NeurIPS 2024 | 標籤噪聲下圖神經網絡有了首個綜合基準庫,還開源
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
多年來,浙江大學周晟老師團隊與阿萊恩全交互內容安全團隊持續開展產學研合作。近日,雙⽅針對標籤噪聲下圖神經⽹絡的聯合研究成果《NoisyGL:標籤噪聲下圖神經網絡的綜合基準》被 NeurIPS Datasets and Benchmarks Track 2024 收錄。本次 NeurIPS D&B Track 共收到 1820 篇投稿,錄⽤率為 25.3%。

-
論文標題:NoisyGL: A Comprehensive Benchmark for Graph Neural Networks under Label Noise
-
論文地址:https://arxiv.org/pdf/2406.04299
-
項目地址:https://github.com/eaglelab-zju/NoisyGL
圖神經網絡(GNNs)在節點分類任務中通過消息傳遞機制展現了強大的表示力。然而,它們的性能往往依賴於⾼質量的節點標籤。在現實世界中,由於不可靠的來源或對抗性攻擊,節點標籤中通常存在噪聲。不過,目前針對該領域缺乏⼀個綜合的基準。
為填補這⼀空白,本文提出了 NoisyGL 方法,這是第⼀個針對標籤噪聲下圖神經⽹絡的綜合基準。NoisyGL 使⽤統⼀的實驗設置和接⼝,可以在具有不同性質的圖數據上對不同⽅法的抗噪性能進⾏公平比較和多⻆度分析。此外,NoisyGL 也是⼀個可擴展且易於使⽤的 GLN 框架,便於後續的研究者跟進。
本⽂亮點包括如下:
-
提出了 NoisyGL,第⼀個針對標籤噪聲下的圖神經⽹絡的綜合基準庫。
-
通過⼤量的實驗,針對標籤噪聲下的圖神經⽹絡提出了⼀些重要的見解。
-
為標籤噪聲下的圖神經⽹絡提供了⼏點未來的發展⽅向。
⼀、研究背景
許多現實世界中的複雜系統可以表示為圖結構數據,包括引⽂網絡、⽣物網絡、交通網絡和社交網絡。圖神經網絡(GNNs)通過消息傳遞機制(Message passing mechanism)聚合鄰域節點的信息,在建模圖數據方⾯表現出了顯著的優勢。在 GNNs 的眾多應⽤中,節點分類是研究最為深入的任務之⼀。通常在節點分類任務中,GNNs 以半監督的模式進⾏訓練。
儘管圖神經網絡取得了成功,但它們在半監督圖學習任務中的表現高度依賴於精確的節點標籤,而在現實世界中,精確的標籤很難獲得。例如,對於在線社交⽹絡,手動標記數百萬⽤戶的過程成本⾼昂,因此⽤戶的標籤通常依賴於⽤戶⾃⼰的標註,這些標註通常是不可靠的。
此外,圖數據容易受到對抗性標籤翻轉攻擊的影響。因此,標籤噪聲在圖數據中普遍存在。研究表明,標籤噪聲會顯著降低機器學習模型在計算機視覺和自然語⾔處理場景中的泛化能力。在 GNNs 中,消息傳遞機制可能會通過傳播錯誤的監督信息,從而進⼀步加劇這種負⾯影響。
為了在帶標籤噪聲的圖數據上實現穩健學習,⼀個直觀的解決方案是借鑒以往標籤噪聲學習(LLN)策略的成功經驗,並將其應⽤於圖神經網絡。然而,由於圖數據並不具有獨立同分佈性質、節點標籤的稀疏性以及 GNNs 的消息傳遞機制,這些 LLN 方法並不總是適⽤於圖學習任務。在這個背景下,標籤噪聲下的圖神經⽹絡(GNNs under Label Noise, GLN)研究最近受到了關注。

然而,由於數據集選擇、數據分割和預處理技術的差異,⽬前 GLN 領域缺乏⼀個綜合的基準,這阻礙了對該領域的深⼊理解和進⼀步發展。
⼆、論文摘要
圖神經網絡(GNNs)通過消息傳遞機制在節點分類任務中表現出強大的潛力。然而,它們的性能往往依賴於⾼質量的節點標籤。在現實任務中,由於不可靠的來源或對抗性攻擊,準確的節點標籤很難獲得。因此,標籤噪聲在現實世界的圖數據中很常見。噪聲標籤會在訓練過程中傳播錯誤信息,從而對 GNNs 產生負⾯影響。
為瞭解決這個問題,標籤噪聲下的圖神經網絡(GNNs under Label Noise, GLN)的研究最近受到了關注。然而,由於數據集選擇、數據劃分和預處理技術的差異,社區⽬前缺乏⼀個全面的基準,這阻礙了對 GLN 的深入理解和進⼀步發展。為填補這⼀空⽩,我們在本⽂中介紹了 NoisyGL,這是第⼀個針對標籤噪聲下圖神經網絡的全⾯基準。NoisyGL 在各種數據集上,通過統⼀的實驗設置和接口,實現了對 GLN 方法的公平比較和詳細分析。我們的基準揭示了之前研究中遺漏的幾個重要⻅解,相信這些發現對未來的研究將非常有益。同時也希望我們的開源基準庫 NoisyGL 能促進該領域的進⼀步發展。
三、方案解讀
1、問題定義
考慮⼀個圖是邊的集合。


表示節點特徵矩陣,特徵的維度為 d 。每個節點都有⼀個真實標籤,真實標籤集合表示為
是鄰接矩陣,
,其中 V 是包含所有 N 個節點的集合,
在這項⼯作中,我們關注半監督節點分類問題,其中只有⼀小部分節點

被分配了⽤於訓練過程的標籤,這部分標籤表示為


是衡量預測標籤與真實標籤之間差異的損失函數。

通常是⼀個設計良好的圖神經網絡。通過這種方式,根據經驗風險最小化(Empirical Risk Minimization, ERM)原則,訓練良好的節點分類器可以在未⻅數據

上實現泛化。
,其中 c 是類別數量,
來訓練⼀個分類器
。給定 X 和 A ,節點分類的⽬標是通過最小化
是有標籤節點的數量。其餘的則是無標籤節點,表示為
,其中
然而,在現實世界中,可訪問的標籤

可能會受到標籤噪聲的汙染,從而降低
的泛化能力。我們將噪聲標籤表示為
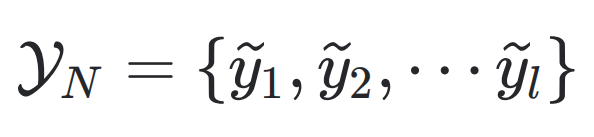 即為其對應的真實標籤。
即為其對應的真實標籤。通常,我們考慮兩種類型的標籤噪聲,以下是它們的定義:
-
均勻噪聲(Uniform Noise)或對稱噪聲:假設真實標籤有

,
我們有

,其中 c 表示類別數量。
的概率均勻地翻轉到其他所有的類別。形式上,對於
-
對偶噪聲(Pair Noise)或對偶翻轉、⾮對稱噪聲:假設真實標籤只能以概率 ϵ 翻轉到其對應的對偶類別,而不會翻轉到其他任何類別。
需要注意的是,這些噪聲模型假設轉移概率僅依賴於觀察到的標籤和真實標籤,即與實例特徵無關。而在現實世界中,標籤噪聲可能更加複雜。在這項工作中,我們關注最以上兩種常用的噪聲類型,將其他噪聲類型留給未來的研究。
在每次實驗中,我們⾸先根據給定的噪聲率和噪聲定義⽣成⼀個標籤轉移概率矩陣。然後,對於每⼀個訓練集和驗證集中的⼲淨標籤,我們根據其對應的轉移概率從 Categorical distribution 中抽取⼀個噪聲標籤。這些噪聲標籤將用於後續的訓練過程。

2、數據集選擇
我們選擇了 8 個節點分類數據集,這些數據集在不同的圖標籤噪聲研究中被⼴泛使⽤。這些選定的數據集來⾃不同領域,具有不同的特徵,使我們能夠評估現有⽅法在各種場景中的泛化能力。
具體來說,我們使用了三個經典的引⽂⽹絡數據集 Cora、Citeseer、Pubmed,以及⼀個作者合作網絡數據集 DBLP,還有兩個代表性的產品共購網絡數據集 Amazon- Computers 和 Amazon-Photo。此外,為了驗證各種方法在異質圖上的性能,我們使用了兩個代表性的社交網絡數據集 BlogCatalog 和 Flickr。對於每⼀種數據集,我們為其適配最為常用的訓練 – 測試 – 驗證集劃分方法,以確保對各種方法進行公平比較。

3、方法選擇
我們選擇了⼀系列最先進的 GLN 算法,包括 NRGNN、RTGNN、CP、D-GNN、 RCNGLN、CLNode、PIGNN、UnionNET、CGNN 和 CRGNN;以及⼀組設計良好的 LLN 方法,包括兩種損失修正方法 Forward Correction 和 Backward Correction、兩種穩健損失函數 APL 和 SCE、兩種多網絡學習方法 Coteaching 和 JoCoR,以及⼀種噪聲適應層方法 S- model。並根據它們的論⽂和源代碼嚴格地複現了所有⽅法。
4、期望研究的問題
在這項工作中,我們旨在回答以下問題:
RQ1:LLN ⽅法能否直接應⽤於圖學習任務?
動機:儘管最近的研究表明,直接將傳統的標籤噪聲下的學習(Learning with Label Noise, LLN)⽅法應用於圖學習任務可能不會產⽣最佳結果,但⽬前對這⼀問題仍然缺乏全⾯的分析。因此,我們希望調查現有 LLN ⽅法對圖學習的適⽤性並理解其背後的原因。通過研究這個問題,我們可以更清楚地瞭解圖標籤噪聲帶來的獨特挑戰,並確定哪些 LLN 技術在圖學習環境中仍然有效。
實驗設計:我們選擇了在前文中提到的 7 種 LLN 方法,並以 GCN 作為骨幹模型實現這些方法。然後,我們在八種具有不同性質的數據集上進行節點分類實驗,評估它們在不同類型和水平的標籤噪聲下的有效性。對於每種方法和數據集,我們記錄了 10 次運⾏的平均準確率指標和標準差。通過比較這些 LLN 方法的性能,我們可以確定額外的 LLN 方法是否增強了骨幹 GCN 模型的穩健性。
RQ2: 現有的 GLN 方法取得了多大進展?
動機:儘管先前的研究提出了許多 GLN 方法,但它們使⽤了不同的數據集、數據劃分和預處理技術,使得我們難以公平⽐較這些⽅法的性能。此外,我們注意到⼤多數現有⽅法是在同質圖上進⾏評估的,這引發了它們在異質圖上適⽤性的擔憂,⽽異質圖在實際中也很常⻅。通過研究這個問題,我們希望確定當前的 GLN ⽅法是否有效地解決了圖標籤噪聲問題,並找出它們的不⾜之處。
實驗設計:我們實現了前⽂中描述的 10 種先進的 GLN ⽅法,然後使⽤ 8 個具有不同性質的數據集和統⼀的實驗設置評估這些⽅法的性能。對於每種⽅法和數據集,記錄了 10 次運⾏的平均測試準確率和標準差。由於這些 GLN ⽅法多數基於 GCN,我們在這些⽅法的代碼實現中調⽤⼀個統⼀的 GCN ⻣⼲模型,以公平地評估它們對標籤噪聲的穩健性。
RQ3: 現有的 GLN ⽅法計算效率如何?
動機:GLN 的計算效率對於其在現實世界中的應⽤至關重要,⽽考慮標籤噪聲可能會導致更⾼的計算開銷。儘管先前的研究深入探討了 GLN 方法的準確性、泛化能⼒和穩健性,但卻忽略了對這些方法計算效率的研究。
實驗設計:我們記錄了在 30% 均勻噪聲下各種方法在不同數據集上的運⾏時間和測試準確率。具體來說,對於每種方法在每個數據集上進行了 10 次實驗。在每次實驗中測量模型在驗證集上達到最佳準確率時的時間,並將其視為該⽅法的總運行時間。通過這些實驗可以評估 GLN 方法在計算效率和測試準確率之間是否達到了平衡。
RQ4:現有的 GLN ⽅法對噪聲率敏感嗎?
動機:之前的研究使用了不同的標籤噪聲率,這使得我們難以橫向比較各種方法的性能。因此,有必要使用⼀組⼀致的噪聲率來驗證現有的 GLN 方法是否在不同噪聲水平下保持穩定的性能。
實驗設計:我們在相同的數據集和噪聲類型下評估幾種 GLN 方法在不同噪聲水平下的性能。具體來說,引入了 10%、20%、30%、40% 和 50% 的標籤噪聲,並使⽤乾淨標籤作為基線。隨後,按照 RQ2 中描述的實驗設置在這些數據集上訓練並評估 GLN 方法。
RQ5:現有的 GLN ⽅法對不同類型的標籤噪聲下表現如何?
動機:現有的 GLN 方法是基於各種技術和假設開發的,因此在處理不同類型的噪聲時,它們具有獨特的優勢和劣勢。此外,確定哪種類型的噪聲對圖學習最具破壞性並理解其背後的原因是至關重要的。解決這個問題將有助於我們更好地理解每種方法的具體適⽤場景以及不同類型標籤噪聲的獨特特性。
實驗設計:我們保持 30% 的噪聲率不變,並對標籤應⽤均勻噪聲和對偶噪聲。隨後,按照 RQ2 中描述的實驗設置在這些噪聲數據集上訓練並評估 GLN 方法。
RQ6:好還是壞?重新審視圖結構在標籤噪聲中的作⽤。
動機:額外的圖結構區分了圖數據和其他類型的⾮ i.i.d. 數據。而圖神經⽹絡的成功在很大程度上依賴於消息傳遞機制,該機制從圖結構上的鄰域節點聚合信息。然而,在存在標籤噪聲的情況下,沿著邊傳播的消息可能有雙重效果:⼀方面,標籤噪聲通過傳播錯誤信息對圖學習產生負⾯影響;另⼀⽅⾯,它也可能通過與鄰居中的多數標籤對⻬來緩解這種影響。因此,至關重要的是研究額外的圖結構是否會放⼤標籤噪聲的影響,以及現有的⽅法是否能有效解決這⼀挑戰。
實驗設計:我們對全部十八種方法進⾏了全面的實驗,包括⼀個 GCN 基線、七種 LLN 方法和十種 GLN 方法,旨在明確圖結構在標籤噪聲存在的情況下如何影響圖學習。具體來說,我們記錄了以下幾個指標,包括在 30% 均勻噪聲下的正確標記的訓練節點的預測準確率(ACLT)、錯誤標記的訓練節點的預測準確率(AILT)、正確監督的未標記節點的預測準確率(AUCS)、未監督的未標記節點的預測準確率(AUU)和錯誤監督的未標記節點的預測準確率(AUIS)。這⾥,「正確監督」、「錯誤監督」和「未監督」分別指的是在未標註節點的鄰域中有正確標記的訓練節點、錯誤標記的訓練節點以及沒有標記節點的未標記節點。
四、實驗結果及分析
結論 1:大多數 LLN 方法並未顯著提高 GNN 對標籤噪聲的穩健性(RQ1)。
實驗結果顯示,存在標籤噪聲的情況下,大多數選定的 LLN 方法並未顯著提⾼ GNN 骨幹的性能。大多數情況下,這些 LLN 方法的性能在統計上與基線相似。在某些情況下,應⽤額外的 LLN ⽅法甚至可能會導致更差的結果。

三種包含噪聲轉移矩陣的 LLN 方法 S-model、Forward Correction 和 Backward Correction,在大多數情況下表現與基線相似。通常,這些基於轉移矩陣的方法學習到的是對⻆轉移矩陣,這表明由於標籤的稀缺,它們未能學習正確的標籤轉移模式。多網絡學習方法 Coteaching 和 JoCoR 在稀疏圖上表現與基線相似,但在密集圖上表現不佳。值得注意的是,我們發現兩種穩健損失函數,主動被動損失(APL)和對稱交叉熵(SCE),在⼀些數據集上略微增強了基線模型的穩健性。這種改進可能是由於它們能夠減少對錯誤標記樣本的過擬合,而它們的獨⽴同分佈假設則限制了這種改進的幅度。因此得出結論,僅僅將 LLN 方法應用於 GNN 並不能實現對標籤噪聲穩健的圖學習解決⽅案。
結論 2:現有的 GLN ⽅法在⼤多數情況下可以緩解標籤噪聲,但這種改進僅限於特定的適⽤場景(RQ2)
對於每個數據集,總有⾄少⼀種 GLN 方法的抗噪能力優於基線 GCN,這表明這些 GLN 方法在緩解圖標籤噪聲問題上是有效的。然⽽,沒有⼀種方法能在所有數據集中始終表現良好。例如,NRGNN 在 Cora、Citeseer 和 DBLP 數據集中顯著優於基線 GCN,但在其他數據集中則不然。這⼀結果表明,現有的 GLN 方法缺乏在不同類型數據中泛化的能力。此外,我們觀察到在 Flickr 數據集中,所有 GLN 方法的表現都不如基線,這突顯了它們在處理⾼度異質圖⽅⾯的不⾜。

結論 3:⼀些 GLN 方法的計算效率不高(RQ3)
儘管多種 GLN 方法在減少標籤噪聲方面有效,但通常需要大量計算資源。實驗結果表明,⼀些 GLN 方法在性能與計算效率之間難以平衡。例如,在 Cora 數據集上,RNCGLN 是最慢的,比 GCN 慢 66.8 倍,而在 DBLP 數據集上更是慢了驚人的 2945.8 倍。而在另⼀⽅⾯,雖然 NRGNN 方法也比 GCN 消耗更多時間,但它在兩個數據集上實現了性能與計算效率之間的合理平衡。

結論 4:大多數 GLN 方法在嚴重噪聲下無法保證高性能(RQ4)
在通常情況下,隨著噪聲水平的增加,每種方法的測試準確率都會下降。這種下降在對偶噪聲中最為顯著,在 50% 對偶噪聲下,所有方法的測試準確率⼏乎減半。此外,我們注意到在所有數據集上 RTGNN 在均勻噪聲下表現相對穩定,並且 NRGNN 和 PIGNN 兩種方法在不同噪聲水平和類型下,在 DBLP 數據集上的表現優於基線 GCN。

結論 5:對圖學習來說,對偶噪聲更具危害性(RQ5)
在實驗中,我們觀察到對偶噪聲對模型的泛化能力構成了最顯著的威脅。我們對此發現有⼀個解釋:回顧在前文中提供的定義。對於均勻噪聲,真實標籤有可能翻轉到任何其他類別,這可能由於被錯誤標註的節點導致的不正確參數更新可以被其他錯誤標註的節點部分抵消。然⽽,對偶噪聲將翻轉類別限制為特定的對偶類別。對於分類器來說,這種類型的對偶翻轉可能更具誤導性。在完全訓練後,分類器更有可能過擬合這些對偶標籤,從而作出對偶類別的預測。當節點特徵通過消息傳遞機制傳播時,這種情況尤其有害,這可能導致局部鄰域內的嵌⼊更加相似,從⽽使得它們更有可能被錯誤分類到相應的對偶類別。
為了驗證該假設,我們進行了實證研究。具體來說,我們記錄了在 50% 對偶和均勻噪聲下 GCN 在五個數據集上的誤導性訓練準確率。這⾥的誤導性訓練準確率(AILMT)代表模型在對錯誤分類的類別做出錯誤預測時的準確率,可以體現模型的過擬合程度。實驗結果清楚地表明,對偶噪聲的對模型泛化能力的影響最大,更可能導致模型模型過擬合到錯誤的標籤上。同樣的情況也發⽣在其他 LLN 和 GLN 方法中。

結論 6:圖結構可以放大標籤噪聲的負面影響(RQ6)
從實驗結果來看,我們觀察到在稀疏圖(Cora)中,AUIS 和 AUU 相較於 AUCS 顯著下降。以 GCN 在 Cora 數據集上的表現為例,這種下降分別為 36.17% 和 10.85%。這些結果突顯了鄰居節點通過正確的標籤對未標註節點進行正確監督對 GNN 的學習過程⾄關重要。被正確標註的鄰域節點提供的正確監督顯著提⾼了未標記節點的分類準確率,而標籤噪聲造成的錯誤監督則嚴重降低了這些節點的分類準確率,甚至比不進⾏鄰域監督時更糟。
此外,我們的研究還揭示了圖結構增強方法在減輕標籤噪聲傳播效應⽅⾯的有效性。具體來說,基於圖結構增強的三種方法,即 NRGNN、RTGNN 和 RNCGLN,在所有方法中的 AUIS 相較於 AUCS 和 AUU 表現出了最小的下降。這表明它們可以有效減輕標籤噪聲的傳播效應。這種現像在像 Cora 這樣的稀疏圖中更加明顯。⼀個可能的解釋是它們採用的額外圖結構學習技術可以在采樣過程中形成⽤於預測的更密集的圖結構。因此,分類器可以獲得更多來⾃鄰域節點的參考,從⽽減少對鄰域錯誤標記樣本的依賴。

結論 7:稀疏圖更容易受到標籤噪聲傳播效應的影響(RQ6)
從 Table 2 中可以看出,標籤噪聲的傳播效應在平均度較低的稀疏圖(如 Cora、 Citeseer、Pubmed 和 DBLP)上非常嚴重,但在密集圖(如 Amazon-Computers、 Amazon-Photos、Blogcatalog 和 Flickr)上則不明顯。對此現象的解釋是:稀疏圖上的未標記節點在其鄰域中通常只有有限數量的標註節點可用於監督,所以這些未標註節點的預測結果在很大程度上依賴於其鄰域中有限的標註節點,如果這些節點被錯誤標註,則很容易導致未標註節點表示的錯誤學習。相比之下,對於密集圖,未標註節點的鄰域包含許多可以作為參考的標註節點。
因此,分類器模型更有可能從這些標註節點中找到正確的監督。這⼀假設得到了 Table 1 中實驗結果的進⼀步⽀持,我們觀察到,與稀疏圖(如 Cora、Citeseer 和 Pubmed)相⽐,GCN 在具有⾼平均節點度的密集圖(如 Blogcatalog 和 Amazon-Computers)上更不容易產⽣過擬合。
五、實踐落地與持續研究
本文提出的針對標籤噪聲下圖神經⽹絡的綜合基準,可幫助阿里相關團隊更精準地評估圖相關技術在落地時的整體風險數據,並⾼效推進後續相關的算法落地和應用。最後,我們也為該領域未來的研究提供了⼀些思路:
-
設計廣泛適用的 GLN 方法。⼤多數現有的 GLN 方法無法在所有場景中確保⼀致的高性能,尤其在高度異質的圖中。為瞭解決這個問題,我們可能需要探索幾個關鍵問題:a)不同圖數據集的共同屬性是什麼?b)如何利用這些共同屬性增強 GNNs 對標籤噪聲的穩健性?我們的實驗結果表明增強圖結構可以減少標籤噪聲在不同密度圖中的傳播,進而引出第三個問題:c)如果難以識別共同屬性,我們能否通過數據增強來統⼀這些特徵?
-
為各種圖學習任務設計 GLN 方法。先前對 GLN 的研究主要集中在節點分類任務上。然而,圖學習領域還包括其他重要應⽤,如鏈路預測、邊屬性預測和圖分類等。這些應用也可能受到標籤噪聲的影響,需要進⼀步關注和探索。
-
考慮圖學習中的其他類型標籤噪聲。先前對 GLN 的研究假設圖數據中存在兩種實例無關的標籤噪聲,即對偶噪聲和均勻噪聲。然二,更為現實的假設是實例相關標籤噪聲,但目前尚未有相關的工作。此外,與其它領域的數據不同,圖數據存在額外的圖結構,圖結構很有可能影響圖數據的標註過程,因此圖數據的標籤噪聲模型很可能與圖拓撲結構相關。




















