Google推出 DataGemma:基於可信數據源提高 AI 準確度,減少幻覺
IT之家 9 月 13 日消息,科技媒體 maginative 昨日(9 月 12 日)發佈博文,報導Google公司基於Google數據共享(Data Commons)中的真實世界統計數據,推出了開放權重 Gemma 模型的新版本 DataGemma。

語言模型當前面臨的一大難題就是幻覺(Hallucinations),尤其是大語言模型(LLMs)在處理數值或統計數據時,這一問題變得尤為棘手,因此精確性至關重要。
Google的 Data Commons 是一個存儲庫,彙集了來自聯合國和疾病控制與預防中心等可信組織收集的超過 2400 億個數據點。
通過利用這一龐大的統計數據集,基於 Gemini 的 DataGemma 能夠顯著提升模型準確性,確保其輸出基於真實可信的現實世界信息。

DataGemma 方法的核心在於兩種關鍵技術:檢索交錯生成(RIG)和檢索增強生成(RAG)。這兩種方法通過在生成過程中將模型基於現實世界數據,從而減少幻覺現象。
IT之家簡要介紹兩項技術如下:
RIG:
通過主動查詢可信來源,再生成回答的方式運作。在接收到提示詞之後,DataGemma 會識別查詢中的統計數據點,並從數據共享平台獲取準確信息。

例如,若被問及「全球可再生能源的使用量是否有所增加?」,該模型會在回答中穿插實時統計數據,確保事實準確性。
RAG:
在生成回答之前,會從數據共享平台檢索相關信息,進一步提升了回答的質量。借助其長上下文窗口(由 Gemini 1.5 Pro 實現),DataGemma 確保了回答的全面性,引入了表格和腳註以提供更深層次的上下文,從而減少了虛構內容的出現。
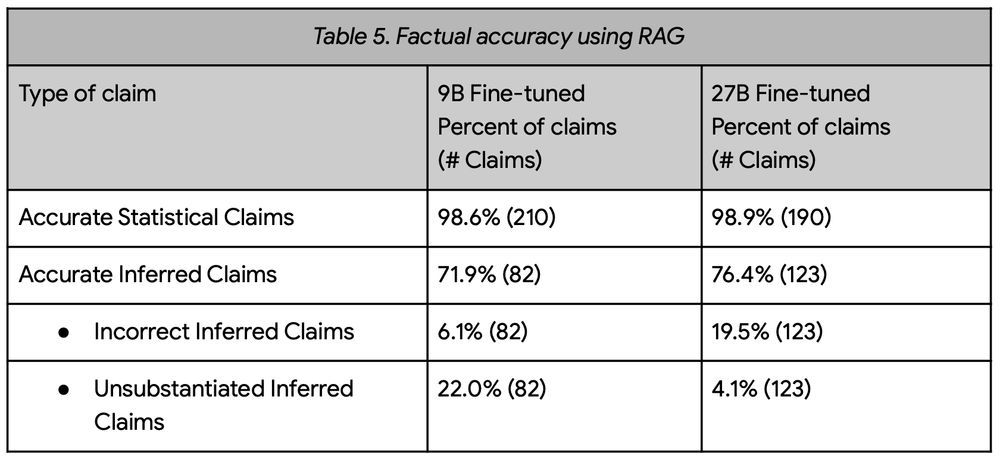
Google對 RIG 和 RAG 的研究尚處於初期階段,但初步成果令人鼓舞。通過將現實世界數據嵌入回覆中,DataGemma 模型在處理數值事實和統計查詢方面展現出顯著提升。研究團隊已發表論文詳述其方法,強調這些技術如何幫助 LLMs 判斷何時依賴外部數據與內部參數。
廣告聲明:文內含有的對外跳轉鏈接(包括不限於超鏈接、二維碼、口令等形式),用於傳遞更多信息,節省甄選時間,結果僅供參考,IT之家所有文章均包含本聲明。