Anthropic讓AI像人一樣用電腦,支持開發者通過API配置和調用
起猛了!一覺醒來,AI學會像人類一樣操作電腦了!
當地時間10月22號,知名AI初創公司Anthropic發佈了Claude 3.5模型家族的更新:新模型Claude 3.5 Haiku發佈,同時現有模型Claude 3.5 Sonnet獲得了升級。
最為驚喜的是,升級版Claude 3.5 Sonnet不僅在各項性能指標上取得顯著提升,更是獲得了一項革命性的新技能:能夠像人類一樣操作電腦。

儘管我們現在幾乎每天都能看到AI技術的更新,但這一新突破足以刷新人們的認知,也標誌著AI技術在實際應用領域邁出了關鍵性的一步。
這項功能名為Computer Use(計算機使用),目前處於Beta公測階段,僅支持開發者通過API配置和調用。網頁端的Claude版本雖然已經更新到了Claude 3.5 Sonnet (New),但並沒有這項功能。
具體來說,Claude能夠通過觀看屏幕截圖,實現移動光標、點擊按鈕、使用虛擬鍵盤輸入文本等操作,真正模擬人類與計算機交互的方式。
 圖 | Claude演示影片,它正在操作電腦,debug一段代碼(來源:Anthropic)
圖 | Claude演示影片,它正在操作電腦,debug一段代碼(來源:Anthropic)「這對於 AI 模型來說是一項全新的能力。」Anthropic開發者關係負責人亞曆克斯·艾伯特(Alex Albert)在X平台上寫道,「我們不是為單個任務開發定製工具,而是向 Claude 傳授基本的計算機技能,讓它能夠自然地使用人們日常使用的相同軟件和工具。」
這意味著AI助手終於可以突破傳統框架的束縛,直接使用為人類設計的各類軟件,而不再局限於專門定製的工具。這將為AI在現實世界中的應用開闢全新的可能。
在demo演示中,亞曆克斯展示了如何讓Claude使用Computer Use功能打開Claude網頁,然後使用Artifact功能編寫代碼:

Claude 還能找到並打開電腦上的其他軟件,比如VSCode:
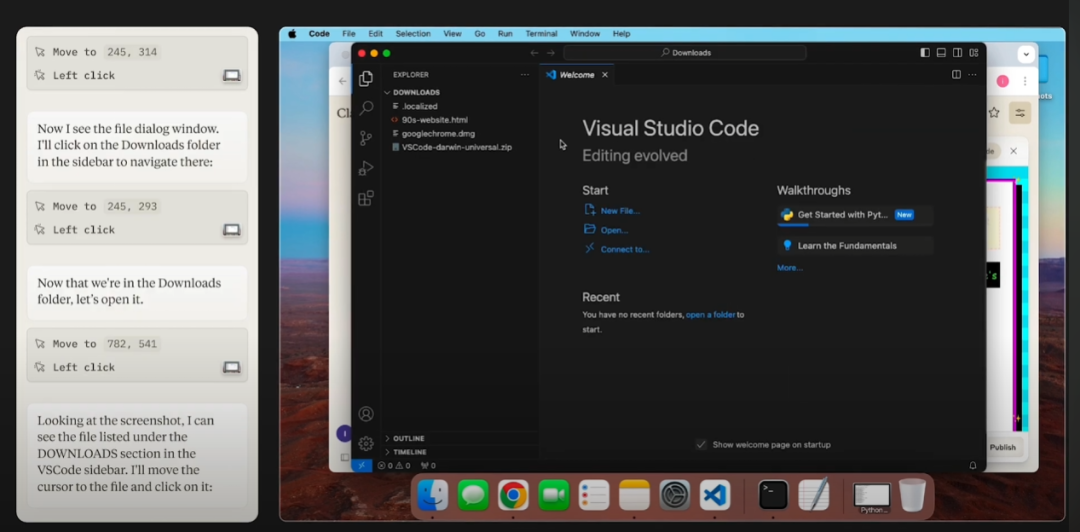
在多個演示影片中,我們可以看到,Claude能夠絲滑地操作電腦執行打開軟件、網頁搜索、文本輸入、編寫代碼、下載文件、debug、查找網頁表格並填入信息等任務,甚至還能打開外賣平台訂餐。
 圖 | Claude 點的外賣(來源:亞曆克斯)
圖 | Claude 點的外賣(來源:亞曆克斯)據介紹,Asana、Canva、Cognition、DoorDash、Replit 和 The Browser Company 等多家公司已經在探索Claude的新功能,執行原本需要數十步甚至數百步才能完成的任務。
在研究人員的測試過程中,Claude也出現過一些令人忍俊不禁的失誤。比如,它曾意外地終止了一次長時間的屏幕錄製,導致所有錄像丟失;另一次在進行代碼演示時,它突然對黃石國家公園產生了濃厚興趣,於是打開瀏覽器開始悠閑地搜索起來。
這些失誤說明該技術仍存在很大的提升空間。
數據顯示,儘管Claude在使用電腦方面的表現已經達到了業界領先水平:它在OSWorld電腦操作評估測試中獲得了14.9%的成績,遠超其他AI模型的7.8%最高分,但與人類的70-75%的水平相比仍有相當大的差距。
當用戶提供更多完成任務所需的步驟時,Claude的得分可以提升到22.0%。
目前,一些對人類來說輕而易舉的電腦操作,如滾動、拖拽和縮放等,對Claude來說仍具有相當的挑戰性。此外,由於它是通過連續的截圖來「觀察」屏幕,而不是更細粒度的影片流,這使得它可能會錯過一些間隔較短的操作或通知。
升級版Claude 3.5 Sonnet性能如何?
在各種基準測試的考驗下,新版Claude 3.5 Sonnet的表現依舊亮眼。
在軟件工程方面,它在SWE-bench Verified評測中的得分從33.4%大幅躍升至49.0%,一舉超越了包括OpenAI o1-preview在內的所有公開可用模型。
 (來源:Anthropic,亞曆克斯)
(來源:Anthropic,亞曆克斯)在零售領域的TAU-bench測試中,其表現從62.6%提升到69.2%,在難度更高的航空領域測試中也從36.0%提升至46.0%。這些數據充分證明了其在複雜任務處理方面的顯著進步。
在推理方面,新版Claude 3.5 Sonnet的推理測試基準GPQA (Diamond) 成績為65%,超過了GPT-4o的53.6%。不過OpenAI o1-preview並不在對比之列,Anthropic給出的理由是,「該系列模型依賴大規模回覆前計算時間,與一般模型不同」。

知名開發平台GitLab對新版Claude進行的測試顯示,在DevSecOps任務中,模型的推理能力提升了10%,且沒有增加任何延遲。Browser Company在使用該模型實現網頁工作流自動化時也發現,新版Claude的表現超越了他們之前測試過的所有模型。
與此同時,新版Claude 3.5 Sonnet的價格並未改變:每百萬輸入Token 3美元,每百萬輸出Token 15美元。
此次更新中,Anthropic還正式推出了Claude 3.5 Haiku。它是Claude 3.5系列里體積最小,但響應速度最快的模型。
與前輩Claude 3 Haiku相比,它的各項技能都得到了全面提升,甚至在多個智能基準測試中超越了上一代最強模型Claude 3 Opus。
在SWE-bench Verified測試中,Haiku獲得了40.6%的高分,超過了許多使用最先進模型的AI智能代理。
Anthropic表示,憑藉其低延遲、更準確的指令執行能力和工具使用能力,Haiku特別適合需要大量交互的面向用戶的產品,以及使用海量數據生成個性化體驗。
Claude 3.5 Haiku預計將於本月晚些時候推出,可用平台包括Anthropic API、Amazon Bedrock和Google雲Vertex AI。起初它僅支持純文本輸入,未來將加入圖像輸入功能。
Claude 3.5 Haiku的定價是每百萬輸入Token 0.25美元,每百萬輸出Token 1.25美元。

值得注意的是,目前Claude 3.5模型系列仍有Opus尚未亮相。這應該是其中體積最大、性能最強的模型。
考慮到AI技術可能被濫用於製造垃圾信息、傳播錯誤信息或實施欺詐等行為,而且它現在還能直接操控用戶電腦,Anthropic在放出更新的同時,格外強調了對模型安全性的重視。
該公司專門開發了新的分類器和其他方法來識別和減輕潛在的濫用風險。特別是考慮到即將到來的美國大選,他們加強了對相關活動的監控力度並建立了相應機制,引導Claude避開某些敏感電腦操作,如在社交媒體發佈內容、註冊網站域名或與政府網站交互等。
安全性驗證方面,新版Claude 3.5 Sonnet已經通過了美國AI安全研究所(US AISI)和英國安全研究所(UK AISI)的聯合測試。
根據Anthropic的負責任擴展政策(Responsible Scaling Policy),新版Claude 3.5 Sonnet仍然保持在AI安全等級2級(ASL-2),這表明現有的安全和保安措施足以應對其帶來的風險。
該公司特別強調,他們不會將用戶提交的數據(包括Claude接收到的屏幕截圖)用於訓練生成式AI模型。
對於「提示注入」類網絡攻擊,Anthropic也採取了防範措施。由於Claude能夠解釋來自互聯網的屏幕截圖,因此可能會接觸到包含惡意指令的內容,這些指令可能會導致原有指令被覆蓋或執行與用戶原意相違背的操作。
 圖 | Anthropic提醒開發者注意風險(來源:Anthropic)
圖 | Anthropic提醒開發者注意風險(來源:Anthropic)為此,該公司為開發者提供了詳細的實施參考指南,幫助他們採取相應的預防措施,其中包括:
1.使用具有最小權限的專用虛擬機或容器,以防止直接的系統攻擊或事故。
2.避免讓模型訪問敏感數據,例如帳戶登錄信息,以防止信息盜竊。
3.將互聯網訪問限制在域名允許列表中,以減少接觸惡意內容的機會。
4.要求人類確認可能導致有意義的現實世界後果的決定,以及任何需要徵求同意(授權)的任務,例如接受 cookie、執行金融交易或同意服務條款。
儘管AI直接操作電腦的技術仍有局限性和隱藏風險,但它所代表的突破性進展仍然令人興奮。它預示著AI技術正在向著更加實用和智能的方向邁進。通過不斷改進和完善,我們有理由相信,AI助手將在未來變得更快、更可靠,能更好地滿足用戶的各種需求。
正如Anthropic開發者關係負責人所說:「Computer Use功能是邁向全新人機交互形式的第一步。再過幾年,我們與計算機交互的方式將與今天完全不同。」
參考資料:
https://www.anthropic.com/news/3-5-models-and-computer-use
https://docs.anthropic.com/en/docs/build-with-claude/computer-use
https://www.anthropic.com/news/developing-computer-use



















