Deepseek AI 模型升級推出 2.5 版:合併 Coder 和 Chat,對齊人類偏好、優化寫作任務和指令跟隨等
IT之家 9 月 6 日消息,DeepSeek Coder V2 和 DeepSeek V2 Chat 兩個模型已經合併升級,升級後的新模型為 DeepSeek V2.5。
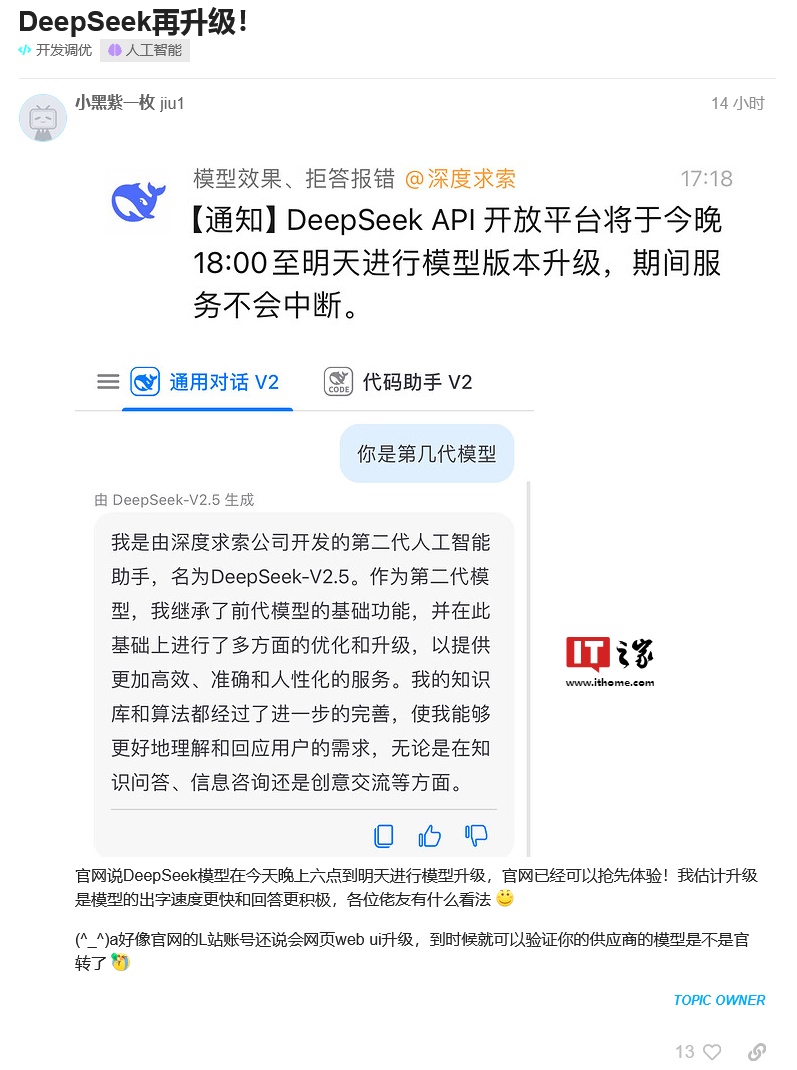 圖源:Linux.do 論壇網民截圖
圖源:Linux.do 論壇網民截圖DeepSeek 官方昨日(9 月 5 日)更新 API 支持文檔,宣佈合併 DeepSeek Coder V2 和 DeepSeek V2 Chat 兩個模型,升級推出全新的 DeepSeek V2.5 新模型。
官方表示為向前兼容,API 用戶通過 deepseek-coder 或 deepseek-chat 均可以訪問新的模型。
新模型在通用能力、代碼能力上,都顯著超過了舊版本的兩個模型。
新模型更好地對齊了人類的偏好,在寫作任務、指令跟隨等多方面進行了優化:
-
ArenaHard winrate 從 68.3% 提升至 76.3%
-
AlpacaEval 2.0 LC winrate 從 46.61% 提升至 50.52%
-
MT-Bench 分數從 8.84 提升至 9.02
-
AlignBench 分數從 7.88 提升至 8.04
新模型在原 Coder 模型的基礎上進一步提升了代碼生成能力,對常見編程應用場景進行了優化,並在標準測試集上取得了以下成績:
-
HumanEval: 89%
-
LiveCodeBench (1-9 月): 41%
IT之家註:Deepseek AI 模型由杭州深度求索人工智能推出,該公司成立於 2023 年。

官方介紹如下:
專注於研究世界領先的通用人工智能底層模型與技術,挑戰人工智能前沿性難題。基於自研訓練框架、自建智算集群和萬卡算力等資源,DeepSeek(深度求索)團隊僅用半年時間便已發佈並開源多個百億級參數大模型,如 DeepSeek-LLM 通用大語言模型、DeepSeek-Coder 代碼大模型,並且在 2024 年 1 月率先開源國內首個 MoE 大模型(DeepSeek-MoE),各大模型在公開評測榜單及真實樣本外的泛化效果均有超越同級別模型的出色表現。
廣告聲明:文內含有的對外跳轉鏈接(包括不限於超鏈接、二維碼、口令等形式),用於傳遞更多信息,節省甄選時間,結果僅供參考,IT之家所有文章均包含本聲明。



















