AI讓手機任務自動「跑」起來!我國高校最新研究,簡化移動設備操作
MOE KLINNS Lab投稿
量子位 | 公眾號 QbitAI
AI解放碳基生物雙手,甚至能讓你的手機自己玩自己!
你沒聽錯——這其實就是移動任務自動化。
在AI飛速發展下,這逐漸成為一個新興的熱門研究領域。
移動任務自動化利用AI精準捕捉並解析人類意圖,進而在移動設備(手機、平板電腦、車機終端)上高效執行多樣化任務,為那些因認知局限、身體條件限制或身處特殊情境下的用戶提供前所未有的便捷與支持。
-
幫助視障人群用戶完成導航、閱讀或網上購物
-
輔助老年人使用手機,跨越數字鴻溝
-
幫助車主在駕駛過程中完成發送短信或調節車內環境
-
替用戶完成日常生活中普遍存在的重覆性任務
-
……
媽媽再也不嫌重覆設置多個日曆事項會心煩了。
最近,來自西安交通大學智能網絡與網絡安全教育部重點實驗室 (MOE KLINNS Lab)的蔡忠閩教授、桑治雲鵬副教授團隊(團隊主要研究方向為智能人機交互、混合增強智能、電力系統智能化等),基於團隊最新AI研究成果,創新性提出了基於視覺的移動設備任務自動化方案VisionTasker。
這項研究不僅為普通用戶提供了更智能的移動設備使用體驗,也展現出了對特殊需求群體的關懷與賦能。

基於視覺的移動設備任務自動化方案
團隊提出了VisionTasker,一個結合基於視覺的UI理解和LLM任務規劃的兩階段框架,用於逐步實現移動任務自動化。
該方案有效消除了表示UI對視圖層次結構的依賴,提高了對不同應用界面的適應性。
值得注意的是,利用VisionTasker無需大量數據訓練大模型。
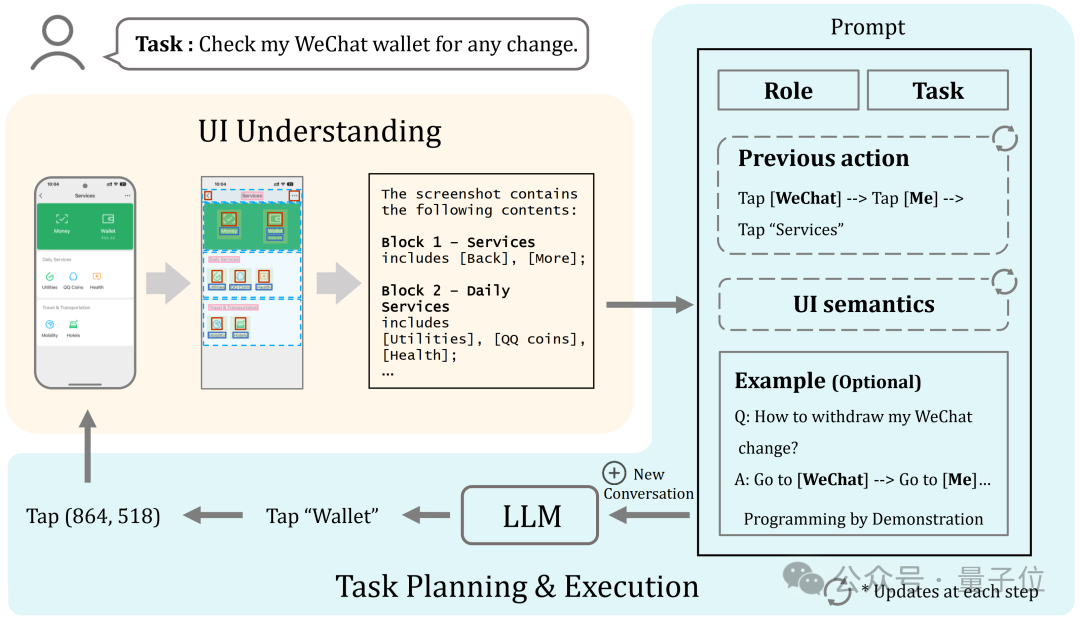
VisionTasker從用戶以自然語言提出任務需求開始工作, Agent開始理解並執行指令。
具體實現如下:
1、用戶界面理解
VisionTasker通過視覺的方法做UI理解來解析和解釋用戶界面。
首先Agent識別並分析用戶界面上的元素及佈局,如按鈕、文本框、文字標籤等。
然後,將這些識別到的視覺信息轉換成自然語言描述,用於解釋界面內容。
2、任務規劃與執行
接下來,Agent利用大語言模型導航,根據用戶的指令和界面描述信息做任務規劃。
將用戶任務拆解為可執行的步驟,如點擊或滑動操作,以自動推進任務的完成。
3、持續迭代以上過程
每一步完成後,Agent都會根據最新界面和歷史動作更新其對話和任務規劃,確保每一步的決策都是基於當前上下文的。
這是個迭代的過程,將持續進行直到判斷任務完成或達到預設的限制。
用戶不僅能從交互中解放雙手,還可以通過可見提示監控任務進度,並隨時中斷任務,保持對整個流程的控制。
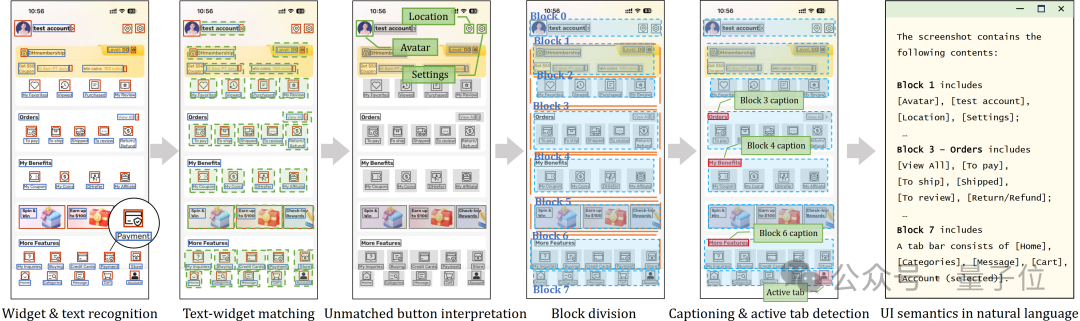
首先是識別界面中的小部件和文本,檢測按鈕、文本框等元素及其位置。
對於沒有文本標籤的按鈕,利用 CLIP 模型基於視覺設計來推斷其可能功能。
隨後,系統根據 UI 佈局的視覺信息進行區塊劃分,將界面分割成多個具有不同功能的區塊,並對每個區塊生成自然語言描述。
這個過程還包括文本與小部件的匹配,確保正確理解每個元素的功能。
最終,所有這些信息被轉化為自然語言描述,為大語言模型提供清晰、語義豐富的界面信息,使其能夠有效地進行任務規劃和自動化操作。
實驗評估
實驗評估部分,該項目提供了對三種UI理解的比較分析,分別是:
-
GPT-4V
-
VH(視圖層級)
-
VisionTasker方法
 △
△三種UI理解方法的比較分析
對比顯示,VisionTasker在多個維度上比其他方法有顯著優勢。
此外,在處理跨語言應用時也表現出了良好的泛化能力。
 △ 實驗1中使用到的常見UI佈局
△ 實驗1中使用到的常見UI佈局表明VisionTasker的以視覺為基礎的UI理解方法在理解和解釋UI方面具有明顯優勢,尤其是在面對多樣化和複雜的用戶界面時尤為明顯。
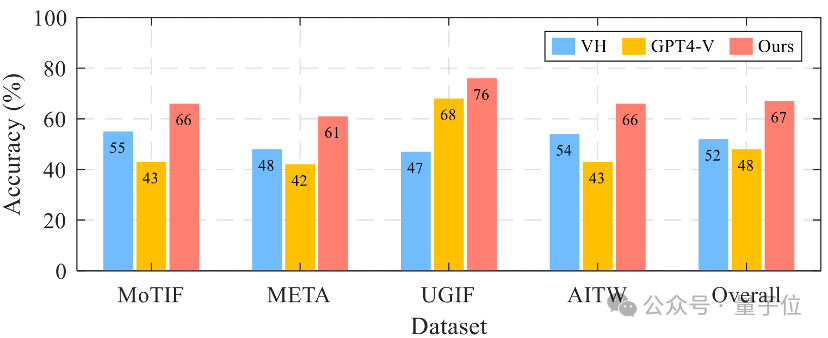 △
△跨四個數據集的單步預測準確性
文章還進行了單步預測實驗,根據當前的任務狀態和用戶界面,預測接下來應該執行的動作或操作。
結果顯示,VisionTasker在所有數據集上的平均準確率達到了67%,比基線方法提高了15%以上。
真實世界任務:VisionTasker vs 人類
實驗過程中,研究人員設計了147個真實的多步驟任務來測試VisionTasker的表現,這些任務涵蓋了國內常用的42個應用程序。
與此同時,團隊還設置了人類對比測試,由12名人類評估者手動執行這些任務,然後VisionTasker的結果進行比較。
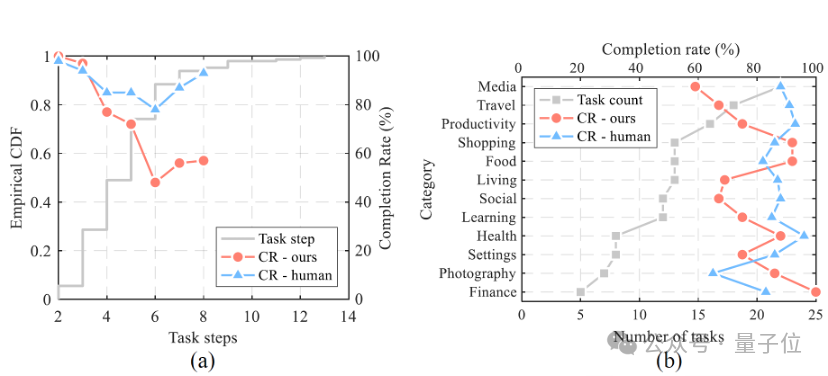
結果顯示,VisionTasker在大多數任務中能達到與人類相當的完成率,並且在某些不熟悉的任務中表現優於人類。

△實際任務自動化實驗的結果 「Ours-qwen」是指使用開源Qwen實現VisionTasker框架,」Ours」表示使用文心一言作為LLM
團隊還評估了VisionTasker在不同條件下的表現,包括使用不同的大語言模型(LLM)和編程演示(PBD)機制。
VisionTasker 在大多數直觀任務中達到了與人類相當的完成率,在熟悉任務中略低於人類但在不熟悉任務中優於人類。
 △
△VisionTasker逐步完成任務的展示
結論
作為一個基於視覺和大模型的移動任務自動化框架,VisionTasker克服了現階段移動任務自動化對視圖層級結構的依賴。
通過一系列對比實驗,證明其在用戶界面表現上超越了傳統的編程演示和視圖層級結構方法。
它在4個不同的數據集上都展示了高效的UI表示能力,表現出更廣泛的應用性;並在Android手機上的147個真實世界任務中,特別是在複雜任務的處理上,表現了出超越人類的任務完成能力。
此外,通過集成編程演示(PBD)機制,VisionTasker在任務自動化方面有顯著的性能提升。
目前,該工作已以正式論文的形式發表於2024年10月13-16日在美國匹茲堡舉行的人機交互頂級會議UIST(The ACM Symposium on User Interface Software and Technology)。
UIST是人機交互領域專注於人機界面軟件和技術創新的CCF A類頂級學術會議。

原文鏈接:https://dl.acm.org/doi/10.1145/3654777.3676386
項目鏈接:https://github.com/AkimotoAyako/VisionTasker













