LeCun新作:神經網絡在實踐中的靈活性到底有多大?

新智元報導
編輯:alan
【新智元導讀】神經網絡擬合數據的能力受哪些因素影響?CNN一定比Transformer差嗎?ReLU和SGD還有哪些神奇的作用?近日,LeCun參與的一項工作向我們展示了神經網絡在實踐中的靈活性。
人工智能在今天百花齊放,大模型靠規模稱王,小模型則憑數據取勝。
當然我們也希望,可以付出更少的資源,並達到相同的效果。
很早之前,Google就有相關研究,探索了在固定算力的情況下,如何分配模型參數量和訓練數據量,以達到最好的性能。
近日,LeCun參與的一項工作從另一個角度向我們展示了,神經網絡在實踐中的靈活性到底有多大?
 論文地址:https://arxiv.org/pdf/2406.11463
論文地址:https://arxiv.org/pdf/2406.11463這個靈活性指的是,神經網絡擬合訓練數據(樣本數量)的能力,在實際應用中受到哪些因素的影響。
比如我們第一時間想到的可能就是模型的參數量。
人們普遍認為,神經網絡可以擬合至少與自身參數一樣多的訓練樣本。
這就像是解一個線性方程組,有多少個參數(或者方程)、多少個未知數,從而判斷解的數量。
然而神經網絡實際上要複雜的多,儘管在理論上能夠進行通用函數逼近,但在實踐中,我們訓練的模型容量有限,不同優化器也會導致不同的效果。
所以,本文決定用實驗的方法,分別考察數據本身的性質、模型架構、大小、優化器和正則化器等因素。
而模型擬合數據的能力(或者說學習信息的能力),由有效模型複雜性(EMC)來表示。
這個EMC是怎麼算的呢?
一開始,在少量樣本上訓練模型。如果它在訓練後達到100%的訓練準確率,則將模型重新初始化並增大訓練樣本數量。
迭代執行此過程,每次逐步增加樣本量,直到模型不再完全擬合所有訓練樣本,將模型能實現完美擬合的最大樣本量作為網絡的EMC。
——一直喂飯,直到吃撐,則得到飯量大小。
實證分析
為了全面剖析影響神經網絡靈活性的因素,研究人員考慮了各種數據集、架構和優化器。
數據集
實驗採用了包括MNIST、CIFAR-10、CIFAR-100和ImageNet等視覺數據集,以及Forest-Cover Type、Adult Income和Credit等表格數據集。
另外,實驗還使用了更大規模的合成數據集,通過Min-SNR加權策略進行的高效擴散訓練,生成解像度為128×128的高質量圖像數據集——ImageNet-20MS,包含10個類別的2000萬個樣本。
模型
實驗評估了多層感知器(MLP)、CNN架構的ResNet和EfficientNet,以及Transformer架構的ViT。

作者係統地調整了這些架構的寬度和深度:
比如對於MLP,通過每層添加神經元來增加寬度,同時保持層數不變,或者通過添加更多層來增加深度,同時保持每層神經元數量不變。
對於一般的CNN(多個卷積層,接一個恒定大小的全連接層),可以改變每層的kernel數量或者卷積層的總數。
對於ResNet,可以改變kernel的數量或者block的數量(深度)。
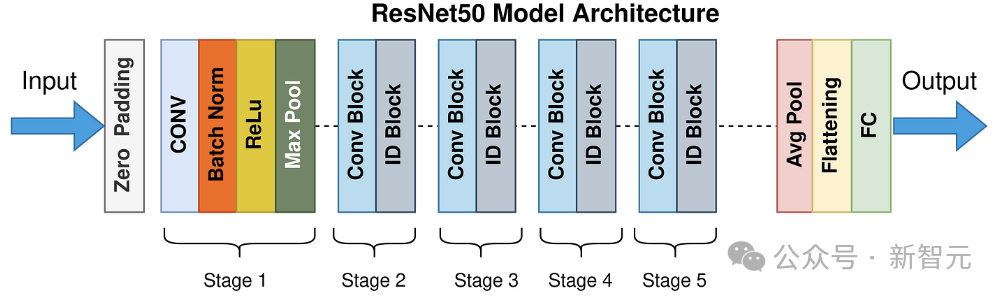
而對於ViT,可以改變編碼器的數量(深度)、patch embedding的維度和自注意力(寬度)。

優化器
實驗採用的優化器包括隨機梯度下降(SGD)、Adam、AdamW、全批次梯度下降(full-batch Gradient Descent)和second-order Shampoo optimizer。
由此,研究人員可以測試隨機性和預處理等特徵如何影響最小值。同時。為了確保跨數據集和模型大小進行有效優化,研究人員仔細調整了每個設置的學習率和批量大小,並省略了權重衰減。
數據對EMC的影響
研究人員通過修改隱藏層的寬度來擴展一個2層的MLP,通過修改層數和通道數來擴展CNN,並在一系列圖像(MNIST、CIFAR-10、CIFAR-100、ImageNet)和表格(CoverType、Income 和 Credit)數據集上訓練模型。
結果顯示,在不同數據類型上訓練的網絡在EMC方面存在顯著差異:

在表格數據集上訓練的網絡表現出更高的容量;而在圖像分類數據集中,測試精度和容量之間存在很強的相關性。
值得注意的是,MNIST(模型達到99%以上的測試準確度)產生的EMC最高,而ImageNet的EMC最低,這表明了泛化與數據擬合能力之間的關係。
輸入和標籤的作用
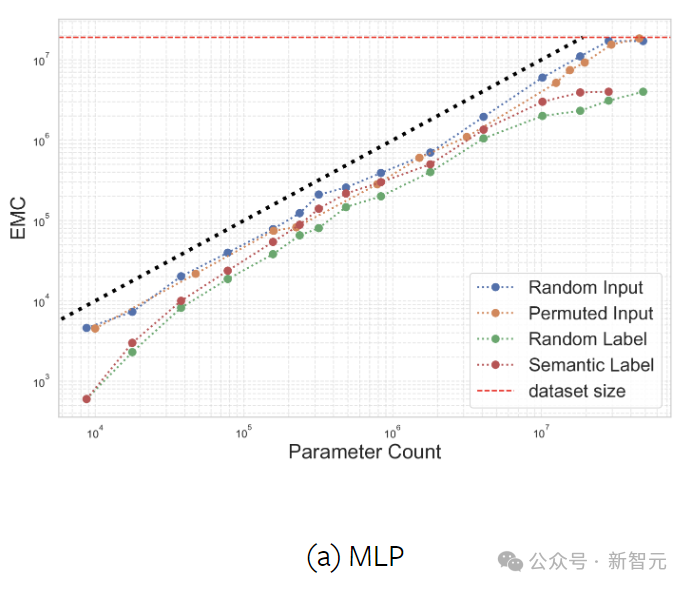
這裡通過改變每層中的神經元或kernel的數量,來調整MLP和CNN的寬度,並在合成數據集ImageNet-20MS上進行訓練。
實驗測試了四種情況下的EMC:語義標籤、隨機標籤、隨機輸入(高斯噪聲)和固定隨機排列下的輸入。
分配隨機標籤(而非真實標籤)的目的是探索過參數化(overparameterization)和欠參數化(underparameterization)之間的邊界。

從上圖的結果可以發現,與原始標籤相比,當分配隨機標籤時,網絡擬合的樣本要少得多,此時神經網絡的參數效率低於線性模型。而從整體上來看,模型的參數量與擬合的數據量大致呈線性關係。
分類數量對EMC的影響
作者隨機合併了CIFAR-100中的類別(保留原始數據集的大小),在具有不同數量kernel的2層CNN上進行實驗。

結果如上圖所示,隨著類數量的增加,帶有語義標籤的數據變得越來越難以擬合,因為模型必須對其權重中的每個樣本進行編碼。
相比之下,隨機標記的數據變得更容易擬合,因為模型不再被迫為語義上不同的樣本分配相同的類標籤。
預測泛化
神經網絡偏向於擬合語義連貫的標籤而不是隨機標籤,而且,與隨機標籤相比,網絡擬合語義標籤的熟練程度通常與其泛化能力相關。
這種泛化也使得CNN這種架構能夠擬合比模型參數量更多的樣本。
傳統的機器學習觀念認為,高容量模型往往會過度擬合,從而影響其對新數據的泛化,而PAC-貝葉斯理論則指出,模型更喜歡正確的數據標記。
而本文的實驗將這兩種理論聯繫在了一起。

上圖中,在正確標記和隨機標記的數據上計算各種CNN和MLP的EMC,測量模型遇到語義標籤與隨機標籤時EMC增加的百分比。
結果表明EMC增加的百分比與generalization gap之間存在顯著的負相關關係,這不僅證實了泛化的理論基礎,而且闡明了理論的實際意義。
模型架構對EMC的影響
關於CNN和ViT的效率和泛化能力一直存在爭議。
實驗表明,CNN以硬編碼的歸納偏差為特徵,在EMC中優於ViT和MLP。當對語義標記的數據進行評估時,這種優勢在所有模型大小中都持續存在。

CNN從具有空間結構的數據中獲益匪淺,當空間結構通過排列被打破時,擬合的樣本就會減少。而MLP缺乏這種對空間結構的偏好,因此它們擬合數據的能力是不變的。
另外,用高斯噪聲代替輸入可提高兩種架構的容量,這可以解釋為,在高維中,嘈雜的數據相距甚遠,因此更容易分離。

值得注意的是,與隨機輸入相比,CNN可以擬合具有語義標籤的樣本數量要多得多,MLP卻正好相反,這再次凸顯了CNN在圖像分類方面的卓越泛化能力。
擴展網絡規模
下圖展示了各種擴展配置下的EMC。

對於ResNet,擴展措施包括增加寬度(kernel數量)、增加深度。EfficientNet固定係數,同時縮放深度、寬度和解像度。ResNet-RS根據模型大小、訓練持續時間和數據集大小調整縮放。
對於ViT,使用SViT和SoViT方法,並嘗試分別改變編碼器塊的數量(深度)和patch embedding的維度和自注意力(寬度)。
分析表明,縮放深度比縮放寬度更具參數效率。這個結論同時也適用於隨機標記的數據,表明並不是泛化的產物。
激活函數
非線性激活函數對於神經網絡容量至關重要,沒有它們,神經網絡只是大型因式分解線性模型。
研究結果表明,ReLU顯著增強了模型的容量。雖然它最初的作用是為了減輕梯度的消失和爆炸,但ReLU還提高了網絡的數據擬合能力。

相比之下,tanh雖然也是非線性的,但不能實現類似的效果。
優化在擬合數據中的作用
優化技術和正則化策略的選擇在神經網絡訓練中至關重要。這種選擇不僅影響訓練收斂性,還影響所找到的解決方案的性質。
參與實驗的優化器包括SGD、全批次梯度下降、Adam、AdamW和Shampoo。

以前的研究認為SGD具有很強的平坦度尋求正則化效應,但上圖表明,SGD還能夠比全批次(非隨機)梯度下降訓練擬合更多的數據。
不同優化器的EMC測量值表明,優化器不僅在收斂速率上有所不同,而且在發現的最小值類型上也有所不同。
參考資料:
https://x.com/micahgoldblum/status/1803088886513496392


















