首個超越GPT4o級開源模型,Llama 3.1泄密:4050億參數,下載鏈接、模型卡都有了
快準備好你的 GPU!
Llama 3.1 終於現身了,不過出處卻不是 Meta 官方。
今日,Reddit 上新版 Llama 大模型泄露的消息遭到了瘋傳,除了基礎模型,還包括 8B、70B 和最大參數的 405B 的基準測試結果。

下圖為 Llama 3.1 各版本與 OpenAI GPT-4o、Llama 3 8B/70B 的比較結果。可以看到,即使是 70B 的版本,也在多項基準上超過了 GPT-4o。
 圖源:https://x.com/mattshumer_/status/1815444612414087294
圖源:https://x.com/mattshumer_/status/1815444612414087294顯然,3.1 版本的 8B 和 70B 模型是由 405B 蒸餾得來的,因此相比上一代有著明顯的性能提升。
有網民表示,這是首次開源模型超越了 GPT4o 和 Claude Sonnet 3.5 等閉源模型,在多個 benchmark 上達到 SOTA。

與此同時,Llama 3.1 的模型卡流出,細節也泄露了(從模型卡中標註的日期看出基於 7 月 23 日發佈)。
有人總結了以下幾個亮點:
模型使用了公開來源的 15T+ tokens 進行訓練,預訓練數據截止日期為 2023 年 12 月;
微調數據包括公開可用的指令微調數據集(與 Llama 3 不同)和 1500 萬個合成樣本;
模型支持多語言,包括英語、法語、德語、印地語、意大利語、葡萄牙語、西班牙語和泰語。
 圖源:https://x.com/iScienceLuvr/status/1815519917715730702
圖源:https://x.com/iScienceLuvr/status/1815519917715730702雖然泄露的 Github 鏈接目前 404 了,但有網民給出了下載鏈接(不過為了安全,建議還是等今晚的官方渠道公佈):
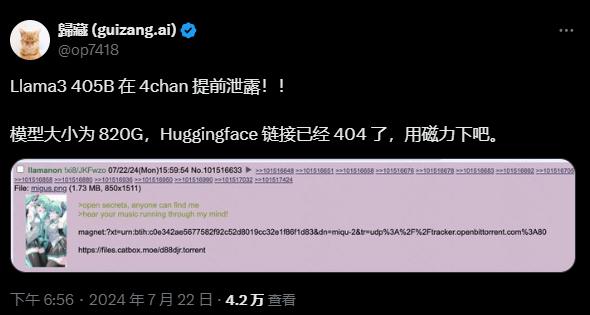
不過這畢竟是個千億級大模型,下載之前請準備好足夠的硬盤空間:

以下是 Llama 3.1 模型卡中的重要內容:
模型基本信息
Meta Llama 3.1 多語言大型語言模型 (LLM) 集合是一組經過預訓練和指令微調的生成模型,大小分別為 8B、70B 和 405B(文本輸入 / 文本輸出)。Llama 3.1 指令微調的純文本模型(8B、70B、405B)針對多語言對話用例進行了優化,在常見的行業基準上優於許多可用的開源和閉源聊天模型。
模型架構:Llama 3.1 是優化了的 Transformer 架構自回歸語言模型。微調後的版本使用 SFT 和 RLHF 來對齊可用性與安全偏好。
支持語言:英語、德語、法語、意大利語、葡萄牙語、印地語、西班牙語和泰語。
從模型卡信息可以推斷,Llama 3.1 系列模型的上下文長度為 128k。所有模型版本都使用分組查詢注意力(GQA)來提高推理可擴展性。



預期用途
預期用例。Llama 3.1 旨在用於多語言的商業應用及研究。指令調整的純文本模型適用於類助理聊天,而預訓練模型可以適應各種自然語言生成任務。
Llama 3.1 模型集還支持利用其模型輸出來改進其他模型(包括合成數據生成和蒸餾)的能力。Llama 3.1 社區許可協議允許這些用例。
Llama 3.1 在比 8 種受支持語言更廣泛的語言集合上進行訓練。開發人員可以針對 8 種受支持語言以外的語言對 Llama 3.1 模型進行微調,前提是遵守 Llama 3.1 社區許可協議和可接受使用策略, 並且在這種情況下負責確保以安全和負責任的方式使用其他語言的 Llama 3.1。
軟硬件基礎設施
首先是訓練要素,Llama 3.1 使用自定義訓練庫、Meta 定製的 GPU 集群和生產基礎設施進行預訓練,還在生產基礎設施上進行了微調、註釋和評估。
其次是訓練能耗,Llama 3.1 訓練在 H100-80GB(TDP 為 700W)類型硬件上累計使用了 39.3 M GPU 小時的計算。這裏訓練時間是訓練每個模型所需的總 GPU 時間,功耗是每個 GPU 設備的峰值功率容量,根據用電效率進行了調整。
訓練溫室氣體排放。Llama 3.1 訓練期間基於地域基準的溫室氣體總排放量預估為 11,390 噸二氧化碳當量。自 2020 年以來,Meta 在全球運營中一直保持淨零溫室氣體排放,並將其 100% 的電力使用與可再生能源相匹配,因此訓練期間基於市場基準的溫室氣體總排放量為 0 噸二氧化碳當量。
用於確定訓練能源使用和溫室氣體排放的方法可以在以下論文中找到。由於 Meta 公開發佈了這些模型,因此其他人不需要承擔訓練能源使用和溫室氣體排放。
論文地址:https://arxiv.org/pdf/2204.05149
訓練數據
概述:Llama 3.1 使用來自公開來源的約 15 萬億個 token 數據進行了預訓練。微調數據包括公開可用的指令數據集,以及超過 2500 萬個綜合生成的示例。
數據新鮮度:預訓練數據的截止日期為 2023 年 12 月。
Benchmark 評分
在這一部分,Meta 報告了 Llama 3.1 模型在標註 benchmark 上的評分結果。所有的評估,Meta 都是使用內部的評估庫。

安全風險考量
Llama 研究團隊致力於為研究界提供寶貴的資源來研究安全微調的穩健性,並為開發人員提供適用於各種應用的安全且強大的現成模型,以減少部署安全人工智能系統的開發人員的工作量。
研究團隊採用多方面數據收集方法,將供應商的人工生成數據與合成數據相結合,以減輕潛在的安全風險。研究團隊開發了許多基於大型語言模型 (LLM) 的分類器,以深思熟慮地選擇高質量的 prompt 和響應,從而增強數據質量控制。
值得一提的是,Llama 3.1 非常重視模型拒絕良性 prompt 以及拒絕語氣。研究團隊在安全數據策略中引入了邊界 prompt 和對抗性 prompt,並修改了安全數據響應以遵循語氣指南。
Llama 3.1 模型並非設計為單獨部署,而是應作為整個人工智能系統的一部分進行部署,並根據需要提供額外的「安全護欄」。開發人員在構建智能體系統時應部署系統安全措施。
請注意,該版本引入了新功能,包括更長的上下文窗口、多語言輸入和輸出,以及開發人員與第三方工具的可能集成。使用這些新功能進行構建時,除了需要考慮一般適用於所有生成式人工智能用例的最佳實踐外,還需要特別注意以下問題:
工具使用:與標準軟件開發一樣,開發人員負責將 LLM 與他們所選擇的工具和服務集成。他們應為自己的使用案例製定明確的政策,並評估所使用的第三方服務的完整性,以瞭解使用此功能時的安全和保安限制。
多語言:Lama 3.1 除英語外還支持 7 種語言:法語、德語、印地語、意大利語、葡萄牙語、西班牙語和泰語。Llama 可能可以輸出其他語言的文本,但這些文本可能不符合安全性和幫助性性能閾值。
Llama 3.1 的核心價值觀是開放、包容和樂於助人。它旨在服務於每個人,並適用於各種使用情況。因此,Llama 3.1 的設計宗旨是讓不同背景、經歷和觀點的人都能使用。Llama 3.1 以用戶及其需求為本,沒有插入不必要的評判或規範,同時也反映了這樣一種認識,即即使在某些情況下看似有問題的內容,在其他情況下也能達到有價值的目的。Llama 3.1 尊重所有用戶的尊嚴和自主權,尤其是尊重為創新和進步提供動力的自由思想和表達價值觀。
但 Llama 3.1 是一項新技術,與任何新技術一樣,其使用也存在風險。迄今為止進行的測試尚未涵蓋也不可能涵蓋所有情況。因此,與所有 LLM 一樣,Llama 3.1 的潛在輸出無法事先預測,在某些情況下,該模型可能會對用戶提示做出不準確、有偏差或其他令人反感的反應。因此,在部署 Llama 3.1 模型的任何應用之前,開發人員應針對模型的具體應用進行安全測試和微調。
模型卡來源:https://pastebin.com/9jGkYbXY
參考信息:https://x.com/op7418/status/1815340034717069728
https://x.com/iScienceLuvr/status/1815519917715730702
https://x.com/mattshumer_/status/1815444612414087294
本文來自微信公眾號「機器之心」,作者:機器之心,36氪經授權發佈。