OpenAI發佈全新o1模型:它會像人類一樣「深思熟慮」
沒有一點點防備,OpenAI造勢已久的「草莓」(Strawberry)模型,就這樣發佈了。
 o1模型的介紹切片,來源:OpenAI
o1模型的介紹切片,來源:OpenAI香港時間今天淩晨,OpenAI發佈了名為OpenAI o1的新模型,也是之前所傳的「Strawberry」,但最初o1的代號為「Q*」。OpenAI的CEO薩姆·奧爾特曼(Sam Altman)則稱它為「新範式的開始」。
從OpenAI的官方信息看下來,總結o1的特點就是:更大、更強、更慢、更貴。
經過強化學習(Reinforcement Learning),OpenAI o1在推理能力方面取得了重大進展。研發團隊觀察到,隨著訓練時間(強化學習的增加)和思考時間(測試時的計算)的延長,o1模型的表現逐漸提升。這種方法的擴展所面臨的挑戰與大型語言模型(LLM)的預訓練限制截然不同。
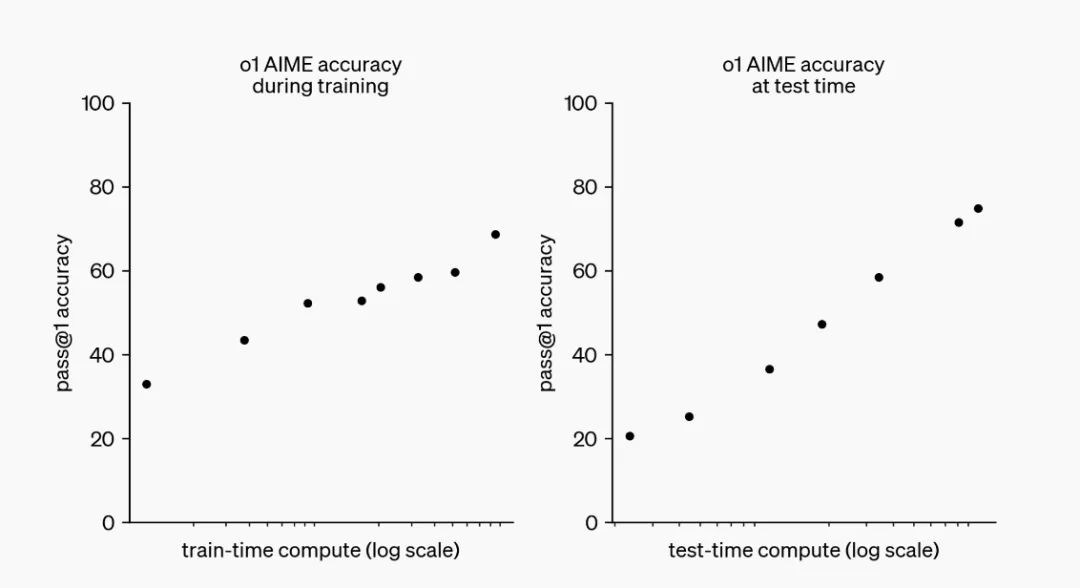 o1性能隨著訓練時間和測試時間計算而平穩提升,來源:OpenAI
o1性能隨著訓練時間和測試時間計算而平穩提升,來源:OpenAI關於市面上所傳「o1模型能夠自主為用戶執行瀏覽器或系統操作級別的任務」,目前的公開信息並未提及這一功能。
OpenAI官方表示:「雖然這款初期模型還沒有像網上搜索信息、上傳文件和圖片這樣的功能,但它在解決複雜推理問題上有了顯著進步,這代表了人工智能技術的新水平。所以我們決定給這個系列一個新的起點,將其命名為OpenAI o1。」由此可見,o1的主要應用還是集中在通過文本交互進行問題解答和分析,而不是直接控制瀏覽器或操作系統。
與早期版本不同,o1模型在作出回答之前會像人類一樣「深思熟慮」,用時約10—20秒,產生一個長長的內部思路鏈,並能夠嘗試不同的策略並識別自身的錯誤。
這種強大推理能力使o1在多個行業中具有廣泛的應用潛力,尤其是複雜的科學、數學和編程任務。在處理物理、化學和生物問題時,o1的表現甚至和該領域的博士生水平不相上下。在國際數學奧林匹克的資格考試(AIME)中,o1的正確率為83%,成功進入了美國前500名學生的行列,而GPT-4o模型的正確率僅為13%。
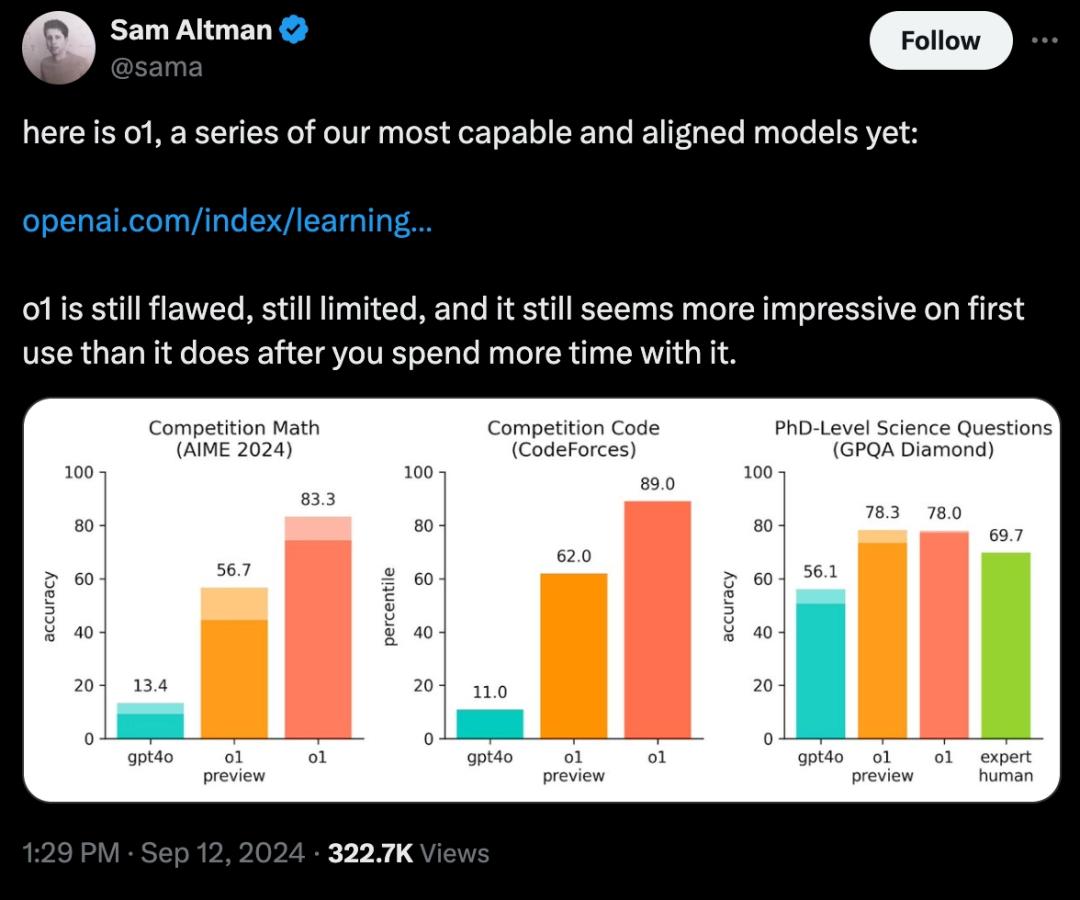 奧爾特曼也在X上分享了o1,來源:X
奧爾特曼也在X上分享了o1,來源:XOpenAI提供了一些具體的使用案例,比如醫療研究人員可利o1來標註細胞測序數據;物理學家可用o1生成量子光學所需的複雜數學公式;軟件開發者則可以借助它來構建和執行複雜的多步驟工作流程等。
o1系列分包含三款模型,OpenAI o1、OpenAI o1-preview和OpenAI o1-mini。這兩款模型從今天開始對用戶開放使用:
OpenAI o1:高級推理模型,暫不對外開放。
OpenAI o1-preview:這個版本更注重深度推理處理,每週可以使用30次。
OpenAI o1-mini:這個版本更高效、划算,適用於編碼任務,每週可以使用50次。
開發者和研究人員現在可以通過ChatGPT和應用程序編程接口訪問這些模型。
至於價格,早先The information曾爆料,OpenAI高管正在討論其即將推出的全新大模型「草莓」(Strawberry)和「獵戶座」(Orion)的擬定在2000美元一個月,引發一眾「抽水」和聲討。但今日有人發現,ChatGPT Pro會員已經上線了,售價200美元/月。從2000美元到200美元的落差,很難讓人不產生一種「佔便宜」的感覺,價格心理戰被OpenAI玩轉得明明白白。
今年5月,奧爾特曼在於麻省理工學院校長莎莉·高漢布魯斯(Sally Kornbluth)爐邊談話中曾提到,GPT-5或將數據與推理引擎分離。
「GPT-5或GPT-6可以成為最佳的推理引擎,目前而言,能達到最佳引擎的唯一路徑就是訓練大量的數據。」奧爾特曼認為,但實際上,模型在處理數據時浪費了許多數據資源。比如GPT-4。它也能像數據庫一樣工作,只是推理速度慢、成本高昂且效果「不盡如人意」。這些問題本質上是因為模型的設計和訓練方式導致的資源浪費。
「不可避免的,這是我們製作推理引擎模型的唯一方法的副作用。」他所能預見未來的新方法,就是將模型的推理能力與對大數據的需求性剝離。
但在今天的發佈中,GPT-5沒有出現,數據與推理引擎分離這一設想也不見蹤影。
至於價格,早先The information曾爆料,OpenAI高管擬將推出的全新大模型「草莓」(Strawberry)和「獵戶座」(Orion)的價格定在2000美元/月,這引發一眾「抽水」和聲討。但今日有人發現,ChatGPT Pro會員已經上線了,售價為200美元/月。
從2000美元到200美元的落差,很難不讓用戶產生一種「佔便宜」的感覺,價格心理戰實屬被OpenAI玩轉得明明白白。
1.打磨「思維鏈」
大模型一直因其「不會數數」而被詬病。究其根本,是因為大模型缺乏結構化推理的能力。
推理是人類智能的核心能力之一。而大模型主要通過非結構化的文本數據進行訓練,這種數據通常包括新聞文章、書籍、網頁文本等。文本是自然語言形式,不遵循嚴格的邏輯或結構化規則,所以模型學到的也主要是如何根據上下文生成語言,而不是如何邏輯推理或遵循固定的規則處理信息。
但許多複雜推理任務都是結構化的。
比如邏輯推斷、數學問題解決或編程等。如果我們想要走出一個迷宮,就需要遵循一系列邏輯和空間規則才能找到出口。這類問題要求模型能夠理解並應用一系列固定的步驟或規則,但這正是大部分大模型所缺乏的。
所以,像ChatGPT、BARD等模型雖能根據訓練數據生成看似合理的回答,其實更像是「隨即鸚鵡」(stochastic parroting),它們往往無法真正理解背後的複雜邏輯或執行高級推理任務。
要知道,大模型在處理非結構化的自然語言文本時表現出色,原於這正是訓練數據的側重點。但當涉及到需要結構化邏輯推理的任務時,它們往往難以表現得像人類一樣精確。
為解決這一難題,OpenAI想到了用思維鏈(Chain of Thought, CoT)來「破局」。
思維鏈是一種幫助AI模型進行推理的技術。它通過讓模型在回答覆雜問題時,逐步解釋每一步的推理過程,而不是直接給出答案。因此模型在回答問題時就像是人類在解題時那樣,先思考每一步的邏輯,再逐步推導出最終的結果。
但在AI訓練的過程中,人工標註思維鏈耗時又昂貴,在scaling law主導下所需的數據量對人工而言基本是一項不可能完成的任務。
這時,強化學習就成了更實用的替代方案。
強化學習可以讓模型通過實踐和試錯自己學習,它不需要人工標註具體每一步怎麼走,而是通過不斷的實驗和反饋來優化解決問題的方法。
具體來說,就是模型在嘗試解決問題的過程中,根據所採取行動的結果(好的或壞的)來調整自己的行為。這樣,模型能夠自主探索多種可能的解決方案,並通過不斷試錯找到最有效的方法。比如在遊戲或模擬環境中,AI可以通過自我對弈不斷優化策略,最終學會如何精確執行複雜任務,而無需人工逐一指導每一步。
比如2016年橫掃圍棋界的AlphaGo,它就是結合了深度學習和強化學習的方法,通過大量的自我對弈來不斷優化其決策模型,最終能夠戰勝世界頂級的圍棋選手李世石。
o1模型就是用和AlphaGo「同門」的方法逐步處理問題。
在這個過程中,o1通過強化學習不斷完善自己的思考過程,學會識別和糾正錯誤,將複雜步驟分解為更簡單的部分,並在遇到障礙時嘗試新的方法。這種訓練方式顯著提升了o1的推理能力,讓o1能夠更有效地解決問題。
OpenAI的聯合創始人之一格雷格·布羅克曼(Greg Brockman)對此感到「十分自豪」,「這是我們首次使用強化學習訓練的模型。」他說道。
 布羅克曼的推文切片,來源:X
布羅克曼的推文切片,來源:X布羅克曼介紹,OpenAI的模型原先進行的是系統一型思維(快速、直觀的決策)而思維鏈技術則啟動了系統二型思維(慎重、分析性的思考)。
系統一型思維適合快速應對,而系統二型思維則通過「思維鏈」技術,讓模型能夠逐步推理解決問題。實踐表明,通過持續的試錯,從頭到尾完整訓練模型(如在圍棋或Dota等遊戲中應用),可以極大提升模型的表現。
此外,o1技術雖然仍在開發初期,但已在安全性方面表現良好。如通過增強模型對策略進行深入推理來提高其對抗攻擊的魯棒性和降低幻覺現象的風險。這種深層次的推理能力已經開始在安全性評估中顯示出積極的效果。
「我們基於o1模型開發了一個新的模型,讓它參加了2024年國際信息學奧林匹克(IOI)比賽,並在49%的排名中得到了213分。」OpenAI方表示。
它在與人類參賽者相同的條件下參賽,解決六個算法問題,每個問題有50次提交機會。通過篩選多個候選方案並根據公開測試用例、模型生成的測試用例和評分函數來選擇提交方案,證明了其選擇策略的有效性,平均得分高於隨機提交的分數。
在提交次數放寬到每題10,000次時,模型表現得更好,得分超過了金牌標準。最後,這個模型在模擬的Codeforces編程比賽中展示了「令人驚歎」的編碼能力。GPT-4o的Elo等級為808,位於人類競爭者的第11百分位。而我們的新模型Elo等級為1807,表現優於93%的競爭者。
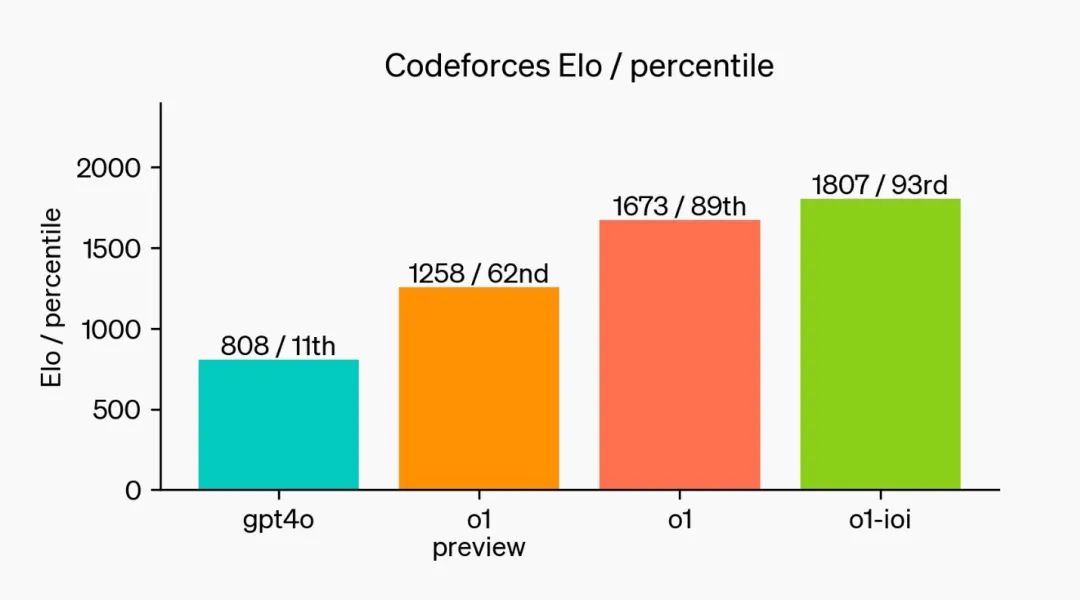 在編程競賽中進一步的微調提升了o1模型的表現,來源:OpenAI
在編程競賽中進一步的微調提升了o1模型的表現,來源:OpenAI2.「多事之秋」的OpenAI
在o1發佈前,OpenAI一直深陷公司核心高層變動的陰雲中。
今年2月,OpenAI的創始成員、研究科學家安達·卡帕斯(Andrej Karpathy)在X上宣佈,他已離開這家公司。卡帕斯表示,他友好地離開了OpenAI,「不是因為任何特定的事件、問題或戲劇性事件」。
前首席科學家、聯合創始人伊利亞·蘇茨克維(Ilya Sutskever)則在5月宣告離職,超級對齊團隊也隨之解散,業內認為這是OpenAI在追求技術突破和確保AI安全之間平衡的失敗嘗試。
 右起分別是伊利亞·蘇茨克維、格雷格·布洛克曼 (Greg Brockman)、山姆·奧爾特曼和米拉·穆拉蒂。來源:紐約時報
右起分別是伊利亞·蘇茨克維、格雷格·布洛克曼 (Greg Brockman)、山姆·奧爾特曼和米拉·穆拉蒂。來源:紐約時報在伊利亞發佈通告的數小時後,RLHF發明者之一、超級對齊團隊的共同主管簡·雷克(Jan Leike)也追隨他的腳步一起離開,再次給OpenAI的未來增加了更多的不確定性。
8月,OpenAI聯合創始人、研究科學家約翰·舒爾曼(John Schulman)透露了自己的離職,並加入Anthropic專注於AI對齊的深入研究。他解釋說,離職是為了聚焦於AI對齊和技術工作,並非因為OpenAI不支持對齊研究。舒爾曼感謝了在OpenAI的同事,並對它未來的發展「充滿信心」。
而Anthropic正是由2020年離職的OpenAI的研究副總裁達里奧·阿莫蒂(Dario Amodei) ,和時任安全與政策副總裁丹妮拉·阿莫蒂(Daniela Amodei)兄妹創辦的。
布羅克曼也在同月宣佈休假一年,這是他自9年前共同創立OpenAI以來的「第一次長假」。
9月10日,領導OpenAI GPT-4o和GPT-5模型音頻交互研究的亞曆西斯·克努亞(Alexis Conneau)宣佈離職並創業,克努亞的研究致力於實現電影《Her》中展示的那種自然語音交互體驗,但相關產品的發佈卻一再延遲。
OpenAI自成立以來,就因其非營利和商業化的雙重身份而備受關注。隨著商業化化進程的加速,內部關於其非營利使命的緊張關係日益明顯,這也是團隊成員流失的一個原因。同時埃隆·馬斯克(Elon Musk)最近的一起訴訟可能也與人員流失有關。
OpenAI研究員丹尼爾·高高塔洛(Daniel Kokotajlo)在離職後接受媒體專訪時表示,去年發生的「宮鬥」事件中,奧爾特曼被短暫解僱後迅速複職,專注於AGI安全的三名董事會成員被撤換。「這使得奧爾特曼和布羅克曼進一步鞏固了權力,而主要關注AGI安全的人被邊緣化。(奧爾特曼)他們背離了公司在2022年製定的計劃」。
此外,OpenAI面臨高達50億美元的預計虧損,運營成本高達85億美元,其中大部分為服務器租用和訓練成本。為應對高昂的運營壓力,OpenAI正在謀求新一輪融資,估值可能超過1000億美元,微軟、蘋果和英偉達等潛在投資者表達了興趣。公司高管正在全球範圍內尋求投資以支持其快速發展的資金需求。
為了緩解財務壓力,OpenAI正在尋求新一輪的融資,據《紐約時報》11日報導,OpenAI上週還希望以1000億美元估值融資大約10億美元。但因構建大型AI系統所需算力將導致更大開支,該公司近日決定調高融資額度到65億美元。
但有外媒援引知情人士以及未公開的內部財務數據分析稱,OpenAI今年可能面臨高達50億美元的巨額虧損,總運營成本預計達到85億美元。其中向微軟租用服務器的費用高達40億美元,數據訓練成本則是30億美元。由於更先進的模型如Strawberry和Orion的運行成本更高,公司的經濟壓力進一步加大。
本文來自微信公眾號「甲子光年」,作者:蘇霍伊,36氪經授權發佈。