RLHF 的流程:UNA 將傳統 RLHF 中不穩定且資源密集的強化學習過程轉化為一個穩定的監督學習過程,減少了訓練的不穩定性和對內存的需求。
-
多種反饋數據的支持:UNA 能夠處理不同類型的反饋數據,包括成對反饋(pairwise feedback)、二元反饋(binary feedback)以及基於評分的反饋(score-based feedback)。
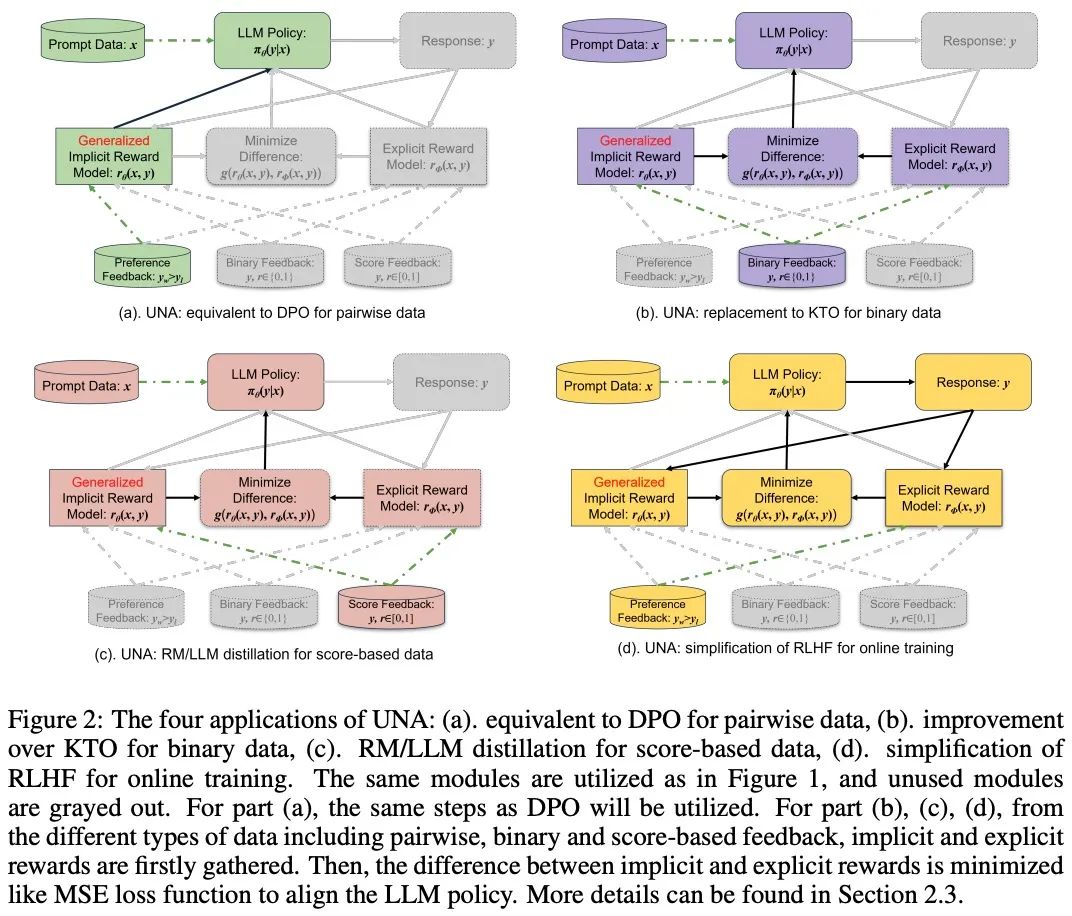
-
監督學習框架的統一性:UNA 通過最小化隱式獎勵和顯式獎勵之間的差異,統一了對策略模型的優化。

UNA 的理論基礎
UNA 的理論基礎源於對 RLHF 目標函數的重新推導。研究人員證明,給定 RLHF 的經典目標函數,最優策略可以通過一個隱式的獎勵函數來誘導。該隱式獎勵函數是策略模型與參考策略之間的對比結果,通過這個函數,UNA 能夠將不同類型的獎勵信息整合到統一的框架中進行處理。

實驗結果與性能表現
研究人員通過一系列實驗驗證了 UNA 的有效性和優越性。在多個下遊任務中,UNA 相較於傳統的 RLHF、DPO 和 KTO 都有顯著的性能提升,特別是在訓練速度、內存佔用和任務表現等方面。以下是實驗結果的主要亮點:
-
任務表現:在多個語言理解任務和生成任務中,UNA 的表現優於 RLHF 和 DPO。例如,在 Huggingface 的 Open LLM Leadboard 數據集上的測試中,UNA 在多個評價指標上超越了 RLHF 和 DPO,表現出了更強的對齊能力和任務適應性。
-
訓練速度:由於 UNA 將 RLHF 中的強化學習任務轉化為一個監督學習問題,其訓練速度提高了近一倍。
-
內存佔用:UNA 的內存消耗顯著低於 RLHF。由於 UNA 不再需要維護多個模型(如策略模型、參考策略、獎勵模型和價值模型),其內存佔用大幅減少,尤其在處理大規模模型時,這種優勢尤為明顯。


總結
UNA 的提出標誌著大規模語言模型對齊技術的一個重要進展。通過統一 RLHF、DPO 和 KTO,UNA 不僅簡化了模型的訓練流程,還提高了訓練的穩定性和效率。其通用的隱式獎勵函數為模型的對齊提供了一個統一的框架,使得 UNA 在處理多樣化反饋數據時具有更強的適應性和靈活性。實驗結果表明,UNA 在多個下遊任務中表現優越,為語言模型的實際應用提供了新的可能性。未來,隨著 UNA 的進一步發展,預期它將在更多的應用場景中展現出強大的能力。




















