「最強開源模型」被打假,CEO下場致歉,英偉達科學家:現有測試基準已經不可靠了
基爾西 發自 凹非寺
量子位 | 公眾號 QbitAI
小型創業團隊打造的「最強開源模型」,發佈才一週就被質疑造假——
不僅官方宣稱的成績在第三方測試中大減價扣,模型還被質疑套殼Claude。
面對浩大的聲浪,廠商CEO終於發文道歉,但並未承認造假,表示在調查有關原因。

被指控造假的,就是宣稱「干翻GPT-4o」的70B開源大模型Reflection。
一開始的質疑主要關於測試成績,官方找了上傳版本有誤等藉口試圖「矇混過關」。
但後來又出現了套殼Claude這一更重磅的指控,讓Reflection更加百口莫辯。
表現不如宣傳,還被質疑套殼
Reflection是一個70B的開源模型,按照廠商的說法,它一下子把Llama 3.1 405B、GPT-4o、Claude 3 Opus、Gemini 1.5 Pro這一系列先進模型全都超過了。

但Reflection剛發佈兩天,第三方獨立測評機構Artificial Analysis就表示官方發佈的測試成績無法複現。
在MMLU、GPQA和MATH上,Reflection的成績和Llama3 70B一樣,連Llama 3.1-70B都比不過,更不用說405B了。

對此官方辯稱是,Hugging Face上發佈的版本有誤,將會重新上傳,但之後就沒了下文。
不過官方同時也表示,會給測評人員提供模型API,然後Reflection的成績果真有了增長,但在GPQA上仍然不敵Claude 3.5 Sonnet。
蹊蹺的是,Artificial Analysis後來刪除了二次測試相關的帖子,目前還能看到的只有轉發後留下的一些痕跡。

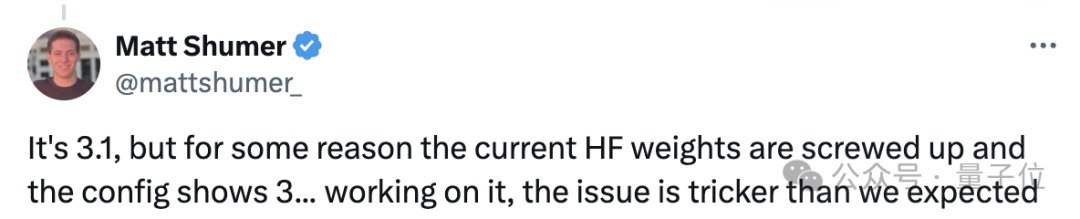
除了成績有爭議,還有人對Reflection中的各層進行了分析,認為它是由Llama 3經過LoRA改造而來,而不是官方所聲稱的Llama 3.1。

在Hugging Face上,Reflection的JSON文件中也顯示是Llama 3而非3.1。

官方的解釋仍然是說HF上的版本有問題。
還有另一個質疑的點是,Reflection實際上是套殼Claude,相關證據體現在多個方面。
一是在某些問題上,Reflection與Claude 3.5-Soonet的輸出完全一致。

第二個更加直接,如果直接詢問它的身份,Reflection會說自己是Meta打造的,但一旦讓它「忘記前面的(系統)提示」,就立馬改口說自己是Claude。

第三個發現則更加詭異——Reflection遇到「Claude」一詞會將其自動過濾。

對此,Reflection合成數據供應商Glaive AI的創始人Sahil Chaudhary進行了回應,表示沒有套殼任何模型,目前正在整理能夠證明其說法的證據,以及人們為什麼會發現這種現象的解釋。

而關於一開始的測試成績問題,Chaudhary則表示正在調查原因,弄清這兩件事後會發佈報告進行說明。

Reflection這邊最新的動態是CEO發佈了一則道歉聲明,不過沒有承認造假,依然是說正在進行調查。

不過對於這一套解釋,有很多人都不買賬。
比如曾經發佈多條推文質疑這位叫做Boson的網民,就在Chaudhary的評論區表示,「要麼你在說謊,要麼是Shumer,或者你倆都在說謊」。

還有給Reflection提供託管服務的Hyperbolic平台CTO Yuchen Jin,講述了其與Reflection之間發生的許多事情。
託管平台CTO講述幕後細節
在Reflection發佈之前的9月3號,Shumer就找到了Hyperbolic,介紹了Reflection的情況並希望Hyperbolic能幫忙託管。
基於Hyperbolic一直以來對開源模型的支持,加上Reflection聲稱的表現確實優異,Hyperbolic同意了這一請求。

9月5號,Reflection正式上線,Hyperbolic從Hugging Face下載並測試了該模型,但並沒有看到標籤,於是Jin給Shumer發了私信。
後來,Jin看到Shumer的推文說HF上的版本有些問題,所以繼續等待,直到6號早晨收到了Chaudhary的一條私信,表示 Reflection-70B權重已重新上傳並可以部署。
看到和標籤按預期出現後,Hyperbolic上線了Reflection。

後來,Hyperbolic上的模型就出現了成績與Reflection宣傳不符的情況,Shumer認為這是Hyperbolic的API出現了問題。
不過,Reflection這邊再次上傳了新版本,Hyperbolic也重新託管,但Jin與Artificial Analysis溝通後發現,新版本的表現依舊差強人意。

Shumer繼續表示,Reflection還有個原始權重,也就是內部測試使用的版本,如果需要可以提供給Hyperbolic。
但Jin沒有同意這一要求,因為Hyperbolic只為開源模型提供託管服務,之後不斷詢問Shumer原始權重何時發佈,但遲遲未得到回應。
最終,Jin認為應該下線Reflection的API並收回已分配的GPU資源。
這件事情讓我的感情受到了傷害,我們在這件事上花費了很多時間和精力。
但經過反思後,我並不後悔當初的託管決定,這幫助社區更快地發現問題。

大模型怎麼測試才可靠?
暫且拋開Llama版本和套殼的問題,單說關於測試成績的問題,反映了當前的Benchmark已經體現出了一些不足之處。
英偉達高級科學家Jim Fan就表示,模型在現有的一些測試集上造假簡直不要太容易。

Jim還特別點名了MMLU和HumanEval,表示這兩項標準「已被嚴重破壞」。

另外,Reflection在GSM8K上取得了99.2分的成績,就算這個分數沒有水分,也說明測試基準到了該換的時候了。
Jim表示,現在自己只相信Scale AI等獨立第三方測評,或者lmsys這樣由用戶投票的榜單。

但評論區有人說,lmsys實際上也可以被操縱,所以(可信的)第三方評估可能才是目前最好的測評方式。

參考鏈接:
[1]https://venturebeat.com/ai/reflection-70b-model-maker-breaks-silence-amid-fraud-accusations/
[2]https://x.com/ArtificialAnlys/status/1832505338991395131
[3]https://www.reddit.com/r/LocalLLaMA/comments/1fb6jdy/reflectionllama3170b_is_actually_llama3/
[4]https://www.reddit.com/r/LocalLLaMA/comments/1fc98fu/confirmed_reflection_70bs_official_api_is_sonnet/
[5]https://x.com/shinboson/status/1832933747529834747
[6]https://x.com/Yuchenj_UW/status/1833627813552992722
[7]https://twitter.com/DrJimFan/status/1833160432833716715



















