ChatGPT文生圖功能迎重大升級:準確生成文字 商用邊界大幅拓展
來源:財聯社
財聯社3月26日(編輯 史正丞)ChatGPT上線多年後愈發雞肋的圖像生成功能,終於迎來了歷史性的升級。
OpenAI首席執行官奧爾特曼在週二的直播活動中表示,正式推出基於GPT-4o模型的原生圖像生成功能——模型直接從文本提示生成圖像,不再調用獨立的DALL-E文生圖模型。

利用GPT-4o的多模態能力,ChatGPT在圖像生成時能更加精確地遵循指示、更精確地渲染圖像上的文字,同時支持多輪迭代優化圖像時保持角色形像一致。
ChatGPT於2022年底上線,最初只能進行文字聊天。大約一年後,OpenAI發佈第三代圖像生成模型DALL-E 3,並集成到ChatGPT,但兩者一直是互相獨立的系統。在最初的新鮮感過去後,AI圖像生成器「理解提示詞能力差」,特別是「無法準確生成圖片中的文字」嚴重阻礙這項功能在教育、職場等領域的應用。
隨著今年阿里巴巴、Google先後推出能準確生成文字的文生圖模型,OpenAI終於補上這個短板。
在週二的演示中,OpenAI展示了新一代ChatGPT 的圖像功能升級到了何種程度。
首先,ChatGPT已經能夠大致準確地按照提示詞,生成圖像中的文本。在演示中,AI成功按照要求生成一整頁的講話文本,同時沒有出現錯別字。奧爾特曼感慨稱,能在圖像生成功能中完美呈現文字本不應該是那麼令人讚歎的事情,但我們卻等了這麼久。
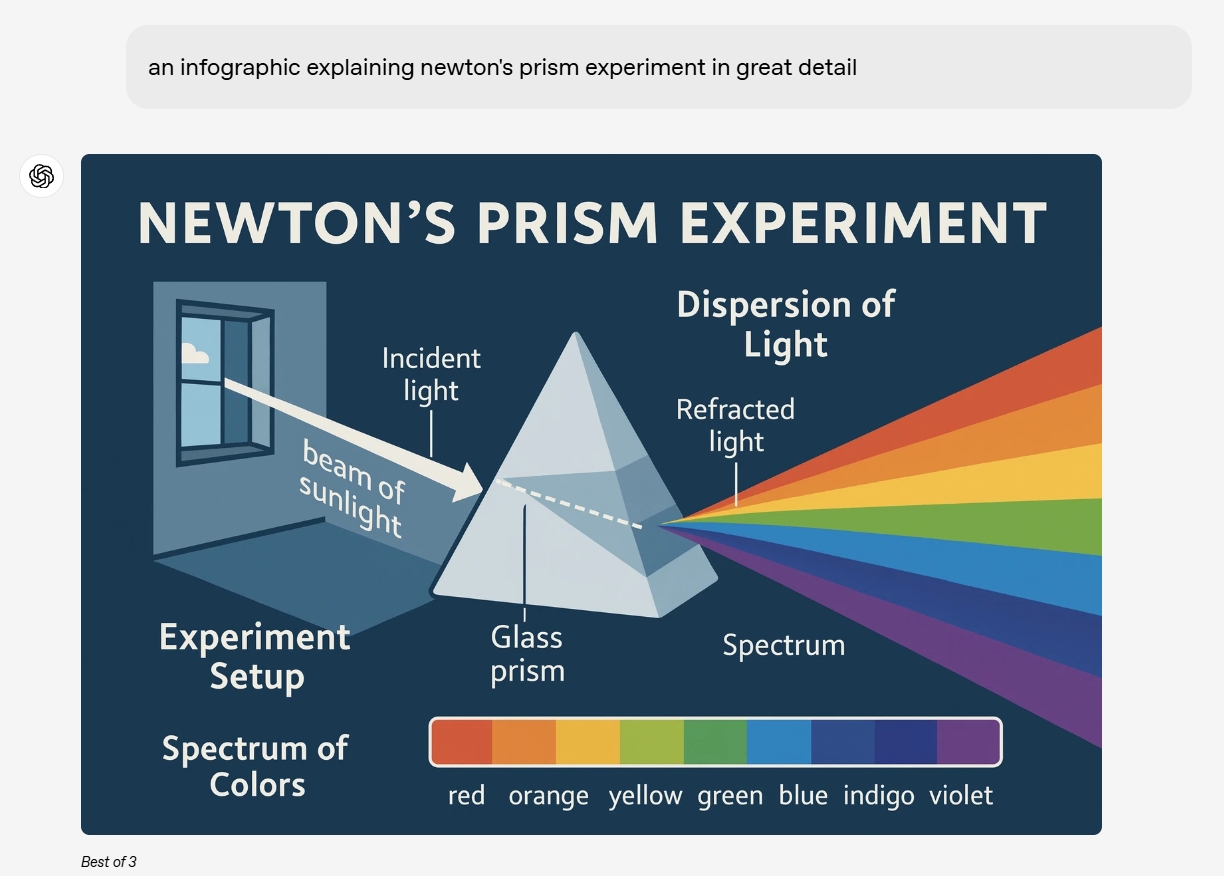
從官方給出的更多示例來看,不管是生成黑板板書,還是印刷體、展示科學常識的繪圖,ChatGPT在生成圖像文字領域終於從完全不能用,達到接近商用的程度。


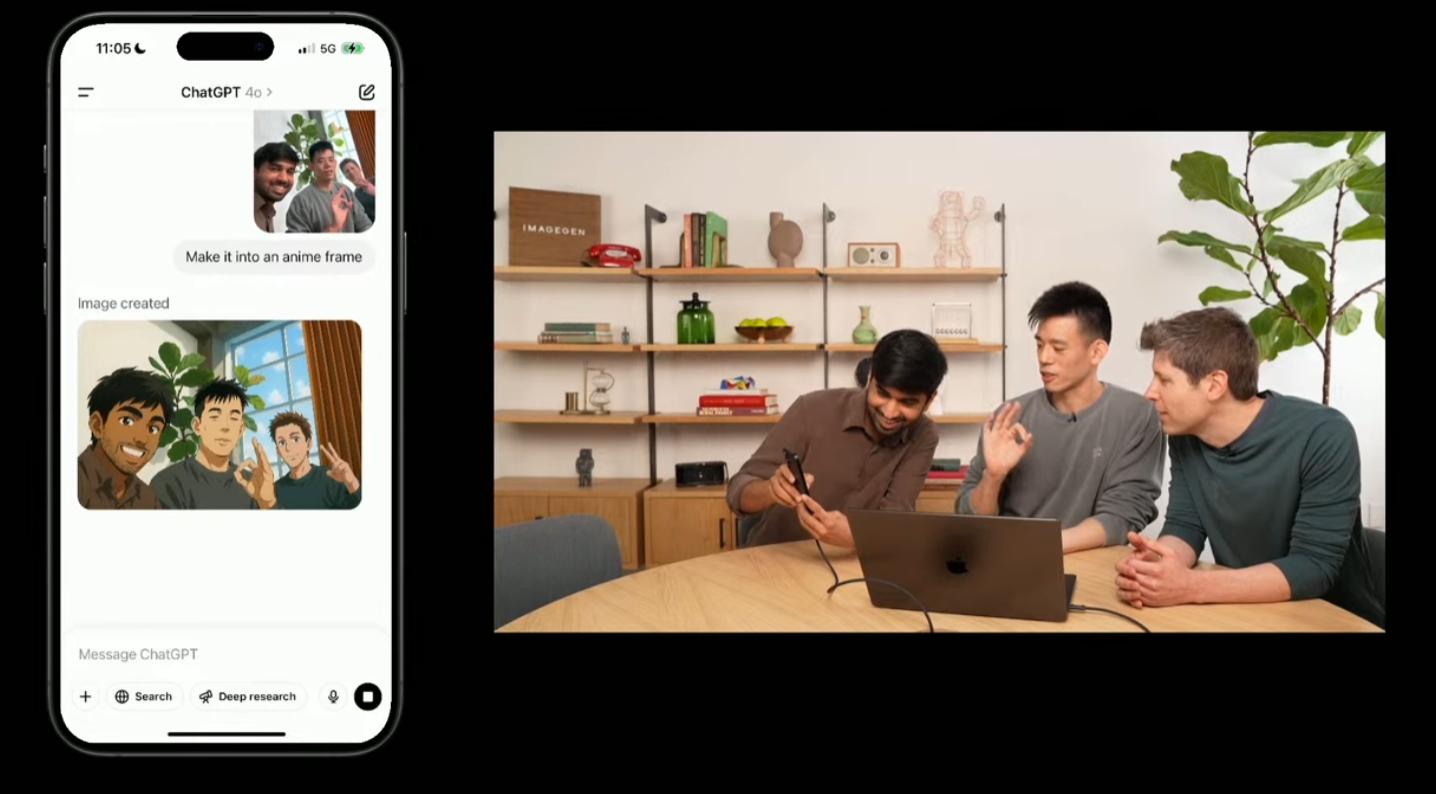
同時,ChatGPT的圖像編輯功能,也變得更加有用。
在演示中,兩名研究人員與奧爾特曼合照,然後要求ChatGPT將合照轉化為動畫畫風。
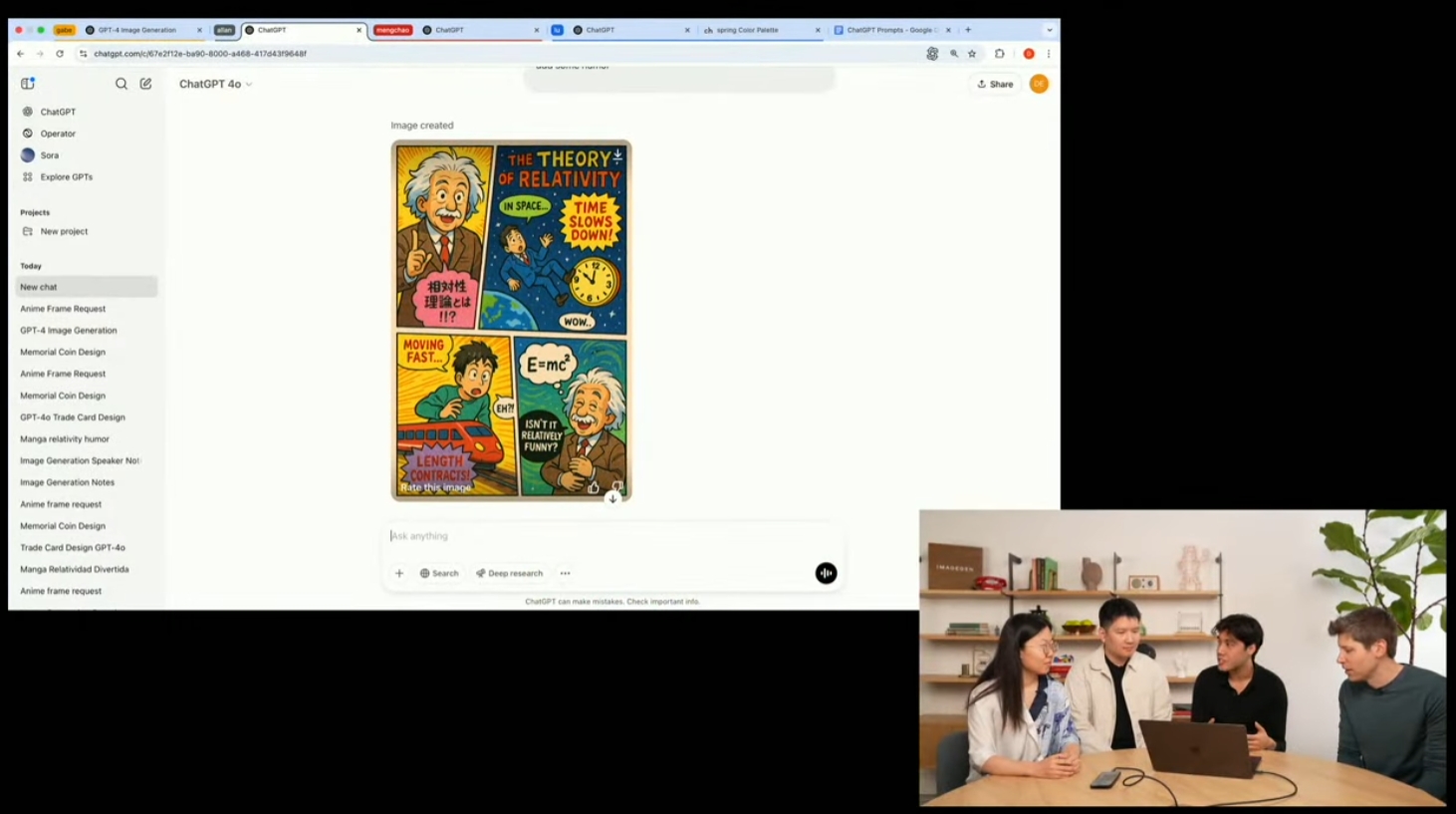
結合GPT-4o的知識庫和終於能把字寫清楚的能力,ChatGPT也能通過簡單的提示詞,生成有關相對論的漫畫彩圖。
說到漫畫,現在ChatGPT也能根據漫畫草稿,一鍵生成上完色的成品。同時也支持上傳圖片更換漫畫里的主要角色。



從商業應用方面來講,現在模型也能根據用戶上傳的照片和卡片模板,自定義組合生成新的卡片,並按照要求展示圖片和文字。


GPT‑4o也可以根據聊天上下文的基礎來生成圖片和文字,所以生成的一系列圖像將具有一致性,這對於設計遊戲角色而言相當重要。

OpenAI承認,新的圖像生成器也存在一些局限性,例如也會受到模型幻覺影響,同時在密集文字和非拉丁語文字的圖像生成方面,也更容易出現問題。
從週二開始,基於GPT‑4o的圖像生成功能向所有免費和付費用戶推出,未來幾週內開發者將能通過API調用這項功能。