不花一分錢!GPT-4o微調限時免費開放,每日附贈百萬訓練token
一水 發自 凹非寺
量子位 | 公眾號 QbitAI
一覺醒來,OpenAI又上新功能了:
GPT-4o正式上線微調功能。
並且官方還附贈一波福利:每個組織每天都能免費獲得100萬個訓練token,用到9月23日。

也就是說,開發人員現在可以使用自定義數據集微調GPT-4o,從而低成本構建自己的應用程序。
要知道,OpenAI在公告中透露了:
GPT-4o微調訓練成本為每100萬token 25 美元(意味著每天都能節省25美元)
收到郵件的開發者們激動地奔走相告,這麼大的羊毛一定要趕快薅。

使用方法也很簡單,直接訪問微調儀表盤,點擊」create」,然後從基本模型下拉列表中選擇gpt-4o-2024-08-06。

對了,OpenAI還提到,只需訓練數據集中的幾十個示例就可以產生良好效果。

還曬出了成功案例
消息公佈後,一眾網民躍躍欲試,表示很想知道模型微調後的實際效果。

OpenAI官方早有準備,隨公告一同發佈了合作夥伴微調GPT-4o的實際案例。
首先是一款代碼助手Genie,來自AI初創公司Cosine,專為協助軟件開發人員而設計。
據Cosine官方介紹,Genie的開發過程採用了一種專有流程,使用數十億個高質量數據對非公開的GPT-4o變體進行了訓練和微調。
這些數據包括21%的JavaScript和Python、14%的TypeScript和TSX,以及3%的其他語言(包括Java、C++和Ruby)。
經過微調,Genie在上週二OpenAI全新發佈的代碼能力基準測試SWE-Bench Verified上,取得了43.8%的SOTA分數。
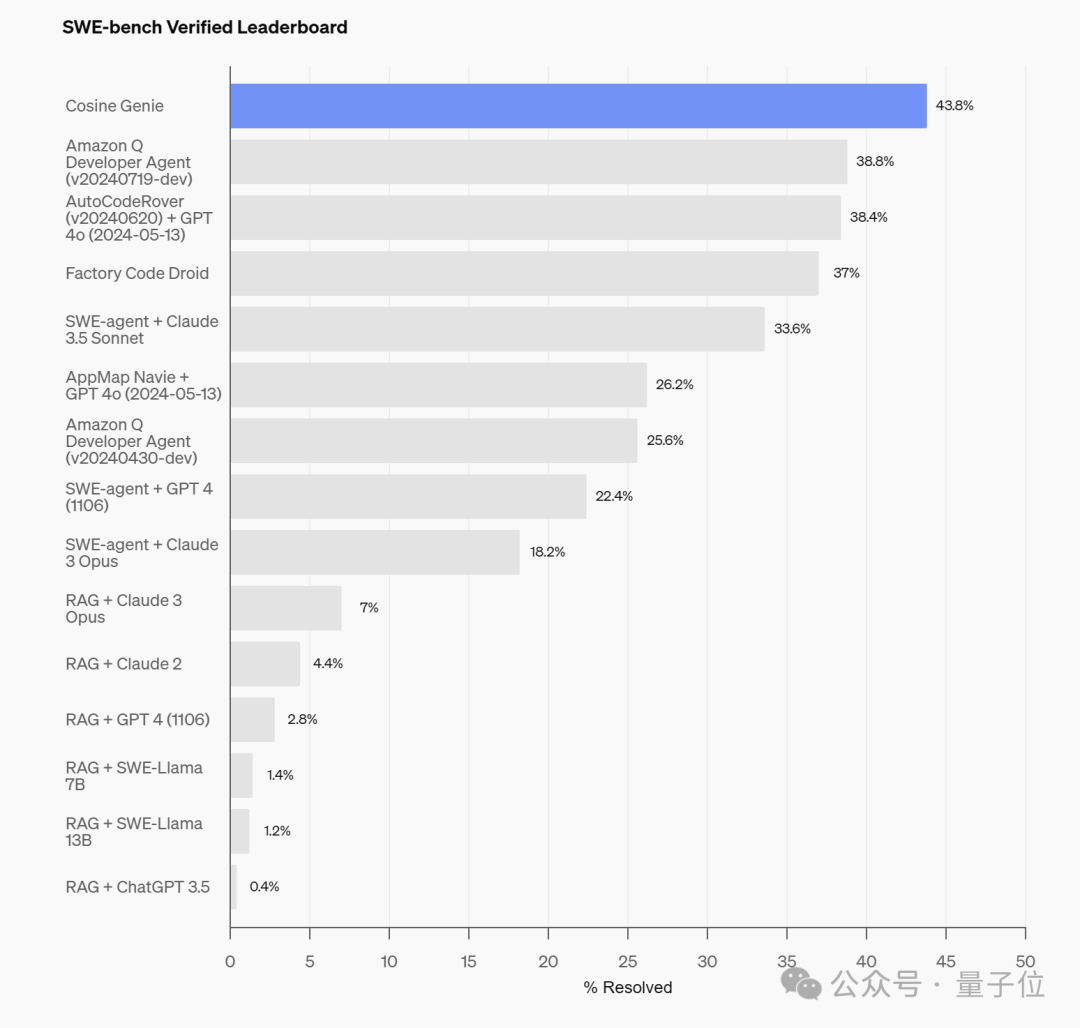
與此同時,Genie還在SWE-Bench Full上的SOTA分數達到了30.08%,破了之前19.27%的SOTA紀錄。
相較之下,Cognition的Devin在SWE-Bench的部分測試中為13.8%。
另一個案例來自Distyl,這是一家為財富500強企業提供AI解決方案的公司,最近在領先的文本到SQL基準測試BIRD-SQL中排名第一。
經過微調,其模型在排行榜上實現了71.83%的執行準確率,並在查詢重構、意圖分類、思維鏈和自我糾正等任務中表現出色,尤其是在SQL生成方面表現尤為突出。

除了提供案例,OpenAI還在公告中特意強調了數據隱私和安全問題,總結下來就是:
開發者的業務數據(包括輸入和輸出)不會被共享或用於訓練其他模型。
針對微調模型實施了分層安全緩解措施,例如不斷對微調模型運行自動安全評估並監控使用情況。

網民:微調比不上提示詞緩存
一片熱鬧之際,有網民認為微調仍然比不上提示詞緩存。
微調很酷,但它仍然不如提示詞緩存……

之前量子位也介紹過,提示詞緩存的作用,就是一次給模型發送大量prompt,然後讓它記住這些內容,並在後續請求中直接複用,避免反復輸入。
今年5月,Google的Gemini就已經支持了提示詞緩存,Claude也在上週上新了這項功能。
由於不需要反復輸入重覆的腳本,提示詞緩存具有速度更快、成本更低這兩大優勢。
有網民認為,提示詞緩存功能對開發者更友好(無需異步微調),且幾乎可以獲得與微調相同的好處。
提示詞緩存可以讓您付出1%的努力獲得99%的好處。

不過也有人給微調打call,認為微調在塑造響應方面更有效。例如確保JSON格式正確、響應更簡潔或使用表情符號等。

眼見OpenAI的競爭對手們相繼用上了提示詞緩存,還有人好奇了:
想知道OpenAI是否會堅持微調或轉向提示詞緩存(或兩者兼而有之)。
對於這個問題,有其他網民也嗅出了一些蛛絲馬跡。
OpenAI在其延遲優化指南中提到了緩存技術。
我們也第一時間找了下指南原文,其中在談到如何減少輸入token時提到:
通過在提示中稍後放置動態部分(例如RAG結果、歷史記錄等),最大化共享提示前綴。這使得您的請求對KV緩存更加友好,意味著每個請求處理的輸入token更少。

不過有網民認為,僅根據這一段內容,無法直接推出OpenAI採用了提示詞緩存技術。
BTY,拋開爭議不談,OpenAI的羊毛還是得薅起來~
除了GPT-4o,還可以免費微調GPT-4o mini,9月23日之前OpenAI免費提供每天200萬個訓練token。

參考鏈接:
[1]https://openai.com/index/gpt-4o-fine-tuning/
[2]https://x.com/OpenAIDevs/status/1825938486568038569
[3]https://news.ycombinator.com/item?id=41301673



















