阿里8B模型拿下多頁文檔理解新SOTA,324個視覺token表示一頁,縮減80%
mPLUG團隊 投稿
量子位 | 公眾號 QbitAI
高效多頁文檔理解,阿裡通義實驗室mPLUG團隊拿下新SOTA。
最新多模態大模型mPLUG-DocOwl 2,僅以324個視覺token表示單個文檔圖片,在多個多頁文檔問答Benchmark上超越此前SOTA結果。

並且在A100-80G單卡條件下,做到解像度為1653×2339的文檔圖片一次性最多支持輸入60頁!
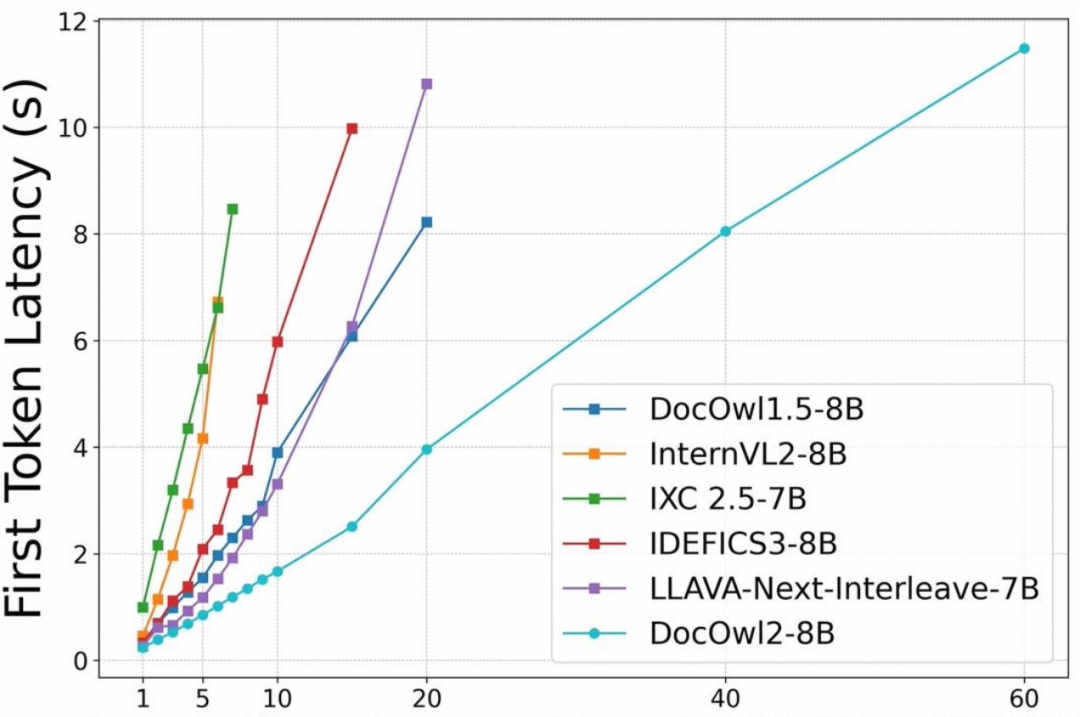 △單個A100-80G最多能支持文檔圖片(解像度=1653×2339)的數量以及首包時間
△單個A100-80G最多能支持文檔圖片(解像度=1653×2339)的數量以及首包時間mPLUG-DocOwl是利用多模態大模型進行OCR-free文檔理解的一系列前沿探索工作。
-
DocOwl 1.0首次提出基於多模態大模型進行文檔理解方面的多任務指令微調;
-
UReader首次提出利用切圖的策略來處理高清文檔圖片,成為目前高清圖片理解的主流方案;
-
DocOwl 1.5提出統一結構學習,將多個bechmark的開源效果提升超過10個點,成為多模態大模型在文檔理解方面的主要對比基準。
隨著文檔圖片的解像度以及切圖數量的不斷增加,開源多模態大模型的文檔理解性能有了顯著提升,然而這也導致視覺特徵在大模型解碼時佔用了過多的視覺token,造成了過高的顯存佔用以及過長的首包時間。
主流模型在編碼時一般動輒需要上千視覺token,才能還原所有細節。這導致每張A100-80G只能塞7張左右的文檔圖,嚴重影響AI文檔理解的效果和成本。
作為mPLUG-DocOwl系列的最新迭代,DocOwl 2在模型結構和訓練策略上做出大膽創新:
-
在結構上,僅用324個視覺token表示每頁高清文檔圖片,大幅節省顯存、降低首包時間。
-
在訓練上,採用三階段訓練框架,兼顧多頁和單頁文檔問答效果,具備多頁文字識別、多頁文檔結構解析以及帶有相關頁碼的詳細解釋能力。
模型結構
文檔圖片相比一般圖片之所以顯著消耗更多視覺token,主要是為了編碼圖片中所有的文字信息。
考慮到目前所有的多模態大模型都會將視覺特徵對齊到文本空間,且自然語言處理領域相關研究已經證明文本信息可以顯著壓縮並保留住絕大部分語義,作者認為高清文檔圖片的視覺token在和LLM對齊後同樣可以進行較大程度的壓縮同時保留住絕大部分佈局信息和文字信息。
文檔圖片中,同一個佈局區域的文字因為語義連貫,更容易進行歸納總結。引入佈局信息進行壓縮指導可以降低壓縮難度,減少信息丟失。
恰好,當一張高清文檔圖片降采樣為低解像度全局圖後,文字信息丟失但是佈局信息仍得以保留。
因此在只使用一個低解像度視覺編碼器的情況下,DocOwl 2提出在視覺文本對齊之後增加一個High-resolution DocCompressor,其使用低解像度的全局圖作為壓縮指導,使用切圖的高解像度特徵作為壓縮對象,僅通過兩層cross attention,將切圖的高解像度特徵壓縮為324個token。
 △圖2: DocOwl 2模型結構圖
△圖2: DocOwl 2模型結構圖DocOwl 2整體延續了DocOwl 1.5的結構,主要包括高解像度視覺編碼,高解像度壓縮以及語言模型多模態理解三個部分。
對於一篇多頁文檔,每一頁會獨立進行高解像度視覺編碼和高解像度壓縮。
具體來說,每一頁文檔圖片會採用Shape-adaptive Cropping模塊在考慮形狀和大小的情況下找到一個做合適的切割方式進行切片,同時將原圖放縮為一個低解像度全局圖。隨後每個切片和全局圖會單獨經過ViT提取視覺特徵特徵,以及H-Reducer水平合併4個特徵並將緯度對齊到LLM。之後,DocOwl2會採用High-resolution DocCompressor對視覺特徵進行壓縮。
低解像度的全局圖片特徵作為壓縮指導(query),以高解像度切片特徵作為壓縮對象(key/value),DocCompressor由兩層cross-attention layer組成。
考慮到切片過程中佈局信息被破壞,多個切片的特徵圖首先會按照切片在原圖中位置進行拚接重組。由於低解像度全局圖片的每一個特徵只編碼了部分區域的佈局信息,如果讓每個低解像度特徵都關注所有高解像度特徵不僅增加壓縮難度,而且大大增加了計算複雜度。
因此,針對全局圖的每一個視覺特徵,根據其在原圖中的相對位置,從重組後的切片特徵中可以挑選出同一位置的一組高清特徵,其數量和切片的數量一致,並可能來自多個切片。
經過壓縮後,任意形狀的文檔圖片的token數量都等同於低解像度全局圖的token數量。DocOwl2的單個切片以及全局圖片都採用了504×504的解像度,因此,最終單個文檔圖片的token數量為(504×504)/(14×14)/4=324個。
DocCompressor添加在已有多模態大模型的對齊結構之後,並不需要對其他結構做修改,這篇工作中,作者以DocOwl 1.5作為主要結構,但理論上,其適用於目前所有的高解像度多模態大模型,例如InternVL2或Qwen2-VL。
模型訓練:單頁多頁分開預訓練
DocOwl 2的訓練由三個過程組成:單頁預訓練,多頁預訓練,以及多任務指令微調。
單頁預訓練採用了DocOwl 1.5的單圖結構化解析數據DocStruct4M,包括文檔解析、表格解析、Chart解析、以及自然圖場景文本解析等,主要目的在於保證壓縮之後的視覺token仍然能還原出圖片中的文字和佈局信息。
多頁預訓練添加了Multi-page Text Parsing任務和Multi-page Text Lookup兩個任務。前者對於多頁文檔圖,給定1-2頁的頁碼,要求模型解析出其中的文字內容;後者則給定文字內容,要求模型給出文字所在的頁碼。多頁預訓練的目標主要在於增加模型對於多頁輸入的解析能力以及區分能力。
經過兩輪預訓練之後,作者整合併構建了單頁文檔理解和多頁文檔理解的問答數據進行聯合指令微調,既包含簡潔回覆,也包含給出頁碼依據的詳細推理。同時,任務形式既有圍繞某幾頁的自由問答,也有整體文檔結構的解析。
DocOwl 2的訓練數據如下圖所示:

實驗結果
在多頁文檔理解benchmark上,相比近期提出的同時具備多圖能力和文檔理解能力的模型,DocOwl 2在以顯著更少的視覺token、更快的首包時間達到了多頁文檔理解的SOTA效果。
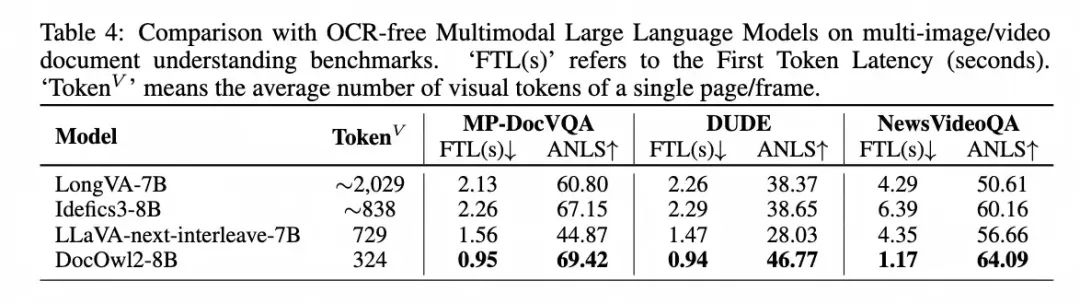
在單頁文檔理解任務上,相比相似訓練數據和模型結構的DocOwl 1.5,DocOwl 2縮減了超過80%的視覺token且維持了絕大部分性能,尤其在最常評測的文檔數據集DocVQA上只有2%的微弱下降。
即使相比當下最優的MLLM,DocOwl2也在常見的文檔數據集DocVQA,圖表數據集ChartQA以及場景文本數據集TextVQA上以更少的token和更快的首包時間的前提下達到了>80%的性能。

從樣例中可以看出,對於A4大小的文檔圖片,即使只用324個token編碼,DocOwl2依然能夠清晰的識別圖片中的文字,或根據文字準確定位到具體的頁碼。
 △圖3: 多頁文字解析
△圖3: 多頁文字解析 △圖4: 多頁文字查找
△圖4: 多頁文字查找除瞭解析文本,DocOwl 2對於多頁文檔的層級結構也能用json的格式表示出來
 △圖5: 文檔結構解析
△圖5: 文檔結構解析對於文檔問答,DocOwl 2不僅能給出答案,還能給出詳細的解釋以及相關的頁碼。

因為具備多圖理解能力,DocOwl 2也能理解文字豐富的新聞影片,同時給出答案所在的幀。

總結:
mPLUG-DocOwl 2聚焦多頁文檔理解,兼顧效果和效率,在大幅縮減單頁視覺token的前提下實現了多頁文檔理解的SOTA效果。
僅用324個token表示文檔圖片也能還原出圖片的文字信息和佈局信息,驗證了當下多模態大模型幾千的文檔圖片視覺表徵存在較大的token冗餘和資源的浪費。



















