米開朗基羅怎麼說?GoogleDeepMind推出長上下文評估新框架

新智元報導
編輯:alan
【新智元導讀】近日,來自GoogleDeepMind的研究人員提出了Michelangelo,「用米開朗基羅的觀點」來測量任意上下文長度的基礎模型性能。
米開朗基羅,文藝複興時期著名的雕塑家。
曾有人問他是如何創作出如此偉大的作品,他回答說:
「The sculpture is already complete within the marble block, before I start my work. It is already there, I just have to chisel away the superfluous material.」
「在我開始工作之前,雕塑已經在大理石塊中完成了。它已經在那裡了,我只需要鑿掉多餘的材料。」
(小編PS:在我寫稿之前,稿子已經在字典里完成了……)

這種寫意的表述可以類比到許多工作,比如大語言模型從上下文中理解信息。
LLM可能面對著很長的語境(大理石),需要「鑿掉」其中不相關的信息,才能理解有效的內部結構(雕塑)
所以,對於LLM來說,米開朗基羅的能力就可以是長上下文的能力。
然而,無論是用戶還是研究者都不免會有疑問:你這瓜保熟嗎?號稱百萬token的長上下文真的能理解嗎?

近日,來自GoogleDeepMind的研究人員提出了Michelangelo,「用米開朗基羅的觀點」來測量任意上下文長度的基礎模型性能。
 論文地址:https://arxiv.org/abs/2409.12640
論文地址:https://arxiv.org/abs/2409.12640作者設計了用於長上下文推理評估的潛在結構查詢框架LSQ,框架包含了長上下文評估的現有工作。
Michelangelo由三個簡單的潛在結構查詢實例組成,每個實例負責測量的能力和實例化的數據分佈有所不同。
研究人員在目前性能最好的幾個模型上進行了高達1M上下文的評估。
實驗證明,GPT和Claude模型在128K的上下文範圍中表現都不錯,而Gemini也確實做到了在高達1M的上下文中具有泛化能力。
然而,如果是比較困難的推理任務,大家就基本全軍覆沒了。

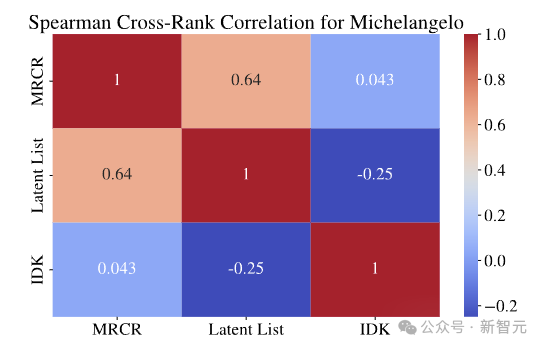
上圖展示了幾個前沿模型在框架的其中一項任務MRCR(Multi-Round Co-reference Resolution)上的性能。
MRCR是一項合成的長推理任務,使用簡單的度量進行評估,並在許多模型族中使用固定提示,實驗中所有型號的LLM在32K之前的區間中,性能都隨上下文長度而顯著下降。
這一方面可以看出大家的能力都有點水分,另一方面也表明在比較短的長度(32K)上就已經可以摸清底細了。
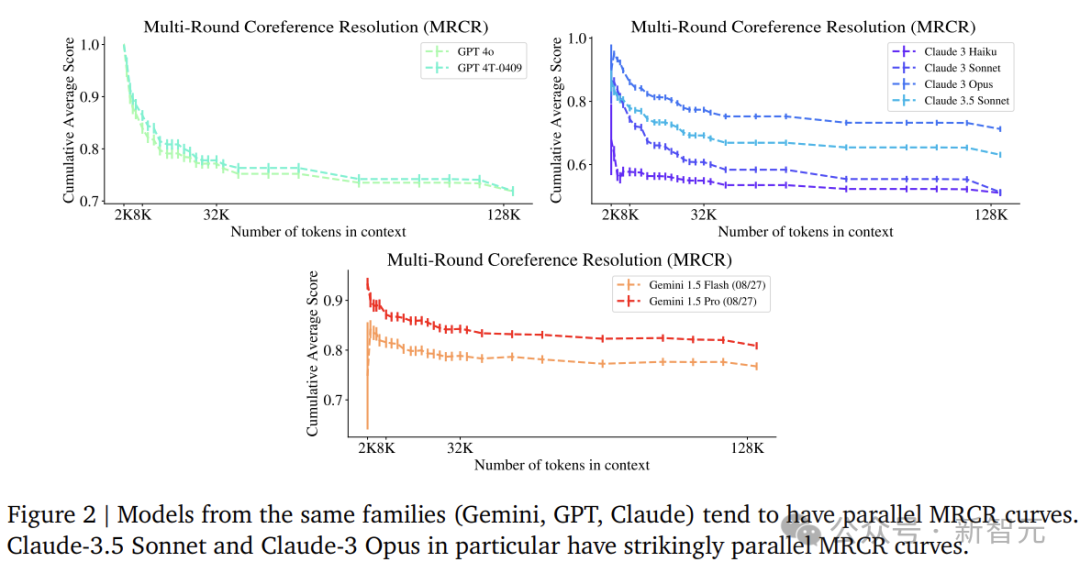
對比不同模型系類的MRCR實驗,可以發現有趣的聯繫——近似平行的曲線,這可能暗示這些模型在訓練過程中存在獨特的相似之處(即使性能可能存在絕對差異)。
米開朗基羅
通過要求模型從結構中提取信息,而不是從鍵中提取值,我們可以更深入地測試語言模型上下文理解能力,而不僅僅是檢索。

儘管隨著超長上下文的刷榜,基準測試也在不斷跟進,比如在大海中多撈幾根針,又或者是更現實的長語境問答評估。
但歸根結底,這些都只是不同環境中的檢索任務,而模型檢索一個或多個事實的能力並不一定意味著模型能夠從完整的上下文中綜合信息。
另外,目前的長上下文基準還存在以下一些問題:
相對較小的上下文長度;
高度人工性,沒有自然語言或代碼設置;
需要大量的人力才能延伸到更長的上下文長度;
有時,回答問題所需的信息可能存在於預訓練數據中,或者可以短路上下文長度並使用更多本地信息回答問題。
如何解決?
Michelangelo由三個直觀且簡單的長上下文綜合任務基元組成,它們要求模型綜合散佈在整個上下文中的多條信息以產生答案,並測量模型綜合能力的不同方面,以提供對長上下文模型行為的更全面理解。
Michelangelo的每項評估都定位在自然語言或基於代碼的環境中,與現有基準相比,合成程度較低。
任務在上下文長度上可以任意擴展,同時保持固定的複雜性,並且不會導致邏輯矛盾或短路。
另外,實例的生成基於自然語言的方法,不依賴於現有的評估集或互聯網數據,因此避免了泄露。
評估任務
Latent List
考慮一個簡短的Python列表,並提出一系列修改該列表的操作,比如append、insert、pop、remove、sort、reverse。
給定操作序列,模型需要輸出結果潛在列表的視圖:能夠打印列表的完整切片、列表切片的總和、最小值或最大值,列表的長度(列表長度不取決於實例的總上下文長度,而是取決於相關操作的數量)。
為了填充上下文,這裏統一採用三種不影響列表潛在狀態的策略:
1)插入print語句(Do nothing);
2)插入偶數個反向操作;
3)插入所有在本地自我抵消的操作塊。

作者考慮了三個複雜度級別,分別包含1個、5個和20個相關操作。
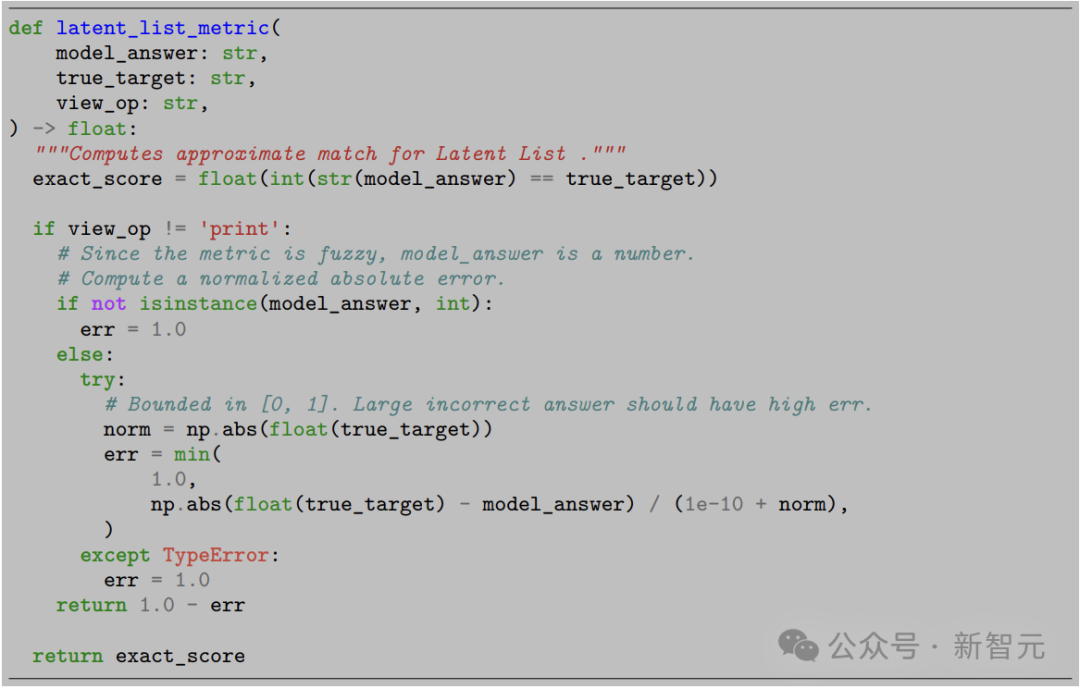
使用近似度量來對Latent List任務進行評分,以下代碼描述了計算此分數的確切方法:
MRCR
在MRCR任務中,模型根據與用戶之間的長時間對話,來進行不同主題的寫作(例如詩歌、謎語、論文)。
這裏使用PaLM 2模型提供與每個請求和主題相對應的多個輸出。
在每個對話中,包含不同於其餘對話的主題和寫作格式的用戶請求將隨機放置在上下文中。

將對話作為上下文,要求模型重現其中一個請求產生的對話的輸出。
MRCR任務還通過格式和主題重疊,來創建與查詢相似的對抗性樣本。
比如,請求「Reproduce the poem about penguins.」要求模型區分關於企鵝的詩和關於火烈鳥的詩,而「Reproduce the first poem about penguins.」要求模型對順序進行推理。
作者通過模型輸出和正確響應之間的字符串相似性對MRCR進行評分。
IDK
IDK任務向模型展示大量文本並提出一個問題,鑒於預訓練語料庫龐大,該問題沒有客觀答案。
例如,可能有一個關於一個女人和她的狗的虛構故事,其中詳細說明了狗的名字和年齡,但沒有詳細說明它的顏色。然後向模型提問:女人的狗是什麼顏色的?
此任務的每個實例,都會提供四個選項作為答案,其中一個始終是「I don’t know」,而其他選項都是相對合理的回答。

評估中設置70%的任務實例對應於真實答案是「I don’t know」,30%的實例對應於在上下文中可找到答案(即簡單檢索任務),最後根據模型輸出是否具有正確答案進行評分。
全新評估框架
長上下文評估通常應遵循以下原則:
通常可擴展至任意上下文長度;
由相關信息的數量編製索引的複雜度;
上下文長度難度應與任務對應的複雜度解耦,沒有不相關的信息;
覆蓋自然語言文本和代碼(兩個基本領域);
避免數據泄露;
測試模型對上下文中傳達的隱含信息的理解;
用儘可能少的評估次數,測試長上下文綜合能力的正交維度。
本文的評估框架將呈現給模型的上下文視為一個信息流,它構成了對潛在結構的更新:完整的上下文長度就像一塊大理石,裡面有許多不相關的信息,LLM需要鑿掉不相關的信息,才會露出裡面的雕像(潛在結構)。
舉個例子,你可以想像讀一本描寫家庭的書——父母可能會離婚,孩子長大後會結婚,長輩會去世。在這個過程中,與家譜對應的潛在結構發生了變化和更新(書中的大部分信息則根本不影響家譜)。
實驗結果
考慮每個評估中的128K上下文:

如圖所示,在短上下文中,這些模型的性能最初會出現一次急劇的超線性下降。

請注意,任務複雜度在整個上下文中保持固定,因此這種下降完全是由於模型的長上下文處理能力。

之後,性能通常會趨於平緩或繼續以大致線性的速度下降,並通常會持續到非常大的上下文長度。
我們可以將這種行為解釋為模型具有足夠好的子功能,足以在給定任務上實現一定水平的性能,並且這些子功能的長度泛化到了非常大的上下文長度。
參考資料:
https://arxiv.org/abs/2409.12640



















