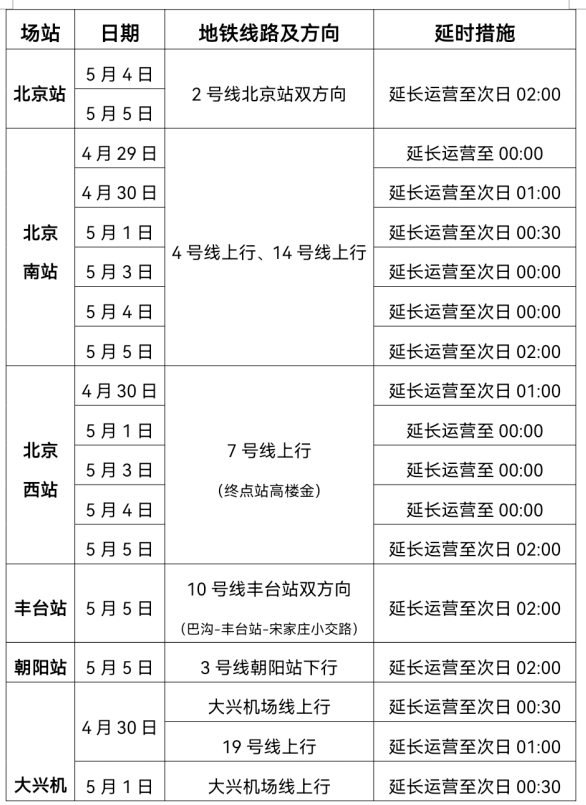
可靈AI進入2.0時代 快手帶來「多模態視覺語言」
新京報貝殼財經訊(記者羅亦丹)「相信我,這是你能用到的最強大的視覺生成模型。」4月15日,快手高級副總裁、社區科學線負責人蓋坤在可靈2.0模型發佈會上說。
這是在可靈1.0發佈10個月後,快手方面對可靈全系模型的一次重要升級,包括文生圖影片「可圖大模型2.0」,以及影片生成大模型「可靈大模型2.0」。蓋坤介紹,可靈2.0模型在動態質量、語義響應、畫面美學等維度,保持全球領先;可圖2.0模型在指令遵循、電影質感及藝術風格表現等方面顯著提升。
貝殼財經記者注意到,可靈2.0還上線了一種可以將文字、圖片、短影片甚至MMW等不同格式文件結合起來一起編輯的新交互模式「MVL(Multi-modal Visual Language直譯為多模態視覺語言)」。
據瞭解,當前影片生成主要分文生影片和圖生影片兩種,快手副總裁、可靈AI負責人張迪就披露,85%的影片創作通過圖生影片完成。有AI創作者告訴記者,當前業界主流的影片製作方式是首先通過文字生成圖片,再通過圖片生成影片。
而在蓋坤的演示中,通過MVL方式,用戶能夠結合圖像參考、影片片段等多模態信息,將腦海中的多維度複雜創意傳達給AI,而不僅僅是文字的提示語句。如下圖所示,用戶使用AI生成影片時,在提示詞中也可以夾帶圖片或影片。
 快手高級副總裁、社區科學線負責人蓋坤演示多模態交互方式。新京報貝殼財經記者羅亦丹/攝
快手高級副總裁、社區科學線負責人蓋坤演示多模態交互方式。新京報貝殼財經記者羅亦丹/攝「我們的理念是致力於研發很強大的基礎模型,同時致力於定義一個人和AI更完備的溝通方式,而這背後,我們的願景是讓每個人都能用AI講出好故事,希望這個願望早日成真。」蓋坤說。
編輯 陳莉 校對 柳寶慶