科學家提出存內計算全新技術路徑,提升AI模型計算能效3個數量級
隨著大數據時代 AI 模型參數量激增,AI 模型推理和訓練的成本日益增高,使得 AI 模型難以有效地被佈署到邊緣計算設備中。
存內計算技術是加速 AI 模型的主流路徑,它通過在存儲器內部原位計算減少數據的搬運,來提高芯片算力與能效。
但是,需要瞭解的是,傳統存內計算(single-IMC,single-in-memory computing)架構仍然需要在存儲器和處理器之間進行數據傳輸,僅部分地解決了數據搬運的問題,限制了 AI 模型加速器的進一步發展。
為瞭解決上述問題,北京大學孫仲研究員團隊設計了一種全新技術路徑的存內計算架構,稱為「雙存內計算」(dual-IMC,dual in-memory computing)。
該架構能夠最大程度地加速 AI 模型中的矩陣-向量乘法(MVM,matrix-vector multiplication)計算,如卷積神經網絡、二值神經網絡、Transformer 模型等,從而實現高速、高能效的 AI 模型推理和訓練。
該架構基於非易失性存儲器陣列設計,使 MVM 的矩陣、向量元素均存儲在內存陣列中並參與原位 MVM 運算。
「這種獨特的設計可完全消除數據的搬運,最大程度地發揮存內計算的優勢,從而實現真正意義上的存儲器內計算。」孫仲表示。
與傳統的存內計算架構相比,dual-IMC 架構使 MVM 的能效提高了 3 到 4 個數量級,有望應用於邊緣計算系統和終端設備部署中,以構建先進的神經網絡加速器。
 圖丨孫仲課題組(來源:該團隊)
圖丨孫仲課題組(來源:該團隊)北京航空航天大學康旺教授對該研究評價稱,該團隊提出並演示了一種用於矩陣向量乘法的全存內計算新方法,使得參與運算的權重矩陣和向量都可以存儲在陣列中並參與原位計算,從而有望完全消除數據移動,提高存內計算的能效。
他指出,「該工作雖然目前僅展示了較小規模的演示,但理論上可以擴展到更大規模陣列。這是一個很新穎的想法,相信未來它會對存內計算領域(學術界和業界)產生實際的影響。」
北京大學博士研究生王識清是論文第一作者,孫仲研究員擔任通訊作者。
圖丨相關論文(來源:Device)
目前,神經網絡計算加速是發展計算範式和架構的主要驅動力。在神經網絡的推理和訓練過程中,計算量最大的操作為 MVM。因此,利用非易失性存儲器加速 MVM 成為當下學術界和工業界關注的熱點方向。
 圖丨存內計算技術全譜(來源:Nature Electronics)
圖丨存內計算技術全譜(來源:Nature Electronics)但是,在加速 MVM 的傳統存內計算架構中,只有一個輸入操作數,即權重矩陣存儲在內存陣列中,而另一個輸入操作數,即輸入向量仍然要在傳統的馮·諾依曼架構中流動。
這需要通過訪存片外主存和片上緩存,再經過數模轉換之後作為模擬電壓向量輸入到陣列中進行 MVM 計算。
也就是說,傳統的 single-IMC 僅部分地解決了馮·諾伊曼瓶頸問題,其仍然會帶來數據搬運和數模轉換的沉重負擔,這從根本上限制了計算性能的提高。
此外,為了保證高計算並行度,計算時要同時開啟多行字線,這會導致陣列中產生較大的電流,這是 single-IMC 架構的另一個缺點。
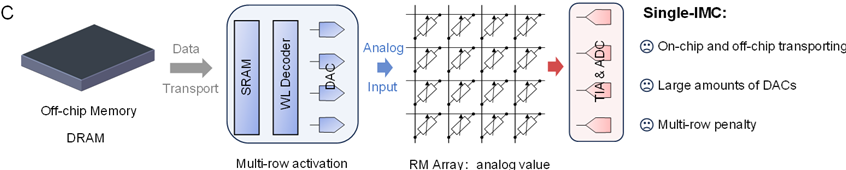 圖丨傳統的單存內計算(single-IMC)架構(來源:Device)
圖丨傳統的單存內計算(single-IMC)架構(來源:Device)2023 年,孫仲課題組與合作者在 Nature Electronics 上發表論文,提出存內計算技術全譜的概念,並對所有類型的存內計算技術進行了原理性的分類 [2]。
此外,該團隊還在 Science Advances 報導了一種基於阻變存儲器陣列的新型模擬計算電路,使微秒級一步求解複雜的壓縮感知還原成為可能 [3]。
受存內計算技術全譜概念的啟發,研究人員設計了將兩個輸入操作數都存儲在內存中的 dual-IMC 架構,其中矩陣(神經網絡權重)和向量(神經網絡輸入)都存儲在同一陣列中,以參與加速 MVM 的原位計算。
雙存內計算架構基於團隊在壓縮感知還原電路設計中原創的電導補償原理設計,僅需要施加極為簡單的獨熱編碼的數字電壓,就可以完成 MVM 計算。
計算過程中無需數模轉換器,從而進一步節省芯片面積,優化了計算的延時和功耗。此外,每次 MVM 計算僅激活存儲器陣列的一行字線,這能夠減少陣列中累積的電流。
因此,dual-CIM 架構完全消除了片外動態隨機存取存儲器(DRAM,Dynamic Random Access Memory)和片上靜態隨機存取存儲器(SRAM,Static Random-Access Memory)訪存造成的額外延時和功耗,同時也避免了這些易失性存儲器的靜態功耗。
王識清表示:「這一創新的技術路徑不僅簡化了硬件結構,而且在性能上也取得了顯著的提升。即便在最壞情況,在需要對特殊介質進行寫入時,雙層存內計算架構仍能提供數倍的性能提升。」
 圖丨雙存內計算(dual-IMC)架構(來源:Device)
圖丨雙存內計算(dual-IMC)架構(來源:Device)基於製備的阻變存儲器陣列,該團隊對 dual-IMC 架構進行了概念性的實驗驗證,並演示了該架構在壓縮信號還原、卷積神經網絡和二值神經網絡中的應用。
總的來說,該研究為後摩亞時代的計算性能提升提供了一種全新的技術方案,通過完全在存儲器內部進行的矩陣-向量乘法操作,實現了顯著的加速和能效優化,為神經網絡和其他重要算法的硬件實現提供了新的可能性。
 參考資料:
參考資料:1.Wang,S.,Sun,Z. Dual in-memory computing of matrix-vector multiplication for accelerating neural networks. Device(2024). https://doi.org/10.1016/j.device.2024.100546
2.Sun, Z., Kvatinsky, S., Si, X. et al. A full spectrum of computing-in-memory technologies. Nature Electronics 6, 823–835 (2023). https://doi.org/10.1038/s41928-023-01053-4
3.Wang,S. et al. In-memory analog solution of compressed sensing recovery in one step. Science Advances 9,50(2023). https://www.science.org/doi/10.1126/sciadv.adj2908
排版:劉雅坤



















