更快、更強、更經濟,港大開源大模型RAG系統LightRAG

【導讀】LightRAG通過雙層檢索範式和基於圖的索引策略提高了信息檢索的全面性和效率,同時具備對新數據快速適應的能力。在多個數據集上的實驗表明,LightRAG在檢索準確性和響應多樣性方面均優於現有的基線模型,並且在資源消耗和動態環境適應性方面表現更優,使其在實際應用中更為有效和經濟。
隨著大語言模型(LLM)自身能力的日趨完善,很多學者的目光聚焦於如何幫助大模型處理和感知大規模的私有數據庫。RAG(Retrieval-Augmented Generation)系統採用檢索方法,從私有數據庫中高效、準確地召回與查詢高度相關的信息內容,用以增強通用大模型處理查詢的語境知識和生成效果。
現有RAG方法基於信息索引和檢索算法,在整合外部知識源方面已經取得了一定的成效,然而這些方法普遍存在以下問題亟待解決:
1. 當前方法大多採用扁平的向量化表示方法,這限制了模型對外部數據的理解和檢索的準確性,影響了檢索的效果。
2. 現有工作缺乏對實體間相互聯繫的充分探索,導致面對複雜的高級問題時無法有效結合多個方面的信息進行聯繫和總結。
為了應對這些問題,北京郵電大學、香港大學的研究人員提出了一種使用圖結構數據進行增強的RAG系統——LightRAG,利用圖結構對複雜關係的準確描繪,LightRAG能夠有效地解決上述問題。

論文地址:https://arxiv.org/abs/2410.05779
項目地址:https://github.com/HKUDS/LightRAG
為了實現系統的性能和效率,LightRAG的設計聚焦於解決以下挑戰:
1. 信息檢索的全面性:RAG系統應當能夠全面考慮查詢和外部知識在不同層級的語義,既能夠感知具體的實體,也能夠理解抽像概念。
2. 信息檢索的效率:在保證檢索準確性的情況下,能夠進行高效的信息檢索,是RAG系統面對海量查詢請求時的關鍵能力。
3. 對新數據的快速適應能力:在實際使用過程中,外部數據庫常常發生持續不斷的演化,如何讓RAG系統保持靈活的更新能力,是一個重要問題。
為瞭解決上述挑戰,LightRAG系統具有以下關鍵設計。
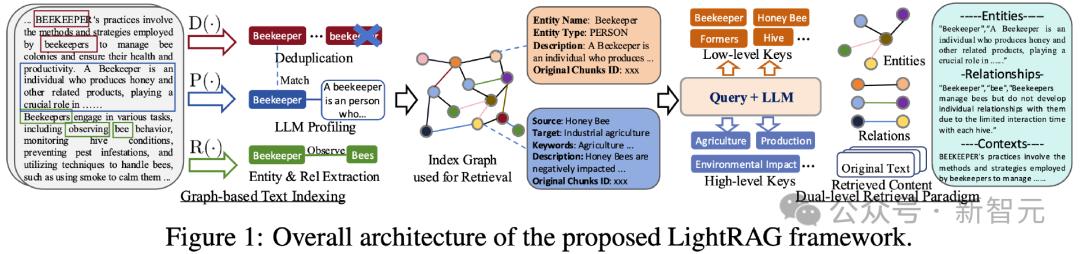
基於圖數據結構的文本索引
LightRAG首先對外部數據庫進行預處理,以利於處理查詢時的高效性和準確性,這一過程被稱為文本索引。為了充分理解數據庫中實體間的相互聯繫,這一過程採用了圖的數據結構進行增強。
總體來說,這一過程包含以下幾個重要階段:
1. 實體和關係抽取:為了獲取索引圖中的基本元素,LightRAG首先使用大語言模型處理原始文本數據,識別出其中具有固定語義的實體、以及它們之間的關係。例如在一篇醫學文章中識別出「心臟病」以及「心內科醫生」這兩種實體,並指出兩者之間的治療關係。
通過這一過程,首先可以很好地提取出數據中關鍵的細粒度語義元素,方便之後的信息檢索;其次,這種關係結構可以很好地將原始數據中的信息聯繫起來,加強RAG系統對實體間聯繫的理解和感知,提升檢索的全面性。
2. 用於檢索的鍵值對生成:通過上述步驟獲得了圖數據的骨架後,LightRAG繼續使用大語言模型方法,生成每個實體和關係的檢索鍵和檢索值。其中檢索鍵是較短的文本,用於與查詢文本的語義進行匹配。
節點的檢索鍵通常是他的文本名稱本身,而關係的檢索鍵則通過提示大語言模型的方法生成,反應了該關係對關聯的抽像語義。檢索值則為相對大段的文本描述,是檢索後用於增強通用大模型回答查詢的細節信息。通過這種方法,LightRAG的檢索既能夠感知豐富具體的語義信息以提升準確性,又可以通過鍵值進行快速索引和數據獲取。
3. 實體和關係去重:對較長的外部文本數據,上述過程會重覆提取一些相同或者高度相似的實體和關係。為了進一步提升RAG系統的效率,接下來通過提示大語言模型來進行實體和關係的去重,得到最終的圖結構索引。
4. 增量更新:為了應對外部數據庫體量的不斷擴大,LightRAG基於上述過程設計了增量方法。通過採用同樣的實體和關係抽取、鍵值對生成、圖結構元素的去重和合併過程,LightRAG可以避免對全部數據進行重新處理,而只進行增量式的信息索引和合併,大大提升了RAG系統的適應能力。
LightRAG的雙層檢索範式
為了提升模型的全面性,LightRAG充分考慮到了具體查詢和抽像查詢這兩類查詢請求的不同。前者通常明確關聯於實際的實體,需要檢索回相關的實體並結合問題進行總結。而後者主要設計抽像的概念,需要準確識別出具象實體和抽像概念之間的聯繫,才能得到需要的信息進行回答。
對應這兩類查詢請求,LightRAG採用了一種雙層檢索範式:在底層檢索中,LightRAG基於實體包含具象語義的鍵值進行檢索和召回;而在高層檢索中,LightRAG首先識別出查詢請求所涉及的抽像概念,以將其與關係中的抽像檢索鍵進行匹配。
這種雙層檢索範式的優勢在於,它通過結合特定查詢和抽像查詢的處理方式以及低級別檢索和高級別檢索策略,並整合圖和向量進行檢索,從而能夠有效適應多樣化的查詢類型。這使得它不僅可以精確檢索到與特定實體相關的詳細信息,還能獲取更廣泛主題的相關知識,進而確保系統能夠為用戶提供全面且相關的回答,滿足不同用戶的需求。
在檢索過程中,LightRAG將圖數據檢索與向量數據庫檢索進行結合,既考慮到了召回實體和關係的鄰域信息,也考慮到了如何在實現中進行快速匹配。
實驗
實驗設置
評估數據集
為了全面評估模型的性能,我們精心選擇了來自UltraDomain的四個具有不同特徵的數據集。首先,Agriculture數據集專注於農業實踐領域,包含了12篇文檔,總token數達到2,017,886個。其內容廣泛涵蓋了農業相關的各種主題,為模型在農業領域的理解和處理能力提供了測試平台。
接下來是CS(計算機科學)數據集,由10篇文檔組成,總計2,306,535個token。該數據集涉及計算機科學的多個方面,包括算法、人工智能、軟件工程等,旨在評估模型在計算機科學領域的表現。
第三個數據集是規模最大的Legal數據集,包含了94篇文檔,累計5,081,069個token。它聚焦於公司法律實踐,涵蓋了各種法律文件、案例分析和法規解讀,測試模型在法律文本處理和法律知識理解方面的能力。
最後,Mix數據集包含了61篇文檔,共計619,009個token。該數據集彙集了多個學科的文本,包括人文、社會科學和自然科學等,旨在評估模型在處理跨領域、多主題內容時的綜合性能。
通過選擇這些多樣化的數據集,我們得以在不同領域和規模下全面評估模型的表現,為實驗結果的可靠性和普遍性提供了保障。
問題生成
為了測試模型在各種複雜問題上的處理能力,我們針對每個數據集生成了一系列需要深入理解的問題。具體方法是,將每個數據集的所有文本內容視為背景上下文,然後利用大型語言模型(LLM)生成問題。
首先,我們讓LLM為每個數據集創建五個虛擬的RAG用戶,每個用戶代表不同的信息需求或興趣領域。接著,針對每個用戶,設計了五個獨特的任務,模擬他們可能提出的查詢類型。
對於每個用戶-任務組合,LLM進一步生成了五個需要全面理解整個語料庫才能回答的問題。通過這種方式,每個數據集最終產生了125個多樣化的問題(5個用戶 × 5個任務 × 5個問題),從而全面評估模型在處理各種查詢時的能力。
實現和評估細節
在實驗實施過程中,我們採用了nano向量數據庫來管理向量化的數據,以提高檢索的效率和速度。在LightRAG模型中,所有基於LLM的操作預設使用了GPT-4o-mini模型,以保持實驗的一致性和可比性。
在預處理階段,統一將所有數據集的文本塊大小設置為1200個token,旨在平衡模型的計算效率和上下文捕獲能力。一些關鍵參數被固定,以減少變量對實驗結果的影響。
為了評估模型的性能,我們採用了基於LLM的多維度比較方法。具體定義了全面性、多樣性、賦能性和總體表現四個評估維度。這些維度從不同角度衡量模型的回答質量,確保評估的全面性。
由於檢索增強生成(RAG)模型的查詢通常沒有標準答案,直接評估回答的準確性存在挑戰。
為此,我們利用GPT-4o-mini對基線模型和LightRAG的回答進行排名評估。通過交替排列答案、盲審等方式,確保評估過程的公平性和客觀性。最終,我們計算了各模型在不同維度上的勝率,以量化它們的性能差異。
回答質量比較
我們將LightRAG與多種基線模型在四個選定的數據集(Agriculture、CS、Legal、Mix)上進行了比較,評估它們在不同維度下的性能表現。

以Agriculture數據集為例,在全面性維度上,Naive RAG模型的勝率為32.69%,而LightRAG的勝率達到了67.31%,顯著優於基線模型。同樣地,在多樣性維度上,Naive RAG的勝率為24.09%,而LightRAG高達75.91%。這種優勢在CS、Legal和Mix數據集上也得到了體現,LightRAG在多數評估維度上的勝率都明顯超過了基線模型。
通過深入分析實驗結果,我們得出了以下結論:
首先,基於圖的RAG系統在處理大規模語料和複雜查詢時表現出更好的性能。
LightRAG和GraphRAG等模型利用圖結構捕獲了語料庫中的複雜語義依賴關係,隨著數據集規模的增加,這種優勢更加明顯。
例如,在規模最大的Legal數據集上,基線方法的勝率僅約為20%,而LightRAG顯著領先。這表明,圖增強的RAG系統能夠更全面地理解和整合知識,提高模型的泛化能力。
其次,LightRAG在多樣性維度上展現了卓越的優勢。
與各種基線模型相比,LightRAG在提供豐富、多樣化的回答方面表現突出,尤其是在Legal數據集等大型數據集上。
這主要歸功於LightRAG的雙層檢索策略,它能夠從低級別(具體細節)和高級別(宏觀主題)兩個層次全面檢索信息,充分利用基於圖的文本索引,捕獲查詢的完整上下文,從而生成更為豐富的回答。
消融實驗
為了深入瞭解模型各組件對整體性能的影響,我們對LightRAG進行了消融實驗,重點考察了雙層檢索機制和語義圖在模型中的作用。實驗結果如下,我們從中觀察到了以下現象:

首先,僅使用低級別或高級別檢索的影響:
1. 當僅使用低級別檢索(即移除高級別檢索,稱為「-High」變體)時,模型在幾乎所有數據集和評估指標上性能顯著下降。例如,在Agriculture數據集的全面性維度,勝率從LightRAG的67.31%下降到35.79%。
2. 反之,當僅使用高級別檢索(即移除低級別檢索,稱為「-Low」變體)時,雖然在全面性上可能有所提升,但在涉及具體實體細節的指標上表現不足。例如,在Agriculture數據集的多樣性維度,勝率從LightRAG的75.91%降至35.09%。
3. 雙層檢索機制對於模型性能至關重要。僅使用低級別檢索時,模型過於關注特定實體及其直接關聯,無法全面理解複雜查詢所需的廣泛信息,導致性能下降。僅使用高級別檢索則缺乏對具體細節的深入挖掘。在這兩種情況下,模型的回答都不夠完整或精準。這表明,結合低級別和高級別檢索的雙層策略能夠平衡信息的廣度和深度,為模型提供更全面的數據支持,從而提升整體性能。
其次,語義圖在檢索中的作用:
1. 當在檢索過程中不包含原始文本(稱為「-Origin」變體)時,模型在四個數據集上的性能並未顯著下降,甚至在某些數據集(如Agriculture和Mix)上還有所提升。
2. 語義圖在信息提取中的有效性得到驗證。當移除原始文本時,模型性能未見明顯下降,說明基於圖的索引過程已經成功提取了關鍵信息。語義圖結構本身提供了足夠的上下文,用於回答查詢。而原始文本中可能存在的冗餘或不相關信息,反而可能幹擾模型的檢索和回答過程。
案例研究
為了更直觀地展示模型在實際應用中的表現,我們進行了具體的案例研究,比較了LightRAG和GraphRAG在回答特定問題時的效果。此次研究聚焦於一個涉及機器學習的問題:
「哪些方法可以對特徵值進行規範化以提高機器學習的效果?」

我們分別獲取了兩個模型對該問題的回答,並使用大型語言模型(LLM)對它們在各個評估維度上的表現進行評估。結果顯示,LightRAG在全面性、多樣性和賦能性等所有維度上均優於GraphRAG。
在全面性方面,LightRAG的回答涵蓋了更多的特徵規範化方法,如歸一化、標準化和歸一化到特定區間等,體現了更強的信息整合能力。
在多樣性維度上,LightRAG提供了多種不同的技術手段,涵蓋了數據預處理的各個方面,信息更加豐富。
在賦能性方面,LightRAG的回答不僅列出了方法,還對每種方法的適用場景和優缺點進行了詳細解釋,幫助用戶更好地理解和應用這些知識。
通過這個案例,我們可以得出以下結論:
1. 基於圖的索引策略提升了模型的理解深度。LightRAG在全面性上的優勢,得益於其精確的實體和關係提取能力,以及對知識的深入整合。
2. 雙層檢索策略增強了回答的質量和豐富性。低級別檢索使模型能夠深入挖掘具體細節,高級別檢索則提供了宏觀視角,兩者結合提高了回答的全面性和實用性。
模型開銷與適應性分析
在實際應用中,模型的資源消耗和對動態環境的適應性至關重要。我們從兩個關鍵角度對LightRAG和表現最優的基線模型GraphRAG進行了比較:一是索引和檢索過程中使用的token數量和API調用次數,二是在動態環境中處理數據變化時的效率和成本。

以Legal數據集為例進行評估:
在檢索階段:
1. GraphRAG:生成了1,399個社區,其中610個用於實際檢索。每個社區報告平均包含1,000個token,總消耗約610,000個token。同時,檢索過程中需要逐一遍曆這些社區,導致數百次API調用,增加了時間和資源成本。
2. LightRAG:僅使用了不到100個token用於關鍵詞生成和檢索,整個過程只需一次API調用。這大大降低了token消耗和API調用次數,提高了檢索效率。
在增量數據更新階段:
1. GraphRAG:當引入與Legal數據集等規模的新數據時,需要拆除現有的社區結構並完全重新生成。每個社區報告約需5,000個token,對於1,399個社區,總計需要約13,990,000個token,成本極高。
2. LightRAG:利用增量更新算法,能夠直接將新提取的實體和關係無縫集成到現有的圖結構中,無需完全重建索引,大幅降低了token消耗和處理時間。
通過上述分析,我們發現:
1. LightRAG在檢索效率和資源消耗上具備明顯優勢。其優化的檢索機制減少了不必要的信息處理,降低了token和API調用的使用量。
2. 在動態數據環境中,LightRAG的適應性更強。通過增量更新能力,能夠有效應對數據的頻繁變化,保持系統的高效性和成本效益。
綜上所述,LightRAG在信息檢索效率、成本效益和動態環境適應性方面都優於GraphRAG。這使其在需要處理大量數據和頻繁更新的實際應用場景中,更具優勢和競爭力。
參考資料:
https://arxiv.org/abs/2410.05779
https://sites.google.com/view/chaoh
本文來自微信公眾號「新智元」,編輯:LRST,36氪經授權發佈。














