錯誤率從10%降至0.01%,領英全面分享LLM應用落地經驗
選自LinkedIn
作者:Juan Pablo Bottaro、Karthik Ramgopal
機器之心編譯
機器之心編輯部
隨著大型語言模型(LLM)技術日漸成熟,各行各業加快了 LLM 應用落地的步伐。為了改進 LLM 的實際應用效果,業界做出了諸多努力。
近期,領英(LinkedIn)團隊分享了他們在構建生成式 AI 產品的過程中總結的寶貴經驗。領英表示基於生成式人工智能構建產品並非一帆風順,他們在很多地方都遇到了困難。
以下是領英博客原文。
過去六個月,我們 LinkedIn 團隊一直在努力開發一種新的人工智能體驗,試圖重新構想我們的會員如何進行求職和瀏覽專業內容。
生成式人工智能的爆髮式增長讓我們停下來思考,一年前不可能實現的事情現在有了哪些可能。我們嘗試了很多想法,但都沒有成功,最終發現產品需要如下關鍵點:
-
更快地獲取信息,例如從帖子中獲取要點或瞭解公司最新動態。
-
將信息點連接起來,例如評估您是否適合某個職位。
-
獲取建議,例如改善您的個人資料或準備面試。
-
……
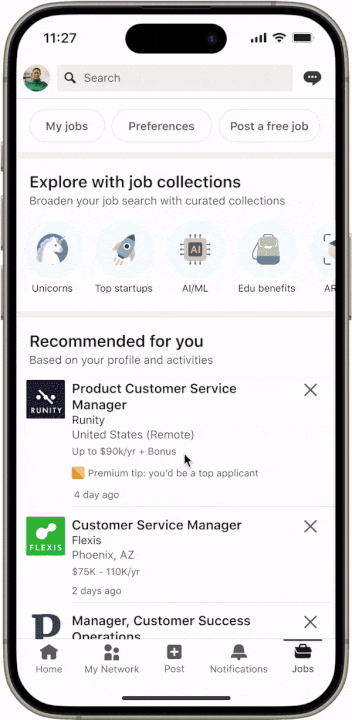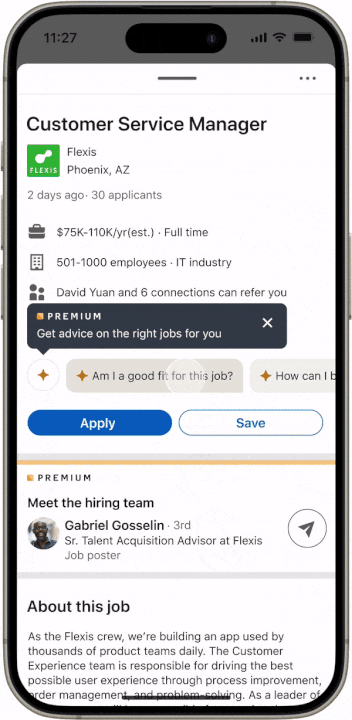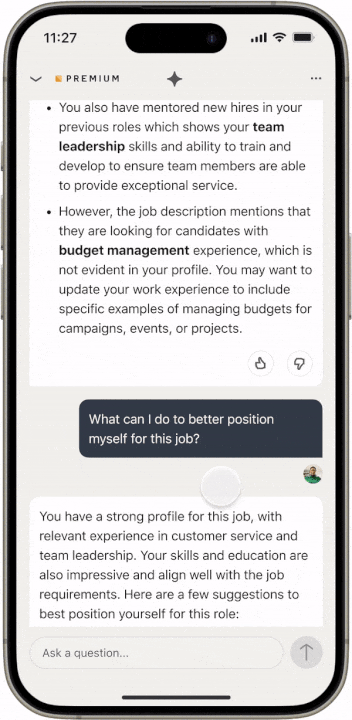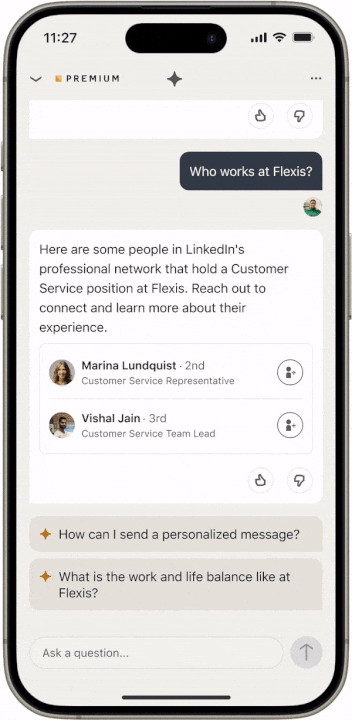
我們通過一個現實場景來展示新開發的系統是如何工作的。想像一下,您正在滾動瀏覽 LinkedIn 信息流,偶然發現了一篇關於設計中的可訪問性的有趣帖子。除了這篇文章之外,您還會刷到一些入門問題,以便更深入地研究該主題,您很好奇,例如點擊「科技公司中可訪問性推動商業價值的例子有哪些?」
系統後台會發生如下操作:
-
選擇合適的智能體:系統會接受您的問題並決定哪個 AI 智能體最適合處理它。在這種情況下,它會識別您對科技公司內部可訪問性的興趣,並將您的查詢路由到專門執行通用知識搜索的 AI 智能體。
-
收集信息:AI 智能體調用內部 API 和 Bing 的組合,搜索具體示例和案例研究,突出設計的可訪問性如何為技術領域的商業價值做出貢獻。
-
製定回覆:有了必要的信息,智能體現在可以撰寫回覆。它將數據過濾併合成為連貫、信息豐富的答案,為您提供清晰的示例,說明可訪問性計劃如何為科技公司帶來商業價值。為了使體驗更具交互性,系統會調用內部 API 來使用文章鏈接或帖子中提到的人員簡介等附件。
你可能會提問「我如何將我的職業生涯轉向這個領域」,那麼系統會重覆上述過程,但現在會將你轉給職業和工作(career and job)AI 智能體。只需點擊幾下,您就可以深入研究任何主題,獲得可行的見解或找到下一個工作機會。
大部分新功能是借助 LLM 技術才成為可能。
總體設計
系統 pipeline 遵循檢索增強生成(RAG),這是生成式人工智能系統的常見設計模式。令人驚訝的是,建設 pipeline 並沒有我們預期的那麼令人頭疼。在短短幾天內,我們就建立並運行了基本框架:
-
路由:決定查詢是否在範圍內,以及將其轉發給哪個 AI 智能體。
-
檢索:面向 recall 的步驟,AI 智能體決定調用哪些服務以及如何調用(例如 LinkedIn 人物搜索、Bing API 等)。
-
生成:面向精度的步驟,篩選檢索到的噪聲數據,對其進行過濾並生成最終響應。

圖 1:處理用戶查詢的簡化 pipeline。KSA 代表「知識共享智能體」,是數十種可以處理用戶查詢的智能體之一。
關鍵設計包括:
-
固定三步 pipeline;
-
用於路由 / 檢索的小型模型,用於生成的較大模型;
-
基於嵌入的檢索 (EBR),由內存數據庫提供支持,將響應示例直接注入到提示(prompt)中;
-
每步特定的評估 pipeline,特別是對於路由 / 檢索。
開發速度
我們決定將開發任務拆分為由不同人員開發獨立智能體:常識、工作評估、職位要點等。
通過並行化開發任務,我們提高了開發速度,但這是以「碎片」為代價的。當與通過不同的模型、提示或工具進行管理的助手(assistant)進行後續交互時,保持統一的用戶體驗變得具有挑戰性。
為瞭解決這個問題,我們採用了一個簡單的組織結構:
一個小型「水平(horizontal)」工程 pod,處理通用組件並專注於整體體驗,其中包括:
-
託管產品的服務
-
評估 / 測試工具
-
所有垂直領域使用的全局提示模板(例如智能體的全局身份(identity)、對話歷史、越獄防禦等)
-
為 iOS/Android/Web 客戶端共享 UX 組件
-
服務器驅動的 UI 框架,用於發佈新的 UI 更改,而無需更改或發佈客戶端代碼。
關鍵設計包括:
-
分而治之,但限制智能體數量;
-
具有多輪對話的集中式評估 pipeline;
-
共享提示模板(例如「身份(identity)」定義)、UX 模板、工具和檢測
評估
事實證明,評估響應的質量比預期的更加困難。這些挑戰可大致分為三個領域:製定指南(guideline)、擴展註釋和自動評估。
製定 guideline 是第一個障礙。以工作評估為例:點擊「評估我是否適合這份工作」並得到「你非常適合」並沒有多大用處。我們希望響應既真實又富有同理心。一些用戶可能正在考慮轉行到他們目前不太適合的領域,並需要幫助瞭解差距和後續步驟。確保這些細節一致對註釋器非常關鍵。
擴展註釋是第二步。我們需要一致和多樣化的註釋器。我們內部的語言學家團隊構建了工具和流程,以評估多達 500 個日常對話並獲取相關指標:整體質量得分、幻覺率、AI 違規、連貫性、風格等。
自動評估工作目前仍在進行中。如果沒有自動評估,工程師只能目測結果並在一組有限的示例上進行測試,並且要延遲 1 天以上才能瞭解指標。我們正在構建基於模型的評估器來評估上述指標,並努力在幻覺檢測方面取得一些成功,端到端自動評估 pipeline 將實現更快的迭代。

圖 2:評估步驟。
調用內部 API
LinkedIn 擁有大量有關人員、公司、技能、課程等的獨特數據,這些數據對於構建提供差異化價值的產品至關重要。然而,LLM 尚未接受過這些信息的訓練,因此無法使用它們進行推理和生成響應。解決此問題的標準模式是設置檢索增強生成 (RAG) pipeline,通過該 pipeline 調用內部 API,並將其響應注入到後續的 LLM 提示中,以提供額外的上下文來支持響應。
許多此類數據通過各種微服務中的 RPC API 在內部公開。雖然這對於人類以編程方式調用非常方便,但對 LLM 來說並不友好。我們通過圍繞這些 API 包裝「技能」來解決這個問題。每個技能都有以下組件:
-
關於 API 的功能以及何時使用的人類友好描述
-
調用 RPC API 的配置(端點、輸入模式、輸出模式等)
-
LLM 友好的輸入和輸出模式
-
原始類型(字符串 / 布爾 / 數字)值
-
JSON 模式的輸入和輸出模式描述
-
LLM 友好模式和實際 RPC 模式之間映射的業務邏輯
這些技能旨在讓 LLM 能夠執行與產品相關的各種操作,例如查看個人資料、搜索文章 / 人員 / 職位 / 公司,甚至查詢內部分析系統。同樣的技術也用於調用非 LinkedIn API,例如 Bing 搜索。
 圖 3:使用技能調用內部 API。
圖 3:使用技能調用內部 API。我們編寫提示,要求 LLM 決定使用什麼技能來解決特定的工作(通過規劃選擇技能),然後輸出參數來調用技能(函數調用)。由於調用的參數必須與輸入模式匹配,因此我們要求 LLM 以結構化方式輸出它們。大多數 LLM 都接受過用於結構化輸出的 YAML 和 JSON 訓練。我們選擇 YAML 是因為它不太冗長,因此比 JSON 消耗更少的 token。
我們遇到的挑戰之一是,雖然大約 90% 的情況下,LLM 響應包含正確格式的參數,但大約 10% 的情況下,LLM 會出錯,並且經常輸出格式無效的數據,或者更糟糕的是甚至不是有效的 YAML。
這些錯誤對人類來說是微不足道的,但卻會導致解析它們的代碼崩潰。10% 是一個足夠高的數字,我們不能輕易忽視,因此我們著手解決這個問題。
解決此問題的標準方法是檢測它,然後重新提示 LLM 要求其糾正錯誤並提供一些額外的指導。雖然這種方法有效,但它增加了相當大的延遲,並且由於額外的 LLM 調用而消耗了寶貴的 GPU 容量。為了規避這些限制,我們最終編寫了一個內部防禦性 YAML 解析器。
通過對各種有效負載的分析,我們確定了 LLM 所犯的常見錯誤,並編寫了代碼以在解析之前適當地檢測和修補(patch)這些錯誤。我們還修改了提示,針對其中一些常見錯誤注入提示,以提高修補的準確率。我們最終能夠將這些錯誤的發生率減少到約 0.01%。
我們目前正在構建一個統一的技能註冊表,用於在我們的生成式人工智能產品中,動態發現和調用打包為 LLM 友好技能的 API / 智能體。
容量和延遲
容量和延遲始終是首要考慮因素,這裏提及一些考量維度:
-
質量與延遲:思想鏈 (CoT) 等技術對於提高質量和減少幻覺非常有效,但需要從未見過的 token,因此增加了延遲。
-
吞吐量與延遲:運行大型生成模型時,通常會出現 TimeToFirstToken (湯臣FT) 和 TimeBetweenTokens (TBT) 隨著利用率的增加而增加的情況。
-
成本:GPU 集群不易獲得且成本高昂。一開始我們甚至必須設定測試產品的時間表,因為會消耗太多 token。
-
端到端流式處理(streaming):完整的答案可能需要幾分鐘才能完成,因此我們流式處理所有請求,以減少感知延遲。更重要的是,我們實際上在 pipeline 中端到端地進行流式處理。例如,決定調用哪些 API 的 LLM 響應是逐步解析的,一旦參數準備好,就會觸發 API 調用,而無需等待完整的 LLM 響應。最終的綜合響應也會使用實時消息傳遞基礎設施一路傳輸到客戶端,並根據「負責任的 AI」等進行增量處理。
-
異步非阻塞 pipeline:由於 LLM 調用可能需要很長時間才能處理,因此我們通過構建完全異步非阻塞 pipeline 來優化服務吞吐量,該 pipeline 不會因 I/O 線程阻塞而浪費資源。

感興趣的讀者可以閱讀博客原文,瞭解更多研究內容。
原文鏈接:https://www.linkedin.com/blog/engineering/generative-ai/musings-on-building-a-generative-ai-product