多圖場景用DPO對齊!上海AI實驗室等提出新方法,無需人工標註
劉子煜 投稿
量子位 | 公眾號 QbitAI
多圖像場景也能用DPO方法來對齊了!
由上海交大、上海AI實驗室、港中文等帶來最新成果MIA-DPO。
這是一個面向大型視覺語言模型的多圖像增強的偏好對齊方法。
通過將單圖像數據擴展至多圖像數據,並設計序列、網格拚貼和圖中圖三種數據格式,MIA-DPO大幅降低了數據收集和標註成本,且具有高度可擴展性。

要知道,理解多圖像上下文已經成為視覺語言大模型的發展趨勢之一,許多數據集和評估基準被提出。不過幻覺問題依然很難避免,且引入多圖像數據可能削弱單圖像任務的表現。
雖然偏好對齊方法(如DPO)在單圖像場景中已被證明有效,但多圖像偏好對齊仍然是一個解決問題。
MIA-DPO不僅解決了這一問題,而且無需依賴人工標註或昂貴的API。
通過分析視覺大語言模型在多圖像處理中的注意力分佈差異,他們提出了一種基於注意力的選擇方法(Attention Aware Selection),自動過濾掉關注無關圖像的錯誤答案,構建了自動化、低成本且適用於多圖像場景的DPO數據生成方法。
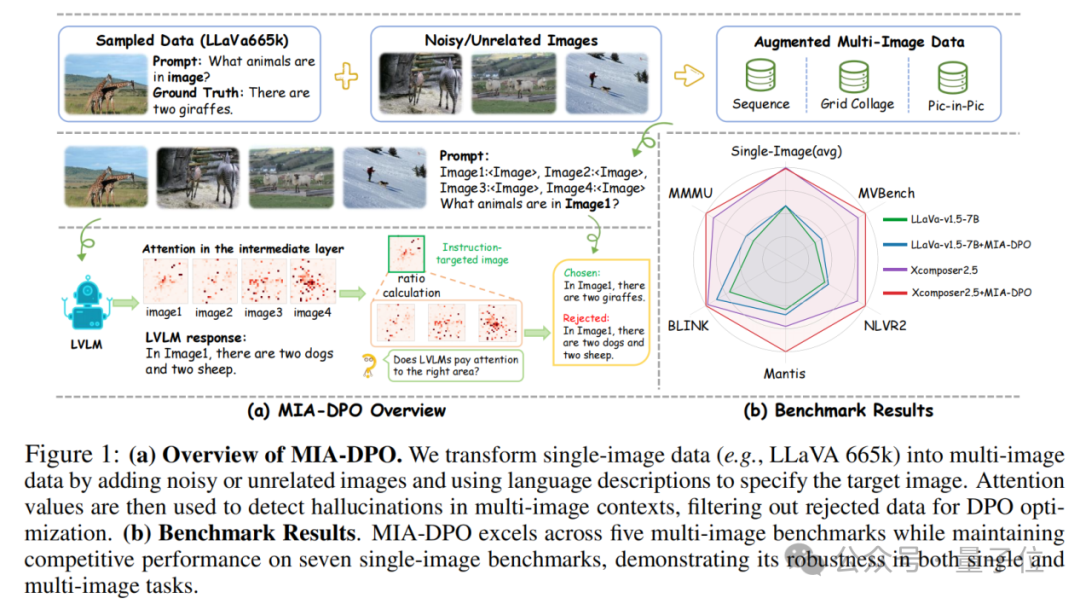 △MIA-DPO的整體介紹與實驗結果。
△MIA-DPO的整體介紹與實驗結果。值得一提的是,該論文還獲得了當日HuggingFace Daily Paper #1.
多圖推理容易有幻覺
為從根本上研究LVLM的多圖推理問題,研究者首先深入探索了多圖情境下LVLM的幻覺問題。一些早期研究探討了不同類型的單圖像幻覺現象,例如物體幻覺,指的是模型錯誤描述圖像中不存在的物體。與單圖像幻覺相比,多圖像場景引入了更加複雜的幻覺類型。如圖2所示,研究者將多圖像幻覺分為兩類:
(1) Sequence Confusion
當模型面對多張圖片時,可能無法準確識別輸入提示所指向的圖像。例如,在圖2的上方案例中,問題是針對圖像1(人與大海),但模型的回答卻基於圖像4(鐵軌上的火車)。
(2) Element Interference
相比單圖像,多圖像場景中的視覺元素數量顯著增加,導致LVLMs在不同元素之間產生混淆。例如,在圖2的下方案例中,問題「圖像2中的汽車是什麼顏色?」本應回答為「白色」。然而,LVLM錯誤地將圖像3中電單車的顏色屬性理解為圖像2中汽車的顏色,導致了錯誤的回答。
 △多圖幻覺
△多圖幻覺用注意力機制檢測幻覺
為構建能夠提升多圖感知與推理能力並緩解幻覺的視覺文本對齊方法,研究者們提出了注意力機制作為檢測幻覺的指標。
注意力機制揭示了模型在做出決策時「關注」的位置。研究者們觀察到,注意力機制為檢測多圖像幻覺提供了重要線索。
理想情況下,注意力值應集中在與問題相關的輸入圖像的特定區域上。如果注意力值分散或未強烈聚焦於正確的視覺元素或區域,表明模型在理解多圖像序列或區分不同圖像的元素時存在困難。
基於這一觀察,研究者們設計了一種基於注意力感知的選擇機制,利用注意力值在DPO算法中選擇包含幻覺的被拒絕樣本。MIA-DPO的框架如下圖3所示。
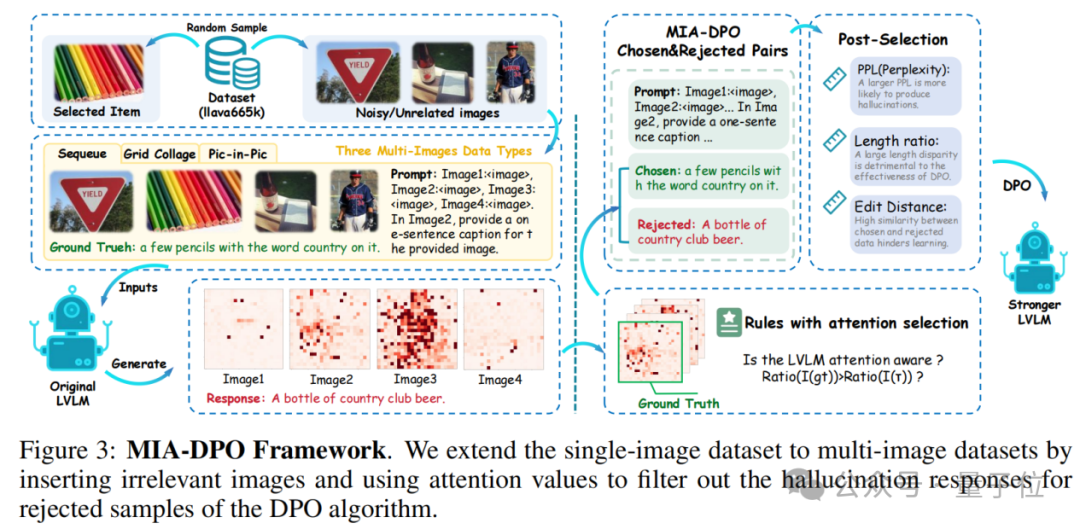 △MIA-DPO的整體架構
△MIA-DPO的整體架構儘管基於注意力感知的選擇機制在構建DPO數據時效果顯著,但仍可能會包含少量噪聲樣本,進而對模型產生不利影響。為此,研究者們引入後選擇步驟,通過以下三個指標來過濾噪聲樣本:(1) 困惑度(Perplexity, PPL);(2) 長度比率(Length Ratio);(3) 編輯距離(Edit Distance)。
在構造DPO數據的過程中,研究者通過引入無關圖像高效地轉換現有的單圖像數據集(例如LLaVA-665k)。
該方法低成本、可擴展,數據形式豐富的優勢,使MIA-DPO能夠較為全面地緩解LVLMs可能產生的各種多圖像幻覺類型。
如下圖所示,研究者構建了三種格式的多圖像DPO數據:
(1) 序列數據:多張圖像按順序排列,問題針對特定圖像。圖像數量從2到5張不等;
(2) 網格拚貼數據:多張圖像合併為一張圖,每張圖像都有編號說明。問題根據語言描述定位到特定圖像。圖像數量從2到9張不等;
(3) 圖中圖數據:一張圖像被縮放併疊加在另一張圖像上,問題圍繞組合後的圖像展開。
 △MIA-DPO的三種數據類型
△MIA-DPO的三種數據類型研究者在多個多圖和單圖benchamrks上對MIA-DPO進行了測試。
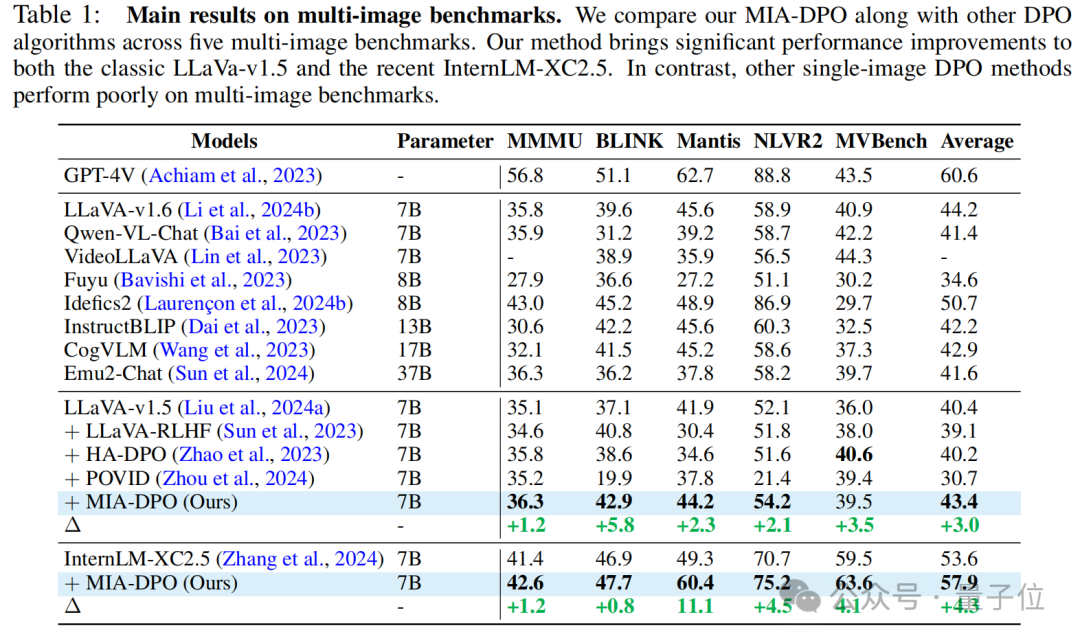
實驗結果顯示,在經典的LLaVa1.5模型和更為強大的InternLM-Xcomposer2.5上,MIA-DPO都能顯著提升模型的多圖感知與推理能力,如圖所示,LLaVa1.5和InternLM-Xcomposer2.5在五個多圖benchmarks上分別取得了平均3%和4.3%的性能提升。
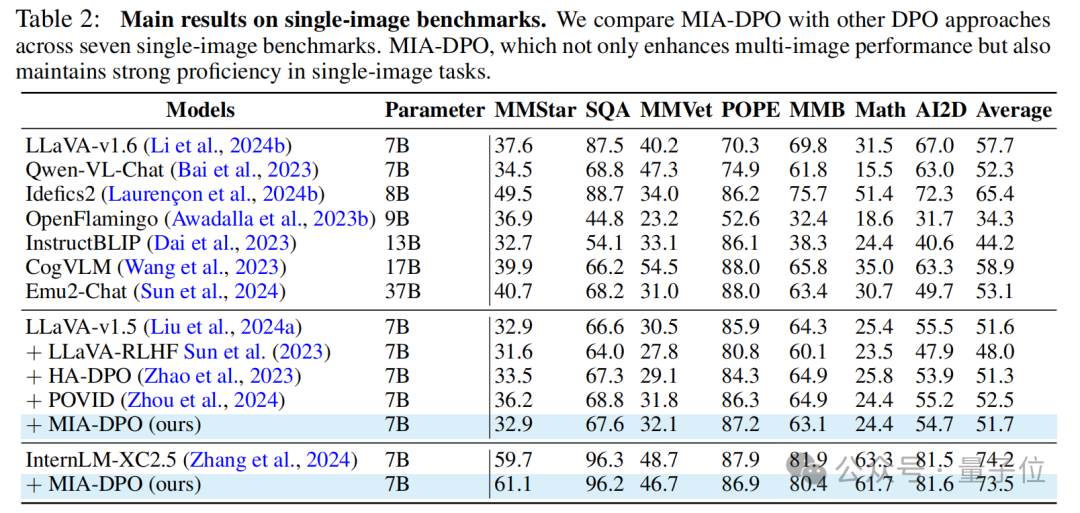
除此之外,研究著在多個單圖benchmarks上也進行了豐富的實驗,結果顯示MIA-DPO在提升模型多圖感知與推理能力的同時,也能保持住模型原有的單圖理解能力。
最後小結一下。
MIA-DPO不僅為多圖像場景中對齊模型與人類偏好提出了全新解決方案,還通過引入低成本、可擴展的數據生成方法,推動了LVLMs在處理複雜多圖像任務中的應用。MIA-DPO的成功證明了通過偏好優化對齊模型與人類反饋,在提升模型多圖像感知與推理能力的同時,也可以保持原有的單圖任務性能,為未來的研究奠定了堅實基礎。
論文地址:
https://arxiv.org/abs/2410.17637
Project Page:
https://liuziyu77.github.io/MIA-DPO/
Code:
https://github.com/Liuziyu77/MIA-DPO