英偉達Mistral AI聯袂出擊,120億小模型王者強勢登場,碾壓Llama 3單張4090可跑
GPT-4o mini頭把交椅還未坐熱,Mistral AI聯手英偉達發佈12B參數小模型Mistral Nemo,性能趕超Gemma 2 9B和Llama 3 8B。
小模型,成為本週的AI爆點。
先是HuggingFace推出了小模型SmoLLM;OpenAI直接殺入小模型戰場,發佈了GPT-4o mini。
GPT-4o mini發佈同天,歐洲最強AI初創公司Mistral立馬發佈旗下最新最強小模型——Mistral NeMo。

Mistral NeMo由Mistral AI和英偉達聯手打造,有12B參數,支持128K上下文。

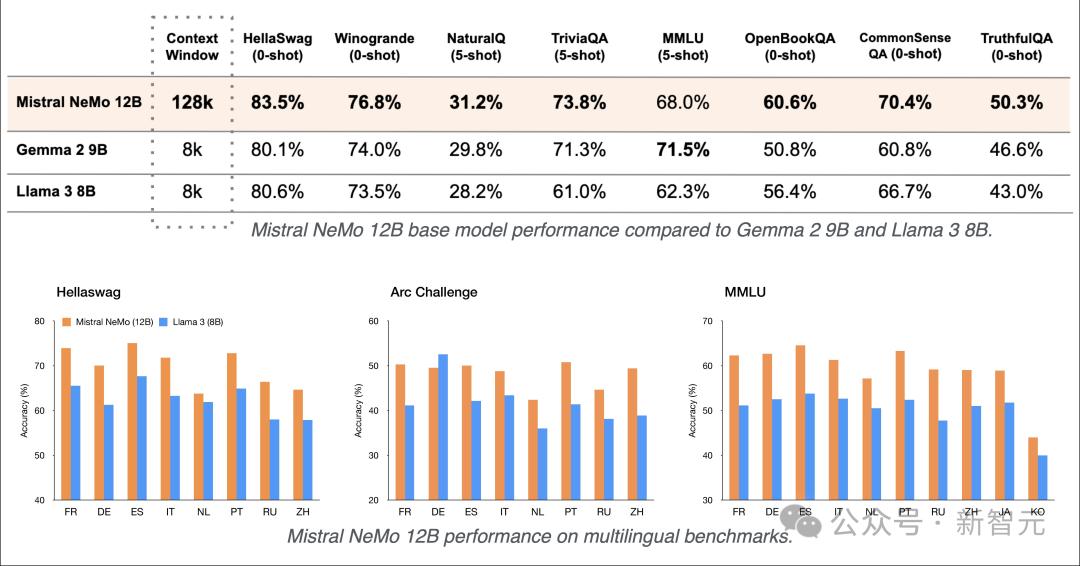
從整體性能上來看,Mistral NeMo在多項基準測試中,擊敗了Gemma 2 9B和Llama 3 8B。
看到各大巨頭和獨角獸都和小模型杠上了,吃瓜群眾紛紛鼓掌。
HuggingFace創始人表示,本週巨頭小模型三連發,「小模型周」來了!卷!繼續卷!

Mistral這周的確像打了雞血,火力全開。
幾天前,Mistral才發佈了兩款小模型,專為數學推理和科學發現設計的Mathstral 7B和代碼模型Codestral Mamba,是首批採用Mamba 2架構的開源模型之一。
沒想到周這隻是平A了兩下熱熱場子,還和老黃憋著大招等待閃亮登場。
1+1>2?
最新發佈的小模型Mistral NeMo 12B,瞄準企業用戶的使用。
開發人員可以輕鬆定製和部署支持聊天機器人、多語言任務、編碼和摘要的企業應用程序。
通過將Mistral AI在訓練數據方面的專業知識,與英偉達優化的硬件和軟件生態系統相結合,「最強爹媽」培養出的娃,Mistral NeMo模型性能極其優秀。
Mistral AI聯合創始人兼首席科學家Guillaume Lample表示,「我們很幸運能夠與英偉達團隊合作,利用他們的頂級硬件和軟件。」

Mistral NeMo在NVIDIA DGX Cloud AI平台完成了訓練,該平台提供對最新英偉達架構的專用和可擴展訪問。
加速大語言模型推理性能的NVIDIA TensorRT-LLM,以及構建自定義生成AI模型的NVIDIA NeMo開發平台也用於推進和優化新模型的性能。
此次合作也凸顯了英偉達對支持模型構建器生態系統的承諾。
企業賽道,卓越性能
Mistral NeMo支持128K上下文,能夠更加連貫、準確地處理廣泛且複雜的信息,確保輸出與上下文相關。
與同等參數規模模型相比,它的推理、世界知識和編碼準確性都處於領先地位。
下表結果所示,除了在MMLU基準上,Mistral NeMo不如Gemma 2 9B。
但在多輪對話、數學、常識推理、世界知識和編碼等基準中,超越了Gemma 2 9B和Llama 3 8B。


由於Mistral NeMo使用標準架構,因此兼容性強,易於使用,並且可以直接替代任何使用Mistral 7B的系統。
Mistral NeMo是一個擁有120億參數的模型,根據Apache 2.0許可證發佈,任何人皆可下載使用。

此外,模型使用FP8數據格式進行模型推理,這可以減少內存大小並加快部署速度,而不會降低準確性。
這意味著,模型可以流暢絲滑地學習任務,並更有效地處理不同的場景,使其成為企業的理想選擇。
這種格式可以在任何地方輕鬆部署,各種應用程序都能靈活使用。
因此,模型可以在幾分鐘內,部署到任何地方,免去等待和設備限制的煩惱。
Mistral NeMo瞄準企業用戶的使用,採用屬於NVIDIA AI Enterprise一部分的企業級軟件,具有專用功能分支、嚴格的驗證流程以及企業級安全性的支持。
開放模型許可證也允許企業將Mistral NeMo無縫集成到商業應用程序中。
Mistral NeMo NIM專為安裝在單個NVIDIA L40S、NVIDIA GeForce RTX 4090或NVIDIA RTX 4500 GPU的內存上而設計,高效率低成本,並且保障安全性和隱私性。
也就是說,單個英偉達L40S,一塊GPU就可跑了。

對於希望實現先進人工智能的企業來說,Mistral NeMo 12B提供了強大且實用的組合技。
先進模型的開發和定製
Mistral AI和英偉達各自擅長的領域結合,優化了Mistral NeMo的訓練和推理。
模型利用Mistral AI的專業知識進行訓練,尤其是在多語言、代碼和多輪內容方面,受益於英偉達全堆棧的加速訓練。
它專為實現最佳性能而設計,利用高效的模型並行技術、可擴展性以及與Megatron-LM的混合精度。
該模型使用NVIDIA NeMo的一部分Megatron-LM進行訓練,在DGX Cloud上配備3,072個H100 80GB Tensor Core GPU,由NVIDIA AI架構組成,包括加速計算、網絡結構和軟件,以提高訓練效率。
面向大眾的多語言模型
Mistral NeMo模型專為全球多語言應用程序而設計。
它經過函數調用訓練,具有較大的上下文窗口,並且在英語、法語、德語、西班牙語、意大利語、葡萄牙語、中文、日語、韓語、阿拉伯語和印地語多語言方面性能強大。
可以說,這是將前沿人工智能模型帶到全世界不同語言使用者手中的重要一步。
 Mistral NeMo在多語言基準測試中的表現
Mistral NeMo在多語言基準測試中的表現Tekken:更高效的分詞器
Mistral NeMo使用基於Tiktoken的全新分詞器——Tekken,該分詞器已針對100多種語言進行訓練,並且比以前的Mistral模型中使用的SentencePiece分詞器更有效地壓縮自然語言文本和源代碼。
具體而言,在壓縮源代碼、中文、意大利語、法語、德語、西班牙語和俄語方面的效率提高了約30%;
在壓縮韓語和阿拉伯語方面的效率也分別提高了2倍和3倍。與Llama 3分詞器相比,Tekken在壓縮大約85%的所有語言的文本方面表現更為出色。
 Tekken壓縮率
Tekken壓縮率指令微調
Mistral NeMo已經經過了高級微調和對齊階段。與Mistral 7B相比,它在遵循精確指令、推理、處理多輪對話和生成代碼方面表現得更好。
 Mistral NeMo指令微調模型精度,使用GPT-4o作為官方參考的評判標準進行評估
Mistral NeMo指令微調模型精度,使用GPT-4o作為官方參考的評判標準進行評估可用性和部署
憑藉在雲、數據中心或RTX工作站等任何地方運行的靈活性,Mistral NeMo已準備好成為徹底改變跨平台使用AI應用程序的先鋒。
用戶可以立即通過ai.nvidia.com作為NVIDIA NIM體驗Mistral NeMo,可下載的NIM版本即將推出。
有網民已經迫不及待在英偉達NIM推理微服務中運行了Mistral NeMo 12B。


開發者現在可以使用mistral-inference試用Mistral NeMo,並使用mistral-finetune對其進行微調。
Mistral NeMo在La Plateforme上以open-mistral-nemo-2407的名稱公開。
參考資料:
https://blogs.nvidia.com/blog/mistral-nvidia-ai-model/?ncid=so-twit-243298&linkId=100000274370636
https://x.com/arthurmensch/status/1813949845704745223
https://x.com/theo_gervet/status/1813951882815000628
https://x.com/ClementDelangue/status/1813962747056652515
本文來自微信公眾號「新智元」,作者:耳朵 桃子,36氪經授權發佈。



















