4輪暴訓,Llama 7B擊敗GPT-4,Meta等讓LLM「分飾三角」自評自進化
Meta、UC伯克利、NYU共同提出元獎勵語言模型,給「超級對齊」指條明路:讓AI自己當球證,自我改進對齊,效果秒殺自我獎勵模型。
LLM對數據的大量消耗,不僅體現在預訓練語料上,還體現在RLHF、DPO等對齊階段。
後者不僅依賴昂貴的人工標註數據,而且很可能讓人類水平限制LLM的進一步發展。
今年1月,Meta和NYU的團隊就提出了語言模型的自我獎勵機制,使用LLM-as-a-Judge的提示機制,讓模型在訓練期間進行自我反饋。
 論文地址:https://arxiv.org/abs/2401.10020
論文地址:https://arxiv.org/abs/2401.10020論文發現,即使不依靠人類標註者,LLM也能通過評價自己的響應實現性能提升。
最近,這個團隊又發表了一篇研究,將LLM「自我獎勵」這件事情再拔高了一個層次。
 論文地址:https://arxiv.org/abs/2407.19594
論文地址:https://arxiv.org/abs/2407.19594畢竟是自己給自己打分,因此不能只關注模型作為actor如何從反饋中優化,也需要保證模型作為judge具備優秀的自我評價能力。
之前的研究就因為過於關注前者而忽略後者,造成了迭代訓練期間性能的過快飽和。
甚至,還有可能造成比飽和更差的情況,即對獎勵信號的過度擬合(reward hacking)。
因此,來自Meta、NYU、UC伯克利等機構的研究者們提出,還需要增加一個「元獎勵」步驟——讓模型評價自己的評價,從而提升評價能力。
雖然聽起來有點繞,但實際是合理的。而且實驗發現,加上這一層嵌套有顯著的提升效果。
比如Llama-3-8B-Instruct在AlpacaEval 2上的勝率就從22.9%增至39.4%,比GPT-4的表現更佳;在Arena-Hard上則從20.6%提升至29.1%。
如果說,今年1月發表的研究是LLM-as-a-Judge,那麼這篇論文提出的「元獎勵」,就相當於LLM-as-a-Meta-Judge。
不僅Judge不需要人類,Meta-Judge也能自給自足,這似乎進一步證明,模型的自我提升可以擺脫對人類監督的依賴。
Meta科學家Yann LeCun也轉發了這篇研究,並親自下場玩起了雙關梗——

Meta提出的Meta-Judge,FAIR能否實現fair?
研究不重要,重要的是Meta FAIR這一波曝光率拉滿了。

01 元獎勵(Meta-Rewarding)
用更直白的話說,「元獎勵」方法就是在原有的actor-judge的互動中再引入meta-judge,且由同一個模型「分飾三角」,不需要額外人類數據的參與。

其中,actor負責對給定提示生成響應;judge負責為自己的響應進行評價和打分;而meta-judge會對自己的打分質量進行對比。
最終的優化目標,是希望actor能生成更好的響應,但訓練效率依賴於judge的準確率。
因此,meta-judge作為訓練judge的角色,可以同時提升模型作為actor和judge的性能。
這三種角色組成的迭代訓練模式如圖1所示,在第t個步驟中,先收集模型M_t對提示x的響應,由再讓M_t對自己進行評價,由此得到用於訓練actor的偏好數據。
之後,給定同一個響應內容y,讓M_t生成各種不同評價的變體,由meta-judge進行打分和排名,由此得到用於訓練judge的偏好數據。
結合上述的兩類偏好數據,通過DPO方法對模型M_t進行偏好優化,就完成了一輪迭代,得到模型M_(t+1)。
長度偏好
之前的工作曾經發現,作為judge的模型會偏好更長的響應,這會導致多輪迭代後答案的「長度爆炸」。
因此,作者引入了一種簡潔的「長度控制」(length-control)機制——使用參數ρ∈[0,1],權衡judge的評分和響應文本長度。
比如,對於分數在第一梯隊的模型響應,即分數範圍為[(1-ρ)Smax+ρSmin, Smax],選擇其中最短的響應作為最優答案。
Judge偏好數據的創建
首先,選擇judge最沒有把握的模型響應,通過分數方差衡量judge的確定性。對於每個選中的響應y,我們有最多N個對應的模型評價{j1, … , jN}。
之後,對其中的每一對(jm, jn)進行成對評估,使用如圖2所示的meta-judge提示模板。

除了給出評價結果,meta-judge還需要生成CoT推理過程。
為減少meta-judge可能存在的位置偏好(可能傾向於選擇最先出現的Judgment A),對同一對數據(jm, jn)會交換順序讓meta-judge進行兩次評價,得到單次結果rmn:

引入參數w1、w2用於表徵可能存在的位置偏好:

其中win1st和win2nd表示在meta-judge的整個評價過程中,兩個位置的評價分別有多少次勝出。
用以上變量構建「對決矩陣」(battle matrix)B記錄每一次的最終結果:

利用Elo評分,可以從矩陣B計算meta-judge給每個judge賦予的元獎勵分數。

作者發現,meta-judge和judge一樣,也會展現出「長度偏好」,傾向於選擇更長的評價意見。
為了避免最終訓出的模型過於囉嗦,構建judge數據集時也採取了過濾措施。如果meta-judge選中的評價意見超過一定長度,整個數據對都會被直接捨棄。
02 評估實驗
實驗準備
實驗使用Llama-3-8B-Instruct作為種子模型,其他方面的實驗設置與之前發表的論文《Self-Rewarding Language Models》一致。
在元獎勵訓練之前,實驗首先在EFT(Evaluation Fine-Tuning)數據集上對種子模型進行監督微調(SFT)。
EFT數據集是根據Open Assistant構建的,並提供初始的LLM-as-a-Judge訓練數據,包含經過排名的人類響應,能訓練模型充當法官。
對於元獎勵迭代,實驗利用2萬個提示,由Llama-2-70B-Chat經過8-shot提示生成。

如上圖所示,訓練所用的提示在分佈上更接近AlpacaEval數據集,而Arena-Hard的提示集中分佈於訓練提示的一個子集。
對於每次迭代,實驗從該種子集中抽取5,000個提示,總共進行四次迭代。
迭代過程如下:
– Iter 1:從初始的SFT模型開始,使用DPO(Direct Preference Optimization)對生成的actor和judge的偏好對進行訓練,獲得M1。
– Iter 2:使用DPO對M1生成的actor和judge偏好對進行訓練,獲得M2。
– Iter 3/4:使用DPO僅對M2/M3生成的actor偏好對進行訓練,獲得M3/M4。
每個prompt都讓模型生成K=7個響應,每次迭代總共生成3.5萬個響應。然後,我們過濾掉相同的響應(通常刪除不超過50個重覆項)。
接下來,使用相同的采樣參數為每個響應生成N = 11^2個不同的判斷。
評估方法
元獎勵模型的目標是要讓模型既能自己「演」,還能自己「評」,因此實驗也要評估模型在這兩個角色中的表現如何。
基線模型是前述論文中提出的自我獎勵模型,帶有相同的「長度控制」機制,可以直接對比出元獎勵機制帶來的性能增益。
首先,先看看如何評判「演」的怎麼樣。
實驗利用三個基於GPT4-as-a-Judge的自動評估基準,包括AlpacaEval 2、Arena-Hard和MT-Bench,分別側重於模型的不同方面。
例如,AlpacaEval主要關注聊天場景,提示集涵蓋了各種日常問題。
相比之下,Arena-Hard包含更複雜或更具挑戰性的問題,要在預定義的7個方面(創造力、複雜性、問題解決能力等)滿足更多的標準。
MT-Bench有8個不同的問題類別,主要評估模型的多輪對話能力。
另一方面,為了評估LLM法官「評」的怎麼樣,實驗測量了LLM給的分數與人類偏好的相關性。如果沒有可用的人類標註數據,則使用較強的AI法官代替。
指令跟隨評估
圖3展示了在AlpacaEval基準上,元獎勵方法(帶有長度控制機制)勝率隨訓練迭代的變化。
總體來看,元獎勵的勝率從22.9%大幅提升到39.4%,超過了GPT-4,並接近Claude Opus模型。

考慮到種子模型參數量只有8B,並且,除了在SFT階段使用的EFT數據集,沒有引入任何額外的人工數據,這是一個相當優秀的結果。
另外,結果也證明了meta-judge和長度控制機制的重要性。
自我獎勵模型訓練到超過3輪時,開始出現飽和跡象,但帶有元獎勵的模型並沒有,到第4輪時仍保持性能增長。
這表明了對模型評價能力進行訓練的重要性,以及meta-judge這一角色的有效性。
如表1所示,經過4輪迭代,無論是自我獎勵模型還是元獎勵模型,平均響應長度(以字符為單位)都沒有顯著增加,證明長度控制機制的有效性。

元獎勵機制有以下三個較為明顯的改進。
首先,將AlpacaEval中的805個類別細分為18個類別進行詳細分析,可以看到,元獎勵幾乎改進了所有類別的響應(圖4),包括需要大量知識和推理的學科,例如科學(Science)、遊戲(Gaming)、文學(Literature)等。
值得注意的是,旅遊(Travel)和數學(Mathematics)這兩類,模型並沒有實現顯著提升。

第二,元獎勵改進了對於複雜和困難問題的回答。
實驗進一步使用Arena-Hard評估在元獎勵方法在回答覆雜和具有挑戰性的問題上的表現。
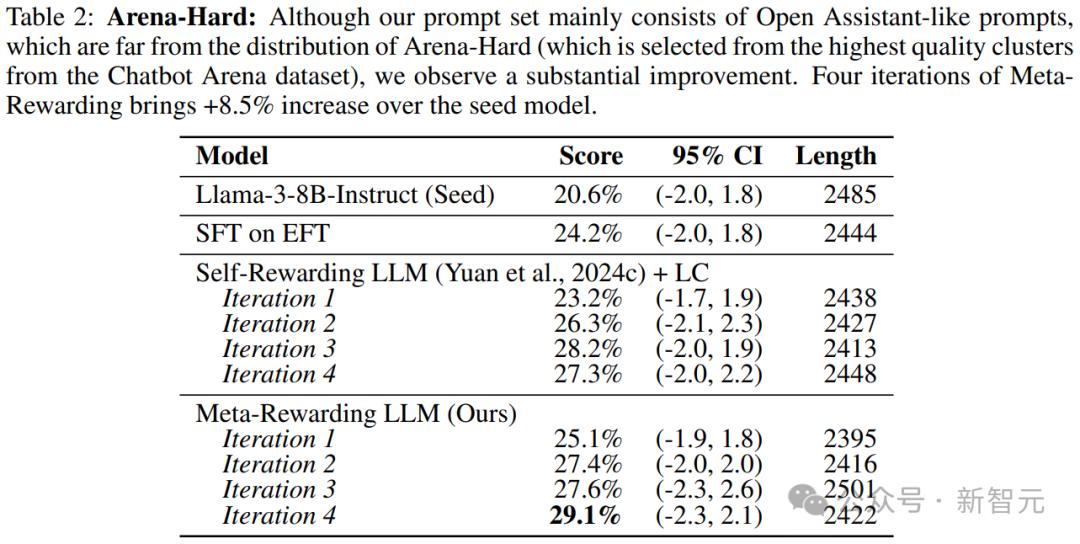
表2中的評估結果顯示,元獎勵在4次迭代中都能提高分數,與種子模型(20.6%)相比,顯著提高了8.5%。
第三,元獎勵在僅訓練單輪對話的情況下也並未犧牲多輪對話能力。
論文進行了MT-Bench評估,以檢查在僅訓練單輪數據的情況下多輪對話能力的損失。
結果如下表顯示,元獎勵模型的4次迭代顯著提高了第一輪對話得分,從8.319(種子模型)提高到8.738,而第二輪對話得分僅下降了不超過 0.1。
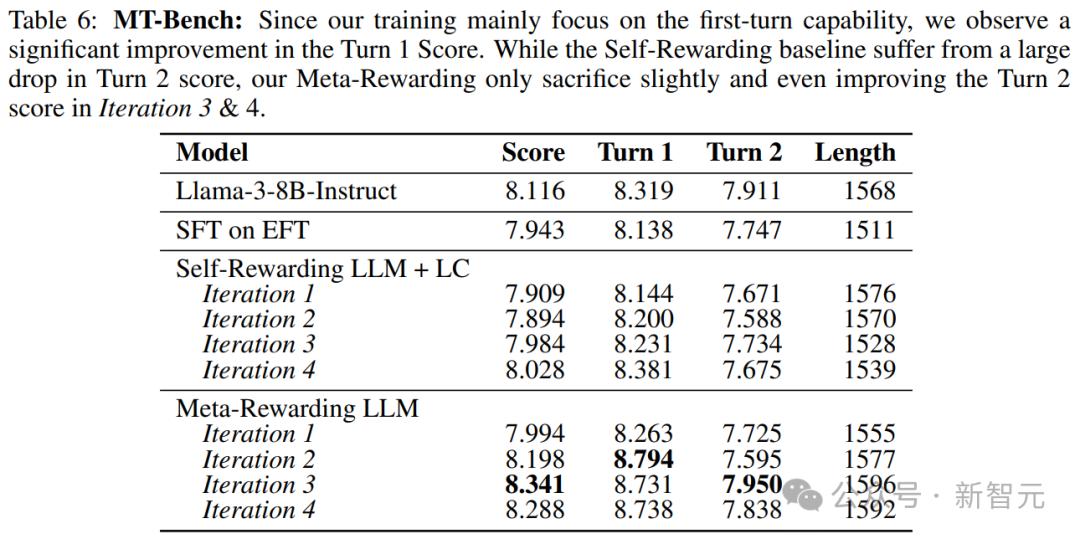
這是對基線模型中自我獎勵+長度控制(Self-Rewarding + LC)的巨大改進,因為後者通常會在第二輪對話得分上,下降超過 0.2,同時沒有提高第一輪對話得分。
獎勵模型評估
實驗評估了模型對種子模型Llama3-8B-Instruct生成響應的判斷準確性。
在缺乏人工標註的情況下,作者選擇測量元獎勵模型與當前最強的判斷模型gpt-4-1106-preview之間的評分相關性。
分析採用了兩種略有不同的設置,主要區別在於它們如何處理判斷模型給出的和波,因此使用了兩種指標:將和波計為0.5的一致性分數(agreement)和捨棄和波結果的一致性分數。
結果顯示,模型在進行訓練後判斷能力有所提高。
表3中的分析顯示,與基線模型相比,在兩種評估設置中,元獎勵與強大的GPT-4判斷模型之間的相關性顯著提高。
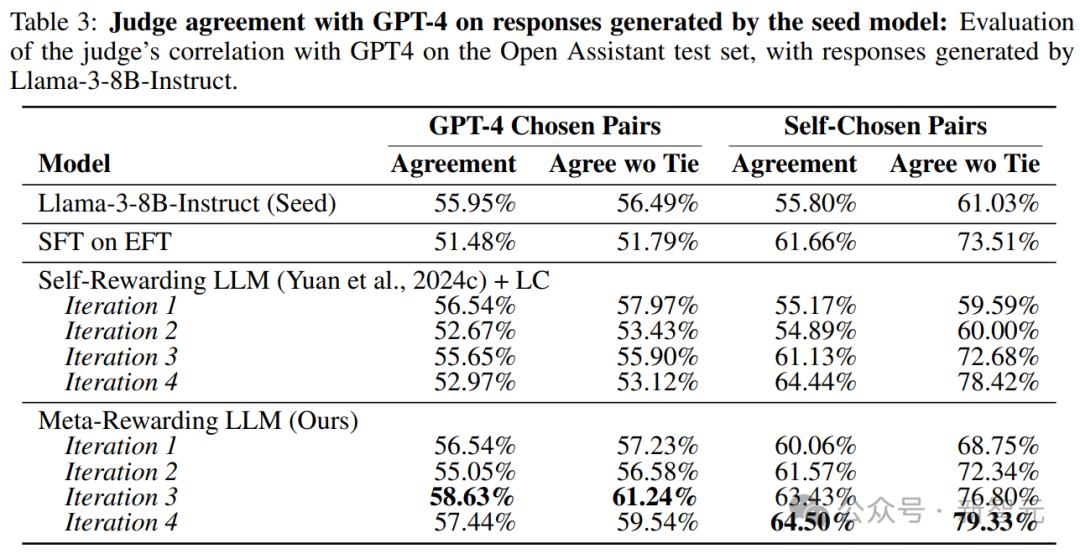
這些結果表明,元獎勵方法能夠改進模型判斷能力,使其評估結果與更複雜的語言模型GPT-4的評估結果更加接近。
此外,實驗對比了模型判斷結果與Open Assistant數據集中人類響應排名的相關性(表7),發現元獎勵訓練提高了與人類的判斷相關性。

然而,這種改進在後續訓練迭代中沒有持續,可能是由於模型生成的響應與人類響應之間的分佈差異導致的。
分析
長度控制機制
長度控制機制對於保持模型響應的全面性和簡潔性之間的平衡至關重要。
實驗比較了最後一次訓練迭代中不同長度控制參數ρ的結果,如表4所示:

ρ = 0,相當於在偏好數據選擇中不進行任何長度控制。
正如預期的那樣,這種訓練方式使得模型生成的響應變得過於冗長,LC勝率降低。
使用外部獎勵模型進行訓練
元獎勵機制讓模型自己作為judge,來評估其自身的響應;實驗嘗試了使用強大的外部獎勵模型Starling-RM-34B作為對比。
然而,結果發現StarlingRM-34B未能在第一次迭代中提高AlpacaEval的LC勝率(24.63% vs. 27.85%),這可能是由於其長度偏見。
meta-judge偏見
在元獎勵訓練的第一次迭代之後,meta-judge幾乎總是更傾向於更高分數的判斷,如表5所示。

這種分數偏見顯著地將判斷的評分分佈向滿分5分傾斜。對於位置偏見,我們也看到在訓練過程中有增加的趨勢,特別是在比較兩個相同分數的判斷時。
判斷評分變化:為了調查在元獎勵訓練迭代過程中判斷評分分佈的變化,實驗使用與獎勵建模評估相同的驗證提示。
使用Llama-3-8B-Instruct在每個提示上生成7個響應,然後為每個響應生成11次判斷。圖5是評分分佈的可視化,密度是使用高斯核密度估算的。

可見,使用meta-judge訓練判斷進一步增加了其生成高分的可能性。
然而,判斷訓練的前兩次迭代使其傾向於分配4.5、4.75、4.9的分數,根據根據指示這些分數應該是整數。
儘管這些是高分,但它們提供了更細緻的區分能力,以區分不同質量的響應。
03 結論
實驗提出了一種新機制,通過使用meta-judge為作為judge的模型分配元獎勵(meta-rewards),從而提高模型的評判能力。
這解決了自獎勵(Self-Rewarding)框架的一個主要限制,即缺乏對模型評判能力的訓練。
為了使元獎勵訓練(Meta-Rewarding training)更加有效,實驗還引入了一種新的長度控制技術,以緩解在使用AI反饋進行訓練時出現的長度爆炸問題。
通過自動評估基準AlpacaEval、Arena-Hard和MT-Bench,元獎勵方法的有效性也得到了驗證。
值得注意的是,即使在沒有額外人類反饋的情況下,這種方法也顯著改進了Llama-3-8B-Instruct,並超越了依賴大量人類反饋的強基線方法自獎勵(Self-Rewarding)和SPPO。
此外,評估模型的評判能力時,它在與人類評判和強大的AI評判(如 gpt-4-1106-preview)的相關性上表現出顯著的改進。
總體而言,研究結果提供了有力的證據,證明無需任何人類反饋的自我改進模型是實現超級對齊(super alignment)的一個有前途的方向。
參考資料:
https://arxiv.org/pdf/2407.19594
本文來自微信公眾號「新智元」,作者:新智元,36氪經授權發佈。



















