Mistral新旗艦決戰Llama 3.1,最強開源Large 2 123B,扛鼎多語言編程全能王
緊跟著Meta的重磅發佈,Mistral Large 2也帶著權重一起上新了,而且參數量僅為Llama 3.1 405B的三分之一。不僅在編碼、數學和多語言等專業領域可與SOTA模型直接競爭,還支持單節點部署。
昨天正式發佈的Llama 3.1模型,讓AI社區著實為之興奮。
但是仔細一想就能發現——405B的參數規模,基本是沒法讓個人開發者在本地運行了。
比如昨天剛發佈,就有一位勇敢的Twitter網民親測,用一張英偉達4090運行Llama 3.1。

結果可想而知,等了30分鐘模型才開始回應,緩緩吐出一個「The」。

最後結果是,Llama給出完整回應,整整用了20個小時。

根據Artificial Analysis的估算,你需要部署含2張8×H100的DGX超算才能在本地運行405B。
看來,小紮對Llama 3.1成為開源AI界Linux的期待,可能和現實有不少的差距。目前的硬件能力,很難支持405B模型的大範圍全量運行。
此時,又一位開源巨頭Mistral精準踩點,發佈了他們的最新旗艦模型Mistral Large 2。

Mistral Large 2在代碼生成、數學和推理等方面的能力明顯增強,可以與GPT-4o和Llama 3.1一較高下。
而且,模型參數量僅有123B,不到Llama 3.1 405B的三分之一,完全可以在單個節點上以大吞吐量運行。
成本效率、速度和性能的「三角形戰士」,Mistral Large當之無愧——
和GPT-4o比,它開源;和Llama 3.1 450B比,它參數少;和Llama 3 70B比,它性能好。
Twitter網民驚呼,「開源AI就這麼捲起來了嗎!」

短短一週時間內,GPT-4o mini、Llama 3.1、Mistral Large 2相繼發佈,有些讓人應接不暇。
「我躺了,你們先捲著。」

但躺平陣營中絕對不包含ollama。前腳Mistral剛官宣,這邊就火速更新。

果然,參數量砍去一大半之後,本地部署難度就大大下降了。
同樣從ollama上下載模型,用96GB內存還是可以順利運行起來的。

雖然3 token/s的生成速度慢了點,但比起用20個小時等模型響應,已經是質的飛躍了。
用前段時間擊穿GPT-4o的「9.11 vs. 9.9」問題測試Large 2,沒想到它竟然答對了。

值得一提的是,Mistral Large首代發佈還不到半年(2024年2月),但並沒有開源,用戶只能通過官方API或Azure訪問。
剛發佈的Mistral Large 2則已經將模型權重託管到了HuggingFace倉庫中,向研究和非商業用途開放,但商業用途的部署仍需要直接聯繫Mistral以取得許可。

HuggingFace地址:https://huggingface.co/mistralai/Mistral-Large-Instruct-2407
不僅上下文窗口從上一代的32k增長到了128k(同Llama 3.1),而且有強大的多語言能力,支持數十種自然語言以及80多種編程語言。
令人印象深刻的是,Mistral Large的預訓練版本在MMLU上的準確率可以達到84%。
這個成績已經超過了340B參數的Nemotron,而且與GPT-4(85.1%)和Llama 3.1(87.3%)基本處於同一水平,可以說是將模型性能/成本的Pareto最優邊界又向前推進了一步。
 出自Llama 3.1論文
出自Llama 3.1論文 01 代碼與推理
基於Mistral之前訓練Codestral 22B和Codestral Mamba的經驗,研究團隊對Mistral Large 2也進行了大量代碼訓練,支持包括Python、Java、C、C++、JavaScript 和Bash在內的80多種語言。
在代碼生成方面,Mistral Large 2遠遠優於Llama 3.1 70B和之前的Mistral Large,與Llama 3.1 405B不相上下。

團隊在提高模型的推理能力方面也投入了大量精力。在訓練過程中,特別關注減少模型的「幻覺」。
實現方法就是通過微調,讓模型的響應更加謹慎而敏銳,確保它提供可靠、準確的輸出。
此外,經過訓練的Mistral Large 2還被賦予了一個品質:承認自己並非無所不知。
在無法找到解決方案,或沒有足夠信息支撐有效回答時,模型會直接承認而非「不懂裝懂」。
Mistral Large 2這種對答案準確性的「責任感」,提升了在數學基準上的表現,展現了更強的推理和解決問題的能力。
在用於代碼生成的HumanEval和HumanEval Plus基準測試中,它的表現優於Claude 3.5 Sonnet和Llama 3.1,僅次於GPT-4o。
 代碼生成基準測試
代碼生成基準測試 在MultiPL-E基準上,Mistral Large 2的平均生成準確率領先Llama 3.1將近1個百分點,而且可以媲美GPT-4o。
縱向比較也可以看出,Codestral系列的經驗對Mistral Large 2有不少助益。僅僅過了5個月,Mistral Large系列的生成準確率就從58.8%飆升至74.4%。

而且,在以數學為重點的基準測試中(GSM8K和MATH),它的表現也可圈可點。
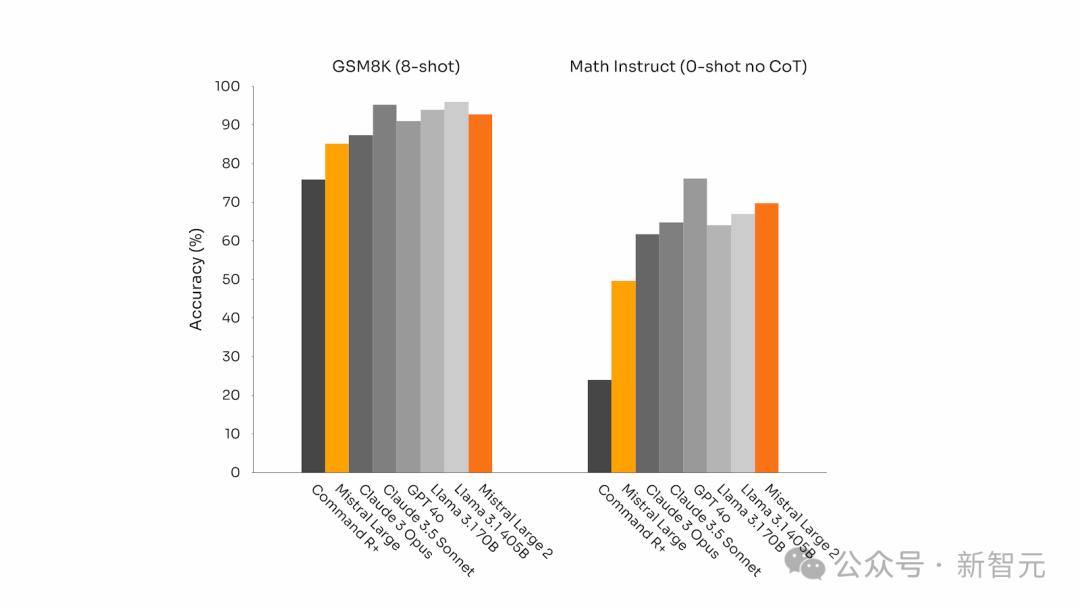 GSM8K(8-shot)和MATH(0-shot,無CoT)基準測試
GSM8K(8-shot)和MATH(0-shot,無CoT)基準測試02 指令執行與對齊
Mistral Large 2的指令執行和對話能力也得到了顯著提升,在執行精確指令和處理長時間多輪對話方面表現尤為出色。
以下是其在Wild Bench和Arena Hard基準測試上的表現:
 通用對齊基準測試
通用對齊基準測試 在一些基準測試中,生成較長的回答通常會提高得分。
然而,在許多商業應用中,答案的簡潔至關重要——簡短的模型響應可以促進更快速的交互,讓推理過程更加高效且降低成本。
Mistral聲稱Large 2可以比領先的人工智能模型產生更簡潔的響應,因為後者傾向於喋喋不休。
下圖展示了不同模型在MT Bench基準測試中問題的平均生成長度:

03 語言多樣性
如今,許多商業應用涉及處理多語言文檔。
儘管大多數模型以英語為中心,但Mistral Large 2在大量多語言數據上進行了訓練。
比如,在法語、德語、西班牙語、意大利語、葡萄牙語、荷蘭語、俄語、中文、日語、韓語、阿拉伯語和印地語等多種語言上,Mistral Large 2都有出色的性能。
以下是Mistral Large 2在多語言MMLU基準測試中的表現結果,並與之前的Mistral Large、Llama 3.1模型以及Cohere的Command R+進行了比較:

在下圖的8種語言上,Mistral Large 2的性能可以媲美Llama 3.1 405。但值得注意的是,所有模型似乎都在中文MMLU上取得了最低分。

04 工具使用與函數調用
Mistral Large 2具備了更強的函數調用和檢索能力,能夠熟練執行並行和順序的函數調用,準確率甚至超過了GPT-4o。

這意味著,Mistral Large 2可以成為複雜商業應用的核心引擎。
除了直接從HuggingFace上下載權重,用戶可以通過官方API平台la Plateforme訪問或微調模型,免費聊天機器人le chat也已經部署了Mistral Large 2。
Vertex AI、Azure Studio等第三方雲平台也託管了Mistral Large 2的API。

參考資料:
https://mistral.ai/news/mistral-large-2407/
Mistral’s Large 2 is its answer to Meta and OpenAI’s latest models
Mistral shocks with new open model Mistral Large 2, taking on Llama 3.1
本文來自微信公眾號「新智元」,作者:新智元,36氪經授權發佈。



















