Llama 3.1磁力鏈提前泄露,開源模型王座一夜易主,GPT-4o被超越
歷史再次重演,Llama 3.1 405B提前泄露了!
現在,基準測試和磁力鏈已經傳得滿天飛了。

除了最大的405B,Meta這次還升級了5月初發佈的8B和70B模型,並將上下文長度全部提升到了128K。
至此,模型版本也正式從Llama 3迭代到了Llama 3.1。

根據磁力鏈提供的信息,新模型大小為763.48GiB(約820GB)。

從泄露的「基準測試」可以看出,連8B小模型都很能打,而70B的模型,性能在多項基準上都能趕超GPT-4o了。

開發者們看到測試結果後也原地炸鍋,Topology CEO Aidan McLau驚呼道——
如果Llama 3-405B的基準測試是真的,它將
– 成為世界上最好的模型
– 每個人都可調
– 比GPT-4o還便宜!

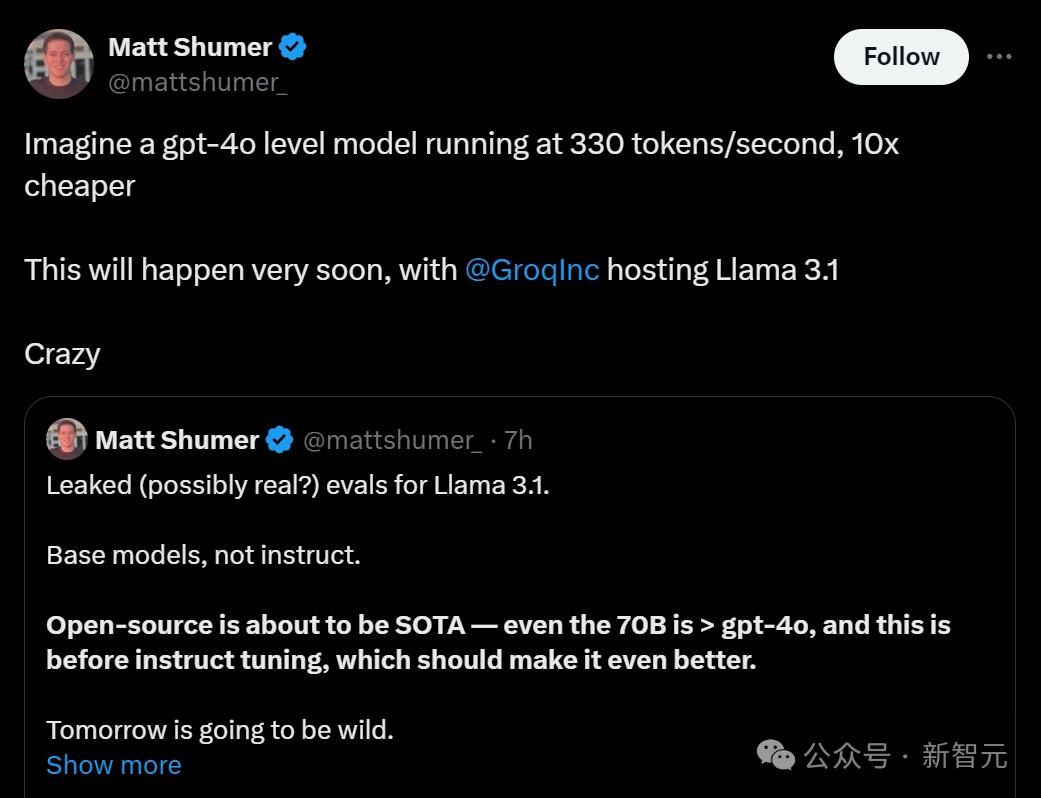
HyperWriteAI CEO Matt Schumer預言:它定將成為開源模型中的SOTA。(連70B都能和GPT-4o掰手腕,何況這還是在指令微調之前。)
想像一下,一個GPT-4o級別的模型,以每秒330個token的速度運行,價格還要便宜10倍。這簡直太令人興奮了。
明天,將是狂野的一天!
而小紮的一句話,更是暗示著405B的到來——重大一週前的寧靜時刻。

眾多網民在線逼問OpenAI:新模型什麼時候放出?
Llama 3.1家族,明日上線
根據泄露的模型卡,Llama 3.1將在23日發佈。

許可證為「定製商業許可」和「Llama 3.1社區許可」。
 泄露的Model Card:https://pastebin.com/9jGkYbXY
泄露的Model Card:https://pastebin.com/9jGkYbXY具體來說,多語言大模型 Llama 3.1系列是一組預訓練和指令微調的生成模型,包括8B、70B和405B三種參數規模。
指令微調後的Llama 3.1純文本模型(8B、70B、405B),針對多語言對話用例進行了優化。
除了英語,它還可以支持7種語言,包括德語、法語、意大利語、葡萄牙語、印地語、西班牙語和泰語。
據介紹,Llama 3.1的新增能力包括,更長的上下文、支持多語言輸入和輸出,以及開發者與第三方工具的集成。
基準測試
在GitHub上一張基準圖(現404)顯示,Llama 3.1在基準測試中的優異表現。
具體來說,在基準預訓練模型的基準評測中,Llama 3.1 405B在通用任務、知識推理、閱讀理解上創下最新紀錄。
尤其在,MMLU、SQuAD細分基準上,提升最為明顯。
與此同時,Llama 3.1 8B和70B參數版本,相較於Llama 3,得到了細微地改善。不過,有些指標,70B Llama 3.1還不如前一代。

另外,指令微調模型中,看得出Llama 3.1 405B比預訓練模型更強。在推理、代碼、數學、工具使用、多語言基準上,紛紛碾壓微調後的8B和70B版本。
Llama 3.1 8B和70B微調模型,同樣在多項能力任務中,性能大幅提升。

還有網民彙總了其他領先模型的基準,通過對比可以看出,Claude 3.5 Sonnet才是所有基準中的王者。
Llama 3.1 405B微調版本僅在數學基準MMLU Pro上,最能打,以73.3%成績打敗所有大模型。
另外,405B在GPQA(研究生水平的專業知識和推理)、數學、DROP(閱讀理解)、MGSM(多語言數學)、HumanEval(編程),BBH(知識評估)基準上,與GPT-4o不相上下。
而且,405B大幅領先最新GPT-4o mini模型。

Llama 3.1是一個自回歸語言模型,使用優化的Transformer架構。調整後的版本使用了SFT和RLHF,以符合人類對安全的偏好。
對於Llama 3.1系列模型,token計數僅指預訓練數據。
所有模型的版本,都使用分組查詢注意力(GQA)來提高推理的可擴展性。
15T token訓練數據
與Llama 3一樣,Llama 3.1也是在大約15萬億個來自公開可用來源的token上進行了預訓練。
微調數據包括公開可用的指令數據集,以及超過2500萬個合成樣本,預訓練數據截止到2023年12月。

商用研究皆可
Llama 3.1支持多語言環境下的商業和研究用途。
經過指令微調的純文本模型適用於聊天助手,而預訓練模型可以適應各種自然語言生成任務。Llama 3.1模型集合還支持利用其模型輸出來改進其他模型,包括合成數據生成和模型蒸餾。
違反使用法律法規、被使用政策和Llama 3.1社區許可證禁止、支持語言之外的使用,都屬於超出範圍。
並且團隊強調,除了支持的8種語言,Llama 3.1在更廣泛的語言集合上進行了訓練。開發者對其進行微調,就可以在其他語言上適用,前提是遵守社區許可證等政策,並保證使用是安全和負責的。
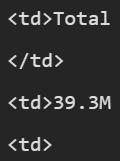
3930萬GPU小時訓練
在預訓練時,Meta使用了定製的訓練庫、Meta定製的GPU集群和生產基礎設施。微調、註釋和評估也都是在生產基礎設施上進行的。
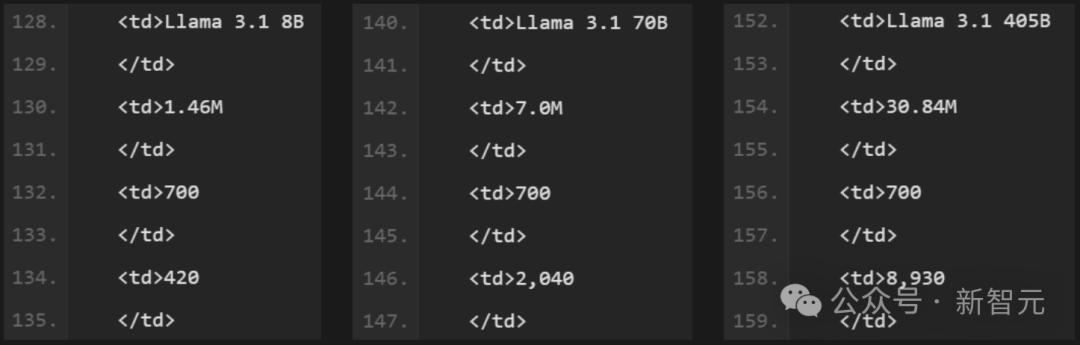
訓練累計使用了3930萬GPU小時的計算時間,硬件類型為H100-80GB(TDP為700W)。
訓練時間是訓練每個模型所需的總GPU時間,功耗是每個GPU設備的峰值功率容量,根據功率使用效率進行了調整。
訓練的總位置基溫室氣體排放估計為11,390噸二氧化碳當量(CO2eq)。
Meta強調,自2020年以來,自己一直保持著淨零的溫室氣體排放,並且100%的電力都是由可再生資源生成的,因此基於市場基準的總溫室氣體排放為0噸二氧化碳當量。

重大風險
在重大風險上,Meta也做了測試。
包括CBRNE(化學、生物、放射性、核和爆炸材料)有用性、兒童安全和網絡攻擊。
在網絡攻擊上,團隊調查了LLMs是否可以提高人類在黑客任務中的能力,包括技能水平和速度。
研究重點在評估LLMs在網絡攻擊行動中用作自主Agent的能力,特別是被勒索軟件攻擊時。
主要目標就是評估這些模型是否能在沒有人為干預的情況下,有效地作為獨立Agent執行複雜的網絡攻擊。
網民炸鍋,再一次見證歷史
磁力鏈放出後,迫不及待的網民直接開始下載,不過這可能需要等待很久。

一部分網民開始坐等Llama 3.1 405B明天發佈,再一次見證歷史!

開源模型與閉源模型的差距,再次縮小了。

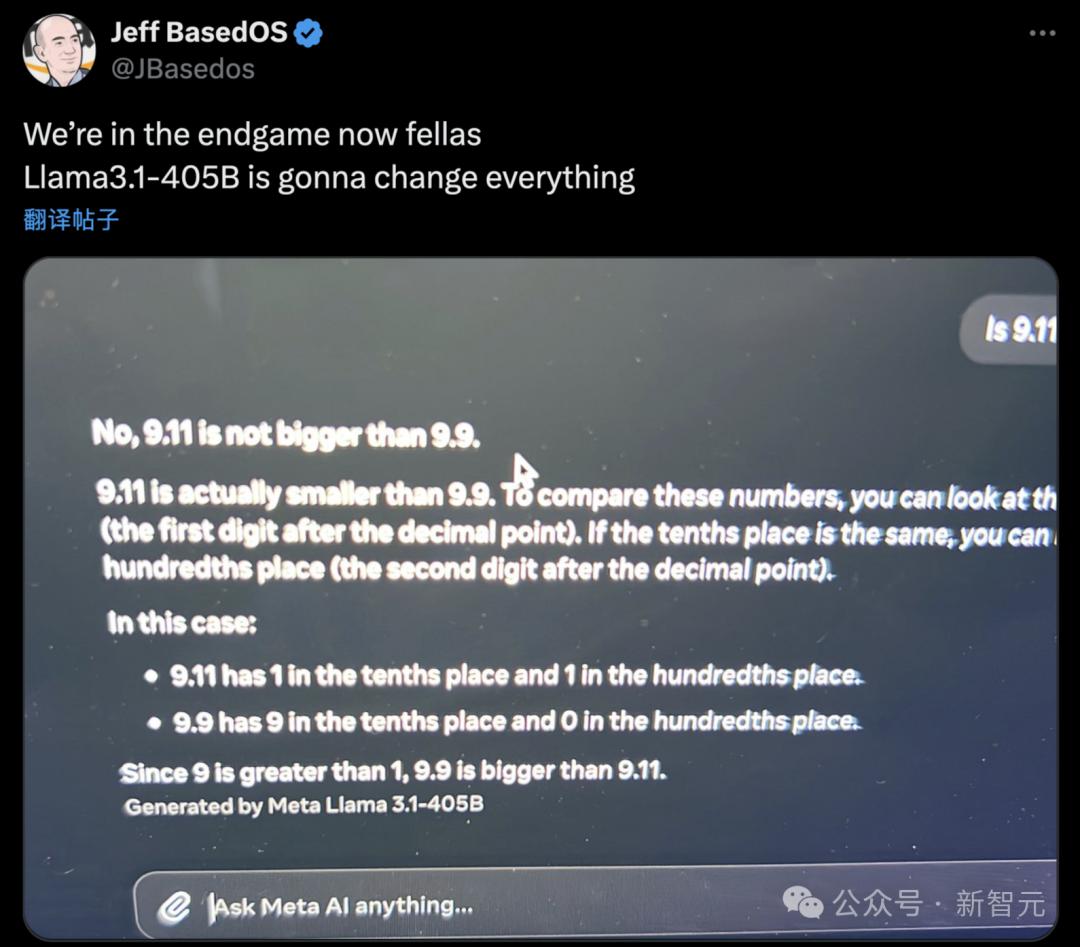
還有人測試了「9.11和9.9誰大」的經典陷阱題,Llama 3.1-405B竟答對了。
對於「GPU窮人」來說,820GB在筆記本上運行實在是太勉強了。




參考資料:
https://x.com/bindureddy/status/1815443198459990098
https://x.com/kimmonismus/status/1815314833236984274
https://x.com/mattshumer_/status/1815453195717742838
https://x.com/swishfever/status/1815512729286815756
本文來自微信公眾號「新智元」,作者:新智元,36氪經授權發佈。



















