靈活可擴展的新一代IR技術——飛槳框架3.0基石技術深度解析
為了讓優秀的飛槳開發者們掌握第一手技術動態、讓企業落地更加高效,飛槳官方在7月至10月特設《飛槳框架3.0全面解析》系列技術稿件及直播課程,邀請百度飛槳核心團隊數十位工程師齊上陣,技術解析加代碼實戰,帶大家掌握包括核心框架、分佈式計算、產業級大模型套件及低代碼工具、前沿科學計算技術案例等多個方面的框架技術及大模型訓推優化經驗。
本文是該系列第二篇技術稿件,文末附對應直播課程詳情。
近些年來,越來越多的框架和研究者將編譯器技術引入到深度學習的神經網絡模型優化中,並在此基礎上借助編譯器的理念、技術和工具對神經網絡進行自動優化和代碼生成。作為深度學習框架性能優化、推理部署、編譯器等方向的重要基石——計算圖中間表示(Intermediate Representation,即 IR),在大模型場景下對其靈活性、擴展性、完備性也提出了更高的要求,即如何便捷地支撐大模型自動並行下豐富的切分策略,如何更低成本地實現性能優化 Pass 等。

飛槳框架架構圖
在3.0版本下,飛槳充分考慮大模型對 IR 的需求,在基礎架構層面規範了中間表示 IR 定義,全架構統一表示,實現了推理、分佈式、編譯器等上下遊各方向共享開發成果。飛槳的新一代 IR 架構通過更加完備且魯棒的語義表達能力、訓推全架構統一表示和高效可插拔的性能優化策略(Pass)開發機制,無縫對接神經網絡編譯器實現自動性能優化和多硬件適配,加速大模型訓推流程。
▎什麼是中間表示 IR?

手寫字體識別任務模型

算子表示
對於一個特定的深度學習任務模型,從算法工程師的模型視角來看,主要涉及三個核心概念:數據集(Dataset)、網絡模型(Model)、迭代訓練(Training);但從研發工程師的框架視角來看,主要有兩個核心概念:張量(Tensor)和算子(Operator)。廣義上,算子是「計算操作」的一種表示,比如矩陣乘算子 Matmul,有兩個輸入和一個輸出。狹義上,算子包含計算表示和 Kernel 定義,其中 Kernel 與硬件有很強的關聯性,同一個算子表示可以對應多個 Kernel 定義。比如 Matmul 算子有 CPU Kernel,也有 GPU、XPU、NPU 等硬件上 Kernel。
飛槳採用了動靜統一的技術架構設計,以動態圖為預設編程範式。其即時執行的特點給開發者提供了 Pythonic 的流暢使用體驗,同時提供了動轉靜功能(如飛槳的@to_static)支持用戶可以一鍵轉為靜態圖執行。用戶的模型代碼在靜態圖模式下會先記錄所有的張量和算子操作,構建一個完整的計算圖(即 IR 中間表示),然後借助框架的內核執行器在給定的硬件設備上執行訓練或者推理。

靜態圖模式下執行流程
▎為什麼需要 IR ?
在深度學習框架中,中間表示在架構層面承擔著非常重要的角色,主要包括:
-
推理部署:模型訓練僅是深度學習鏈條中的一環,如何結合業務落地,導出模型推理部署開發給用戶使用,與計算圖中間表示息息相關。
-
性能優化:IR 中包含了計算圖的全局信息(如上下遊算子的鄰接關係等),更有利於進行圖優化,如常量摺疊、算子融合、Inplace 策略等。
-
神經網絡編譯器:將 IR 中的全局信息傳遞給飛槳 CINN 編譯器,可實現子圖自動融合、Kernel 自動生成,節省工程師 80% 的時間達到人工調優相似的性能。
-
社區生態:IR 表示本質是一層「協議」的概念,借助飛槳套件工具(如X2Paddle、Paddle2ONNX)與其他開源生態自由轉換。

性能優化 Pass

社區生態
▎初窺 Paddle IR
飛槳新的一代 IR 是基礎架構層面的升級,對於用戶在 API 層面的使用是無感的,用戶可保持之前動轉靜(即 paddle.jit.to_static)或靜態圖代碼不變,在3.0-Beta 下僅需額外通過export FLAGS_enable_pir_api=1開啟新 IR 功能即可,如下是一個簡單的使用樣例。
# test_add_relu.pyimport unittestimport numpy as npimport paddlefrom paddle.static import InputSpecclass SimpleNet(paddle.nn.Layer):def __init__(self):super().__init__()def forward(self, x, y):z = x + yout = paddle.nn.functional.relu(z)return out# Step 1: 構建模型對象,並應用動轉靜策略specs = [InputSpec(shape=(-1, -1)), InputSpec(shape=(-1, -1))]net = paddle.jit.to_static(SimpleNet(), specs)# Step 2: 準備輸入,執行 forwardx = paddle.rand(shape=[16, 64], dtype=paddle.float32)y = paddle.rand(shape=[16, 64], dtype=paddle.float32)out = net(x, y)print(out)
將上述文件保存為 test_add_relu.py,執行如下命令:FLAGS_enable_pir_api=1 python test_add_relu.py 即可。開發者可額外指定 GLOG_v=6輸出日誌,查看新一代 IR 下的 Program 表示,如下所示,在動轉靜或靜態圖模式下,用戶的代碼經過組網 API 下會先生成 Operator Dialect 下計算圖表示,在執行時飛槳會將其轉換為給定硬件下的 Kernel Dialect,然後交給執行器去依次調度對應的 PHI 算子庫,計算最終結果。
{ // Operator Dialect(%0) = "pd_op.data" () {dtype:(pd_op.DataType)float32,name:"x",place:(pd_op.Place)Place(undefined:0),shape:(pd_op.IntArray)[-1,-1],stop_gradient:[true]} : () -> builtin.tensor<-1x-1xf32>(%1) = "pd_op.data" () {dtype:(pd_op.DataType)float32,name:"y",place:(pd_op.Place)Place(undefined:0),shape:(pd_op.IntArray)[-1,-1],stop_gradient:[true]} : () -> builtin.tensor<-1x-1xf32>(%2) = "pd_op.add" (%0, %1) {stop_gradient:[true]} : (builtin.tensor<-1x-1xf32>, builtin.tensor<-1x-1xf32>) -> builtin.tensor<-1x-1xf32>(%3) = "pd_op.relu" (%2) {stop_gradient:[true]} : (builtin.tensor<-1x-1xf32>) -> builtin.tensor<-1x-1xf32>() = "builtin.shadow_output" (%3) {output_name:"output_0"} : (builtin.tensor<-1x-1xf32>) ->}// IR after lowering{ // Kernel Dialect(%0) = "data(phi_kernel)" () {dtype:(pd_op.DataType)float32,kernel_key:<backend:Undefined|layout:Undefined(AnyLayout)|dtype:float32>,kernel_name:"data",name:"x",op_name:"pd_op.data",place:(pd_op.Place)Place(undefined:0),shape:(pd_op.IntArray)[-1,-1],stop_gradient:[true]} : () -> undefined_tensor<-1x-1xf32>(%1) = "shadow_feed(phi_kernel)" (%0) {kernel_key:<backend:GPU|layout:Undefined(AnyLayout)|dtype:float32>,kernel_name:"shadow_feed",op_name:"pd_op.shadow_feed"} : (undefined_tensor<-1x-1xf32>) -> gpu_tensor<-1x-1xf32>(%2) = "data(phi_kernel)" () {dtype:(pd_op.DataType)float32,kernel_key:<backend:Undefined|layout:Undefined(AnyLayout)|dtype:float32>,kernel_name:"data",name:"y",op_name:"pd_op.data",place:(pd_op.Place)Place(undefined:0),shape:(pd_op.IntArray)[-1,-1],stop_gradient:[true]} : () -> undefined_tensor<-1x-1xf32>(%3) = "shadow_feed(phi_kernel)" (%2) {kernel_key:<backend:GPU|layout:Undefined(AnyLayout)|dtype:float32>,kernel_name:"shadow_feed",op_name:"pd_op.shadow_feed"} : (undefined_tensor<-1x-1xf32>) -> gpu_tensor<-1x-1xf32>(%4) = "add(phi_kernel)" (%1, %3) {kernel_key:<backend:GPU|layout:NCHW|dtype:float32>,kernel_name:"add",op_name:"pd_op.add",stop_gradient:[true]} : (gpu_tensor<-1x-1xf32>, gpu_tensor<-1x-1xf32>) -> gpu_tensor<-1x-1xf32>(%5) = "relu(phi_kernel)" (%4) {kernel_key:<backend:GPU|layout:NCHW|dtype:float32>,kernel_name:"relu",op_name:"pd_op.relu",stop_gradient:[true]} : (gpu_tensor<-1x-1xf32>) -> gpu_tensor<-1x-1xf32>() = "builtin.shadow_output" (%5) {output_name:"output_0"} : (gpu_tensor<-1x-1xf32>) ->}
▎PIR 架構設計
在深度學習框架 IR 概念中,「順序性」和「圖語義」是兩個非常高頻常用的概念。舊的中間表示體系由「順序性」ProgramDesc 和「圖語義」Graph 兩個核心類共同承載。用戶在靜態圖 API 或者動轉靜模塊下,產生的中間表示是 Op-by-Op 的 Program,如果要應用更高層面的優化策略(比如算子融合、inplace 策略、剪枝等),框架會將由 Program 構造出 Graph,其由數據節點、算子節點和彼此關聯的邊構成。


Paddle IR 分層架構圖
在新的 Paddle IR 中,飛槳在底層抽像了一套高度可擴展的基礎組件,包括 Type、Attrbute、Op、Trait 和 Interface,並引入了 Dialect 的概念,支持開發者靈活擴展、自由定製,提供了完備魯邦的語義表達能力;在模型表示層,通過多 Dialect 模塊化管理,統一多端表示,實現了訓推一體的全架構統一表示,無縫銜接組合算子和編譯器,支持自動優化和多硬件適配;在圖變換層,通過統一底層模塊,簡化基礎概念,向用戶提供了低成本開發、易用高性能、豐富可插拔的 Pass 優化機制。飛槳的新一代的 IR 表示堅持 SSA(靜態單賦值)原則,模型等價於一個有向無環圖。並以 Value、Operation 對計算圖進行抽像:
-
Operation 表示計算圖中的節點:一個 Operation 表示一個算子,它里麵包含了零個或多個 Region;Region 表示一個閉包,它里麵包含了零個或多個 Block;Block 表示一個符合 SSA 的基本塊,里麵包含了零個或多個 Operation;三者循環嵌套,可以實現任意複雜的語法結構。
-
Value 表示計算圖中的有向邊:用來將兩個 Operaton 關聯起來,描述了程序中的 UD 鏈(即 Use-Define 鏈);OpResult 表示定義端,定義了一個 Value,OpOperand 表示使用端,描述了對一個 Value 的使用。
如上左圖所示,新一代 IR 的整體設計自底向上分為三層:
■ 靈活的基礎組件
飛槳提供了 Trait 和 Interface 兩種重要機制實現了對算子 Op 的特徵和接口的抽像標記。比如 InplaceTrait 表示一個 Op 具有 Inplace 特徵, InferShapeInterface 表示一個算子定義了 InferShape 函數接口等,這二者都是可以任意擴展的,僅派生自相應的基類、遵循相應的實現規則即可;並對算子體系下核心概念抽像出 Type、Attrbute、Op,這三者是基於 Trait 和 Interface 進行定義的。Dialect 用來對 Type、Attribtue、Op 做模塊化管理, 比如 BuiltinDialect、DistDialect、CinnDialect 等等。一個 Dialect 里麵包含了一系列的 Type、Attribtue、Op 的定義。相應的,每個 Type、Attribtue、Op 都是定義在某個唯一的 Dialect 裡面。對整個 IR 框架而言, Dialect 是可以隨意插拔的,也是可以任意擴展的。
這一層是 IR 適應多種場景的基礎。這一層的每一個要素都是可定製化擴展,一般情況下,針對一個具體的場景(比如分佈式、編譯器)只需要在其 Dialect 中定義特定的 Trait、Interfce 以及 Type、Attribute、Op 即可。
■ 多層級的 Dialect
飛槳通過不同層級的 Dialect 來管理框架內不同領域的算子體系,比如 Built-in 下的 Shape Dialect 和 Control Flow Dialect(分別用於形狀符號推導和控制流表示)、與 PHI 算子庫執行體系相關的 Operator Dialect 和 Kernel Dialect、與神經網絡編譯器領域相關的 CINN Dialect 等。在飛槳神經網絡編譯器中,主要以計算圖 Operator Dialect 為輸入,經過組合算子和 Pass Pipline 後,會轉換為 CINN Dialect,並附加 Shape Dialect 中的符號信息,最後會 Lowering 成編譯器的 AST IR。
上述這些多層級的 Dialect 內的算子 Op 會組成 Program ,並用來表示一個具體的模型,它包含兩部分:計算圖和權重 。
-
Value、Operation 用來對計算圖進行抽像。Value 表示計算圖中的有向邊,用來將兩個 Operaton 關聯起來,描述了程序中的 UD 鏈 ,Operation 表示計算圖中的節點。一個 Operation 表示一個算子,它里麵包含了零個或多個 Region 。Region 表示一個閉包,它里麵包含了零個或多個 Block。Block 表示一個符合 SSA 的基本塊,里麵包含了零個或多個 Operation 。三者循環嵌套,可以實現任意複雜的語法結構。
-
Weight 用來對模型的權重參數進行單獨存儲,這也是深度學習框架和傳統編譯器不一樣的地方。傳統編譯器會將數據段內嵌到程序裡面。這是因為傳統編譯器裡面,數據和代碼是強綁定的,不可分割。但是對神經網絡而言,一個計算圖的每個 epoch 都會存在一份權重參數,多個計算圖也有可能共同一份權重參數。
■ 功能完善的 Pass 體系
Pass 的核心是子圖匹配和替換(即圖變換),是將一個 Program 通過某種規則轉換為另一個新的 Program。IR 中包含了計算圖中全局信息,如上下遊算子的鄰接關係等,更有利於進行圖優化,比如常量摺疊、算子融合,Inplace 策略等。我們將在第三章節詳細介紹 Pass 開發機制。
飛槳以 Paddle IR 為基礎,提供了高效可插拔的性能優化 Pass 策略開發機制,在訓練、推理、分佈式、編譯器等多領域場景下可複用,且友好支持多硬件定製化。在新 IR 體系下,飛槳支持2種 Pass 開發範式:Pattern Rewriter 和 DRR,充分兼顧自定義靈活性和開發易用性,實現了 Pass 開發成本降低58%;應用於推理場景,超過84%的模型推理加速超10%。

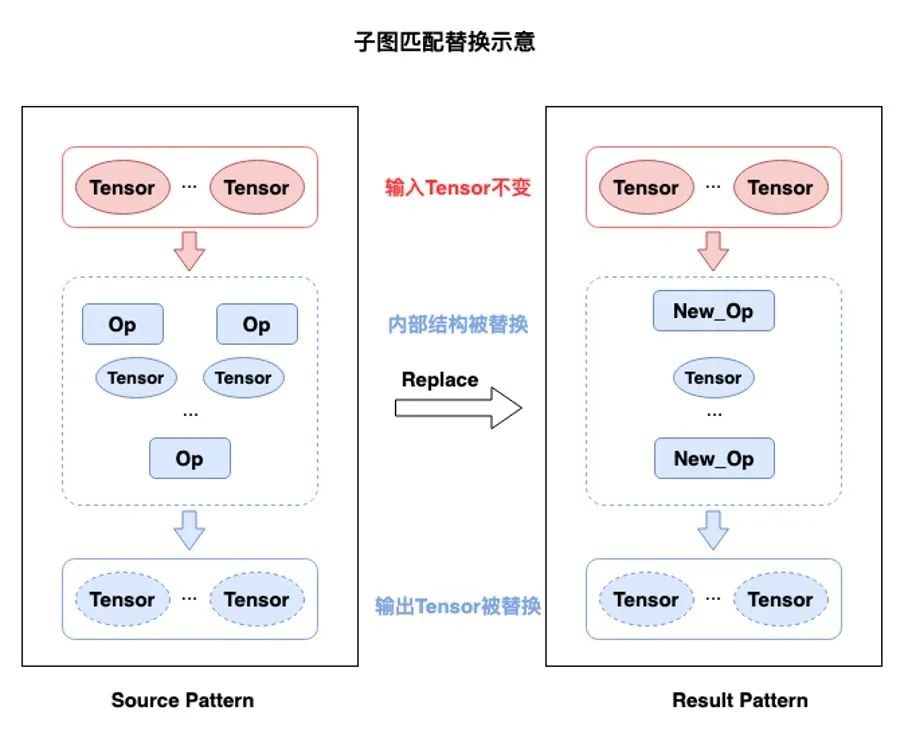
▎Pattern Rewriter 機制
Pass 的核心是一個「子圖匹配和替換」的過程,一般需要開發者定義待替換子圖的源 Pattern,以及期望替換的目標 Pattern。在 Pattern Rewriter 機制下,分別對應於實現 Match 和 Rewrite 邏輯。
舉個例子,假設在 Kernel Dialect 里,我們期望移除冗餘的 Feed 算子,以提升執行效率。則需要如下兩個步驟。

1.繼承 PatternRewritePass類:只需要在 InitializePatterns 里添加目標算子的 Pattern 即可,開發者無需關心計算圖遍曆實現;
2.定義Match 和 Rewrite邏輯:新增目標算子的Pattern,實現 Match 和 Rewrite 接口函數。
▎DRR 機制
Declarative Rewrite Rule 機制(即 DRR)是一種三段式 Pass 開發範式,讓開發者更聚焦於 Pass 邏輯的處理,無需關心底層 IR 的實現細節,所見即所得。
舉個例子,在混合精度訓練的計算圖中,常會出現連續的 DataType 相關的 Cast 操作。從優化角度,類似連續的 Cast 操作完全可以簡化成一個 Cast 即可,如下圖左側示意圖。


基於 DRR 的 Pass 機制,我們只需要如下兩個簡單的步驟。
1.繼承 DrrPatternBase 模板類:此模版類提供了一系列的基礎方法,幫助用戶用更簡潔的形式描述中間 DAG 子圖表示的 Pattern 信息。
2.定義Source/Target Pattern:通過 DrrPatternContext來創建、描述源、目標Pattern,僅需要聚焦算子的輸入、輸出關係即可。
什麼是 Dialect 呢?可以簡單理解為「域」的概念,是高度靈活性的核心支撐。飛槳新 IR 下可以定義不同的 Dialect,如用於編譯期算子定義的 Operator Dialect、用於執行期的 Kernel Dialect、用於 AI 編譯器的 CINN Dialect 等。
-
「從類型的角度,恰當分層的軟件棧需要支持對張量、buffer、向量、標量等進行建模,以及一步步分解和 Lowering」
-
「從操作的角度,我們需要計算和控制流、控制流可以是顯式的基礎塊跳轉,也可以內含於結構化操作中」

編譯器架構概覽
在飛槳神經網絡編譯器中,以計算圖 Operator Dialect 為輸入,經過組合算子和 Pass Pipline 後,會轉換為 CINN Dialect,並附加 Shape Dialect 中的符號信息,最後會 Lowering 編譯器 AST IR。各階段涉及的 Dialect 主要為:
-
計算圖:為 Operator Dialect,是原始計算圖表示,包含未拆解的大算子,以及原始的動態 Shape,無符號約束信息;
-
符號推導:為 Shape Dialect,經過組合算子拆分後,會調用基礎算子的 InferSymbolicShape 邏輯,記錄張量 Tensor 的符號信息和邏輯計算表達式;
-
編譯器高層 IR:為 CINN Dialect,編譯器在算子層面有特殊的定義,比如「屬性信息靜態化」,以滿足更高的優化潛力,框架會使用 Dialect 之間的 Convert Pass 將 Operator Dialect 中的特定算子轉換為 CINN Dialect 中對應的算子;
在 3.0 框架中,飛槳對150+個基礎算子和典型算子新增支持了動態 Shape 的推導邏輯(即 InferSymbolicShape),可動態地隨計算圖 Pass 的應用來自適應且 Lazy 地更新計算圖中間表示的符號信息。
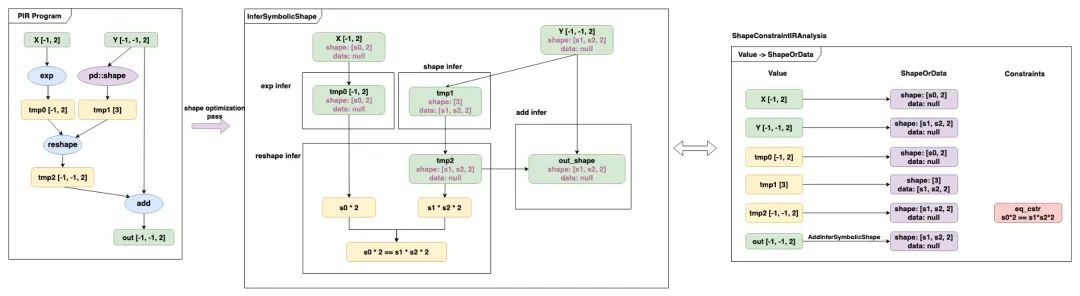
動態符號推導流程
飛槳 3.0 Beta 版本下,推出了新一代中間表示 PIR,這項技術對底層的核心概念如 Operation、Attribute 等進行了系統性的抽像,為開發者提供了靈活的基礎組件;同時,通過引入 Dialect 這一概念,飛槳能夠全面、分層次管理框架各模塊對中間表示的需求,並支持開發者根據需求定製化擴展 Dialect,顯著提升了框架的擴展性。PIR 遵循 SSA(即 Static Single Assignment)原則,統一了頂層結構,實現「算子順序性」和「計算圖語義」的兼容表示。此外,PIR 還提供了更加簡潔、低成本的 Pass 開發流程(DRR 和 pattern write),並內置了一系列豐富且功能完備的 Pass 優化策略,實現了 Pass 開發成本降低58%;應用於推理場景,超過84%的模型推理加速超10%,為大模型的極致性能優化提供了強有力支撐。
▎官方開放課程
7月-10月特設《飛槳框架3.0全面解析》直播課程,邀請百度飛槳核心團隊數十位工程師傾囊相授,技術解析+代碼實戰,帶大家掌握核心框架、分佈式計算、產業級大模型套件及低代碼工具、前沿科學計算技術案例等多個方面的框架技術及大模型訓推優化經驗,實打實地幫助大家用飛槳框架3.0在實際開發工作中提效創新!
▎飛槳動態早知道
為了讓優秀的飛槳開發者們掌握第一手技術動態、讓企業落地更加高效,根據大家的呼聲安排史上最強飛槳技術大餐!涵蓋飛槳框架3.0、低代碼開發工具 PaddleX、大語言模型開髮套件 PaddleNLP、多模態大模型開髮套件 PaddleMIX、典型產業場景下硬件適配技術等多個方向,一起來看吧!
溫馨提示:以上僅為當前籌備中的部分課程,
如有變動,敬請諒解。
▎拓展閱讀
【前序技術稿件】
【3.0-Beta 影片教程】
https://aistudio.baidu.com/course/introduce/31815
【3.0-Beta 官方文檔】
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/index_cn.html
【開始使用】
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/overview_cn.html#jiukaishishiyong
【動轉靜 SOT 原理及使用】
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/sot_cn.html
【自動並行訓練】
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/auto_parallel_cn.html
【神經網絡編譯器】
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/cinn_cn.html
【高階自動微分功能】
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/higher_order_ad_cn.html
【PIR 基本概念和開發】
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/paddle_ir_cn.html
【飛槳官網】
https://www.paddlepaddle.org.cn/
【企業合作入口】
https://paddle.wjx.cn/vm/m3sxpfF.aspx#



















