百萬魯棒數據訓練,3D場景大語言模型新SOTA!IIT等發佈Robin3D

新智元報導
編輯:LRST
【新智元導讀】Robin3D通過魯棒指令數據生成引擎(RIG)生成的大規模數據進行訓練,以提高模型在3D場景理解中的魯棒性和泛化能力,在多個3D多模態學習基準測試中取得了優異的性能,超越了以往的方法,且無需針對特定任務的微調。
多模態大語言模型(Multi-modal Large Language Models, MLLMs)以文本模態為基礎,將其它各種模態對齊至語言模型的語義空間,從而實現多模態的理解和對話能力。近來,越來越多的研究聚焦於3D大語言模型(3DLLM),旨在實現對3D物體以及複雜場景的理解,推理和自由對話。
與2D MLLM所能接觸的廣泛的多模態數據不同,3DLLM的訓練數據相對稀少。
即便過去有些工作嘗試生成更多的多模態指令數據,但這類模型仍然在指令的魯棒性上存在兩點不足:
1. 絕大多數3D多模態指令數據對是正樣本對,缺乏負樣本對或者對抗性樣本對。模型在這種數據上訓練缺乏一定的辨識能力,因為無論被問到什麼問題,模型只會輸出正面的回答。因此碰到問題與場景無關時,模型也更容易出現幻覺。這種模型有可能只是記住了正樣本對,而非真正地理解被問及的場景、物體、以及具體的指令。
2. 由於在造數據的過程中,人類標註員或者生成式大語言模型是按照既定的規則去描述物體的,很多由這些描述所轉換而來的指令缺乏多樣性。甚至有的數據是直接按照模板生成的。
為瞭解決以上問題,伊利諾伊理工大學、浙江大學、中佛羅里達大學、伊利諾伊大學芝加哥分校提出一個強大3DLLM——Robin3D,在大規模魯棒數據上進行訓練。

論文地址:https://arxiv.org/abs/2410.00255
文中提出了「魯棒指令數據生成引擎」(Robust Instruction Generation, RIG),可以生成兩種數據:
1. 對抗性指令數據。該數據特點在於在訓練集或者單個訓練樣本中,混合了正樣本和負樣本對(或者對抗樣本對),從而使得模型在該類數據集訓練能獲得更強的辨識能力,該數據包含了物體層面到場景層面的、基於類別的指令和基於表達的指令,最終形成了四種新的訓練任務,幫助模型解耦對正樣本對的記憶。
2. 多樣化指令數據,首先全面收集現有研究中的各種指令類型,或將一些任務轉化為指令跟隨的格式。為了充分利用大語言模型強大的上下文學習能力,研究人員使用ChatGPT,通過為每個任務定製的特定提示工程模板來多樣化指令的語言風格。
將這些與現有基準的原始訓練集相結合,研究人員構建了百萬級指令跟隨樣本,其中約有34.4萬個對抗性數據(34%)、50.8萬個多樣化數據(50%)和16.5 萬個基準數據(16%),如圖1(右)所示。
 圖1 Robin3D在構建的百萬級數據上訓練(右),最終在所有3D多模態數據集上的性能超過之前的SOTA(左)
圖1 Robin3D在構建的百萬級數據上訓練(右),最終在所有3D多模態數據集上的性能超過之前的SOTA(左)Robin3D在模型上與Chat-Scene類似:使用Mask3D,Uni3D來抽3D物體級別的特徵,使用Dinov2來抽2D物體級別的特徵,使用物體ID來指定和定位物體。
先前的方法在抽物體特徵的時候,由於其物體級別的規範化(normalization),不可避免的丟失了物體間的3D空間關係。同時簡單的物體ID和物體特徵拚接缺乏對ID-特徵的充分聯結,使其在這種複雜的指令數據上面臨訓練的困難,而Robin3D引入了關係增強投射器來增強物體的3D空間關係,並使用ID-特徵捆綁來增強指代和定位物體時ID與特徵之間的聯繫。
最終Robin3D在所有的3D場景多模態數據集上達到一致的SOTA,並且不需要特定任務的微調。
方法
 圖2 Robin3D的模型結構
圖2 Robin3D的模型結構關係增強投射器
如圖2所示,關係增強投射器(Relation-Augmented Projector, RAP)考慮三種特徵:
1. Mask3D所抽取的場景級別特徵,這種特徵經過多層cross-attention充分交互了語意和位置關係;
2. Mask3D里的位置嵌入特徵,這種特徵由物體超點直接轉換而來,代表了物體間的位置關係。
3. Uni3D抽取的統一物體級別特徵,這種特徵和語言進行過大規模的對齊訓練。
 圖3 RAP公式
圖3 RAP公式如圖3所示,通過MLP和短接的方式,對三種特徵進行高效的融合,最終實現了即保持強大的統一物體級別語意信息、又增強了物體之間的空間位置關係。
ID-特徵捆綁
如圖1所示,的ID-特徵捆綁(ID-Feature Bonding, IFB)主要包含兩個操作。首先,使用兩個相同的ID來包裹其物體特徵。
由於LLM的因果注意力機制,這種方法通過第一個ID將ID信息與物體特徵關聯起來,並通過第二個ID將物體信息與其ID關聯起來。
其次,提出了一個後視覺順序,將視覺tokens放置在輸入序列的末尾,靠近模型生成的答案標記。
該方法減少了由於tokens間的相對距離和LLM中旋轉位置嵌入所導致的從答案tokens到ID-特徵tokens的注意力減弱問題,同時增強了視覺信息對答案tokens的注意力影響,從而提升答案生成效果。
魯棒指令數據生成引擎
對抗性數據生成
 圖4 對抗性數據的四種任務
圖4 對抗性數據的四種任務如圖4,的對抗性數據形成了四種新的具備挑戰性的任務HOPE、HROC、PF-3DVG和3DFQA,包含了從物體到場景、從基於類比到基於表達的不同指令。
圖4左上:Hybrid Object Probing Evaluation (HOPE)
為了構建一個場景級別的基於類別的任務,引入了HOPE,靈感來自2D領域的POPE基準。POPE通過詢問關於單個物體存在與否的是/否問題,評估2DMLLMs產生幻覺的傾向。在此基礎上,HOPE將這種幻覺挑戰擴展到3D領域的訓練階段,旨在讓模型更具辨別力。
此外,HOPE引入了一個混合場景,增加複雜性,進一步推動模型對記憶中的視覺與語言正樣本的解耦。
具體來說,在給定的3D場景中,要求模型判斷多個隨機指定的物體是否存在。物體可能存在或不存在,且每個存在的物體可能有一個或多個實例。
當物體不存在時,模型需回答「否」;當物體存在時,需回答「是」並提供每個實例的物體ID。這一設置結合了正負物體的混合識別與多實例物體定位,具有很高的挑戰性。
圖4右上:Hybrid Referring Object Classification (HROC)
指代物體分類任務旨在評估模型在2D域中識別指代區域的能力,使用「區域輸入,文本輸出」的形式。HROC將此任務擴展到3D領域,創建了一個物體級別的基於類別的任務,並結合了對抗性和混合挑戰。
在3D場景中,隨機生成混合的正負ID-類別樣本對來提出問題。正樣本對包含一個有效的物體ID和對應的真實類別,負對則包含一個有效的物體ID和隨機選擇的非真實類別,作為對抗性挑戰。模型需對正樣本對回答「是」,對負對回答「否」並給出正確類別。
圖4左下:Partial Factual 3D Visual Grounding (PF-3DVG)
PF-3DVG引入了一個場景級別的基於表達的任務,涵蓋三種數據類型:非真實數據、部分真實數據和真實數據。
非真實數據:在3D場景中,隨機選擇Sr3D+中的描述,其中所描述的物體不存在與當前3D場景。模型需回答「否」。
部分真實數據:給定Sr3D+的描述及對應的3D場景,隨機修改描述中的空間關係。例如,將「沙發上的枕頭」改為「沙發下的枕頭」。
模型需糾正信息並回答「它是在『上面』」,同時提供物體ID。團隊確保描述的目標物體類別是當前場景唯一的、無干擾項,以避免歧義。真實數據:隨機增強空間關係的同義詞以提高多樣性,例如,將「below」替換為「under」、「beneath」或「underneath」。
圖4右下:Faithful 3D Question Answering (3DFQA)
原始的3D問答任務僅包含正樣本,可能導致模型記住固定的3D場景和問答對。為瞭解決這一問題,提出3DFQA,一個結合了負樣本和正樣本的場景級別的基於表達的QA任務,其增加了定位的要求。
構建負樣本時,從ScanQA中抽取問答對,並收集問題或答案中的相關物體,然後隨機選擇一個缺少這些物體的3D場景。在原來的問題上,新增一個指令:「如果可以,請回答……並提供所有ID……」。
此時,模型必須回答「否」,並且不提供任何物體ID,體現其對場景的依賴而不會胡言亂語總給出正面回覆。正樣本直接取自ScanQA,模型需回答問題並提供相關物體的ID作為答案的依據。
因此,訓練在的3DFQA數據集上的模型不能依靠記憶,而是要學會對正負樣本做出忠實回應並有理有據。
多樣化數據生成
多樣化數據旨在通過結合多種不同任務類型的指令數據,並提高指令的語言多樣性,從而增強模型的泛化能力。首先從基準數據集之外的不同任務中收集大規模數據。
具體而言,給定一個3D場景,收集以下任務的問答對:類別問答任務(來自Chat-Scene),Nr3D描述生成任務(轉換自Nr3D),外觀描述生成任務(來自Grounded-3DLLM),區域描述生成任務(來自Grounded-3DLLM),端到端3D視覺定位(轉換自Nr3D),端到端3D視覺定位(轉換自Sr3D+)。
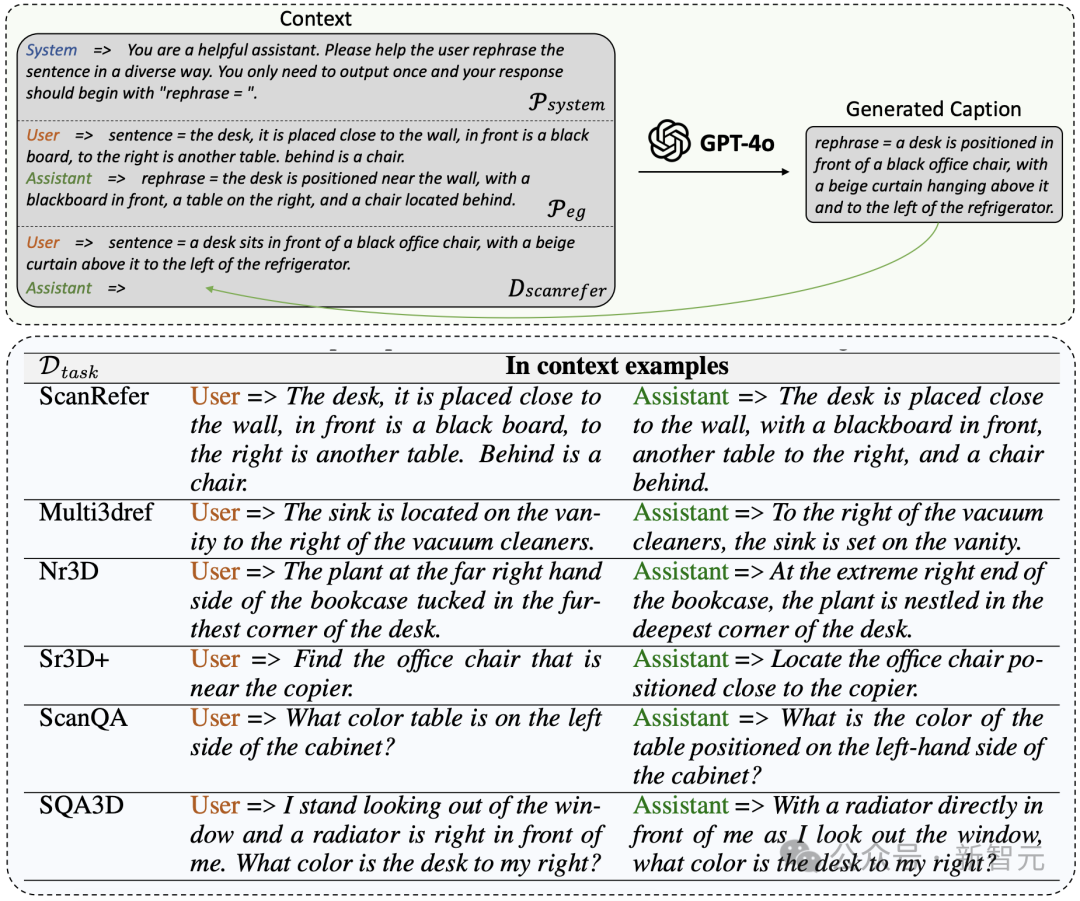 圖5 多樣化數據的生成流程和詳細的提示工程
圖5 多樣化數據的生成流程和詳細的提示工程為了豐富表述風格,開發了一個可擴展的流程,利用ChatGPT的上下文學習能力對上述數據進行重述。這通過一組示例和結構化提示工程實現,如圖5(上)所示。
具體而言,給定一個收集的指令數據集D_task(其中任務包括ScanRefer、Multi3DRefer、Nr3D、Sr3D+、Nr3D Captioning、ScanQA、SQA3D、PF-3DVG和3DFQA),構建了一個系統提示P_system,以指示重述的要求和結構化的輸出格式,同時提供一個示例提示P_eg,以幫助ChatGPT更好地理解要求。
還隨機選擇一個溫度參數T(從[1.1, 1.2, 1.3]中選取)以增加輸出的隨機性和多樣性。的重述輸出D_rephrase通過公式D_rephrase = M(P_system, P_eg, D_task, T)生成,其中M是ChatGPT的GPT-4o版本。
圖5(上)詳細說明了P_system和P_eg的內容,以ScanRefer數據為例。通過使用sentence=和rephrase=的結構化提示,GPT-4o能夠輕鬆遵循要求,可以通過檢測rephrase=關鍵字方便地收集輸出。
圖5(下)提供了每個任務的示例提示的詳細信息。由於Nr3D Captioning源於Nr3D,PF-3DVG源於Sr3D+,而3DFQA源於ScanQA,因此不再為這些任務提供額外示例。
實驗
主要結果
 表1 性能對比結果
表1 性能對比結果如表1所示,由於RIG生成的魯棒指令數據,Robin3D在所有基準測試中顯著超越了之前的模型。具體而言,Robin3D在Scan2Cap CIDEr@0.5上帶來了6.9%的提升,在ScanRefer Acc@0.25上帶來了5.3%的提升。值得注意的是,在包含零目標案例的Multi3DRefer評估中,這些案例對模型的區分能力提出了挑戰,並要求模型能夠回答「No」。的Robin3D在F1@0.25上實現了7.8%的提升,在F1@0.5上實現了7.3%的提升。
消融實驗
 表2和表3 消融實驗結果
表2和表3 消融實驗結果如表2和表3所示,對提出的對抗性數據和多樣化數據進行了消融實驗,也對模型結構上RAP和IFB的提出做了消融實驗。實驗結果在所有benchmark上都證明了他們一致的有效性。
特別的,在表2中,對抗性數據對描述生成任務Scan2Cap帶來了8.9%的提升,然而對抗性數據是不存在描述生成任務的,並且也不存在同源的數據(Scan2Cap數據源自ScanRefer, 但對抗性數據無源自ScanRefer的數據)。這種大幅的提升體現了對抗性數據對模型識別能力的提升。
參考資料:
https://arxiv.org/abs/2410.00255



















