還是原裝 Transformer 好!北大清華團隊同時揭示Mamba等推理短板
轉自 | 機器之心
北京大學的工作來自智能學院王立威、賀笛老師課題組,發表於ICML 2024。作者包括北京大學圖靈班本科生楊鎧;蘇黎世聯邦理工學院碩士生Jan Ackermann;北京大學智能學院博士生何震宇、馮古豪、張博航;紐約大學博士生馮韞禛;北京智源研究院研究員葉啟威;清華大學的工作來自於明年即將入職清華大學交叉信息院做助理教授、目前在加州大學伯克利分校 Simons Institute 做博士後的呂凱風研究員。作者包括史丹福在讀一年級博士溫凱越;清華大學姚班本科生黨星宇。
思維鏈(CoT)是大模型中最神秘的現象之一,尤其在數學任務上顯著提升了 Transformer 的能力。然而,思維鏈的引入也使生成內容的長度增加,消耗了更多的計算資源。這不禁讓人好奇:最新推出的高效模型(如 Mamba)是否也能像 Transformer 一樣具備強大的推理能力?近期,北大和清華的研究團隊同時給出了明確的否定答案,揭示了 Mamba 等高效模型在結構上的局限性。

-
論文 1:Do Efficient Transformers Really Save Computation? (發表於 ICML 2024)
-
論文鏈接:https://arxiv.org/abs/2402.13934

-
論文 2:RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval
-
論文鏈接:https://arxiv.org/abs/2402.18510
基於 Transformer 的大語言模型在文本翻譯、文本生成等許多領域展現了驚人的能力。主流的大語言模型通常採用自回歸範式進行生成:由問題描述、相關提示組成的輸入序列(prompt)會被首先編碼。基於編碼後的信息,大模型逐步生成後續的單詞序列,以形成問題的答案。對於複雜的問題,已有的實踐和理論研究表明,利用思維鏈提示(CoT)可以顯著提升模型在數學或推理方面的問題解決能力。
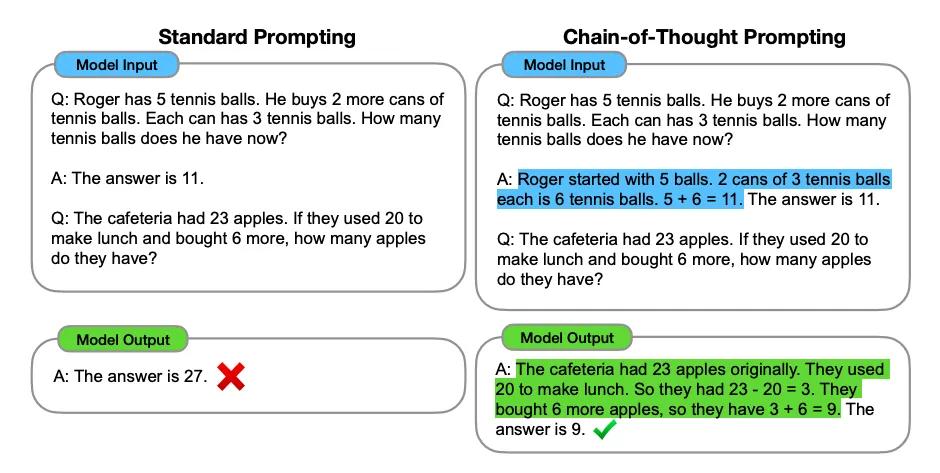
如上圖,當給出的問題示例中只有最終結果,而沒有中間的推理過程時,大模型在見到新問題時往往會生成錯誤的答案;但如果給出的問題示例中包含了完整的思維鏈(中間推導步驟),大模型在新問題上也往往會輸出完整的思維鏈並得到正確答案。然而,思維鏈提示依賴於大量中間步驟的輸出,使用 Transformer 架構會產生大量的計算開銷。因此,一個自然的問題便是:能否使用更少的計算量,實現思維鏈推理?許多架構致力於降低注意力機制帶來的計算複雜度,能否在這些架構上使用 CoT 提升性能並實現推理的加速?
近期,來自北大和清華的研究團隊從理論角度對上述問題進行了深入探討。結果令人驚訝:兩個團隊一致證實包括 Sparse Transformer、Linear Transformer、Mamba 在內的許多架構,即使在這些模型上應用思維鏈,其理論上的能力上限仍無法解決多種實際推理問題,並與標準 Transformer 有本質差距。這些理論結果為高效結構的實用價值蒙上了一層陰影。
Transformer + CoT 依然是最佳選項
北大的研究團隊將推理任務通用地建模為動態規劃。在推理過程中,模型需要按照合法的拓撲排序逐步輸出子問題的結果(即思維鏈),以最終得出原問題的解。他們從理論角度證明,若希望 Sparse Transformers、Linear Transformers 等模型通過思維鏈來解決動態規劃問題,模型的寬度必須增加,進而導致時間複雜度恰好達到平方級別。這一時間複雜度與標準 Transformers 在相同長度的推理任務中所需的複雜度一致,表明這些所謂的高效結構在一般推理問題上並不具備計算優勢。
殊途同歸,清華的研究團隊考慮了 RNN 模型和 Transformer 模型在檢索、關聯回憶、計數,以及判斷一張圖是否為樹等基本問題上的表達能力差異。他們從理論角度證明了,對於問題規模 n,任意 o (n) 大小的 RNN 模型均無法完成上述任務,即便使用任意長的 CoT。但一個固定大小的 Transformer 可以不使用 CoT 解決檢索、關聯回憶、計數等問題,並使用 O (n) 長度的 CoT 正確判斷一張圖是否為樹。這些結果表明類 RNN 的結構使用思維鏈獲得的能力,距離 Transformer 仍有巨大差距。
兩個研究得出相似結論的背後,揭示了相似的本質。這些模型架構之所以具有內存高效性,是因為它們能夠在較少的空間下完全確定輸出序列。然而,輸出序列的可能性指數級增長,這使得這些架構無法以較小的模型尺寸正確生成所有可能的輸出。換句話說,模型的規模必須隨著問題規模的增加而擴展。這一核心觀察表明,包括 Mamba 在內的具有循環(recurrent)性質的網絡架構,都受到了相同的限制。
如何提升其它模型使用思維鏈的能力?
在得到負面結論的同時,兩個團隊考慮不同角度設計解決方案。
北大研究團隊從推理任務的局部性入手,即當前輸出所需要向前依賴的最遠輸出的距離。局部性反映了推理所需要的長程記憶難度。他們從理論角度證明了,當推理任務有較好的局部性時,許多高效模型能夠以理論更優的推理速度完美解決問題。
來自清華的研究團隊則從引入上下文檢索器的角度入手。他們從理論角度證明了,使用顯式上下文檢索器或使用一層 Transformer 作為隱式上下文檢索器,均可以大大增強 RNN 使用思維鏈後獲得的能力。
研究團隊還設計了大量的實驗驗證理論結果。來自北大的研究團隊在多種 Transformer 架構上使用 CoT 數據進行訓練,表明標準 Transformer 架構事實上使用了最小的計算量。

同時,他們的實驗結果也表明了良好的推理局部性(下圖右列)能夠增強多種 Efficient Transformers 的思維鏈推理能力,表現在使用相同尺寸的模型時能夠解決規模更大的推理任務。

來自清華的研究團隊則在 Mamba 和 Transformer 上使用判定圖是否為樹的任務進行訓練,表明 Transformer 結構在此問題上相比於 Mamba 所具有的顯著優勢,以及在 RNN 上使用上下文檢索對性能的影響。



















