MMMU華人團隊更新Pro版!多模態基準升至史詩級難度:過濾純文本問題、引入純視覺問答

新智元報導
編輯:LRS
【新智元導讀】MMMU-Pro通過三步構建過程(篩選問題、增加候選選項、引入純視覺輸入設置)更嚴格地評估模型的多模態理解能力;模型在新基準上的性能下降明顯,表明MMMU-Pro能有效避免模型依賴捷徑和猜測策略的情況。
多模態大型語言模型(MLLMs)在各個排行榜上展現的性能不斷提升,例如GPT-4o在大學水平上的多學科多模態理解和推理(MMMU)基準測試中取得了69.1%的準確率。
不過,基準測試結果是否真的能反映模型對多樣化主題的深入理解,仍然有爭議,或者說模型是否只是利用了統計模式,而非依靠理解和推理的情況下就能得出正確答案?
為瞭解決這一問題並推動多模態AI評估的邊界,MMMU團隊對MMMU基準在健壯性和問題難度上進行提升,新基準MMMU-Pro能夠更準確、更嚴格地評估模型在廣泛的學科領域內真正的多模態理解和推理能力。

論文鏈接:https://arxiv.org/abs/2409.02813
MMMU-Pro的構建過程包括三步:
1. 過濾掉純文本模型可回答的問題;
2. 由人類專家將候選選項增加到 10 個,以減少模型蒙對答案的概率;
3. 引入純視覺輸入設置,即問題直接寫在圖像中,既要求模型像人一樣同時具有「看」和「讀」的能力,也可以在現實場景中直接將模型用於屏幕截圖或照片,無需分離問題與圖片;
實驗結果顯示,模型在MMMU-Pro上的性能明顯低於 MMMU,下降 16.8% 到 26.9%,模型的排名通常與原始模型相似,但GPT-4o mini 模型的健壯性與GPT-4o相比,健壯性較差。
研究人員中還探討了 OCR 提示和思想鏈 (CoT) 推理的影響,結果發現 OCR 提示的影響很小,而 CoT 通常可以提高性能。
MMMU-Pro:更健壯的MMMU
重新審視MMMU基準測試
大規模多學科多模態理解和推理(MMMU)基準測試是一個綜合性的數據集,能夠評估多模態人工智能模型在需要特定學科知識和深思熟慮推理的大學水平任務上的表現。
MMMU由來自大學考試、測驗和教科書的1.15萬個精心策劃的多模態問題組成,涵蓋了六個核心學科的30個主題和183個子領域。
MMMU中的每個問題都是一個多模態的圖文配對,有4個多項選擇選項,包括圖表、圖解、地圖和化學結構等30種不同的圖像類型。
該基準已經成為了多模態領域的標準評估工具,許多著名多模態模型在發佈時都會使用MMMU來評估能力。

但與此同時,MMMU社區也有許多負面反饋,研究人員總結為兩個問題:
1. 文本依賴性:某些問題相對獨立或與相應的圖像無關,即無需輸入圖像,僅靠問題文本就能回答;
2. 利用捷徑:即使問題需要圖像才能正確回答,但模型通常也能找到候選選項中的捷徑或相關性,根據預訓練中獲得的先驗知識來得出正確答案。
所以MMMU-Pro在構建的時候,更加細緻地考慮問題與圖像之間的關聯性,以及智能體是否真正理解了問題的本質,而不僅僅依賴於文本信息或選項中的模式識別。
構建方法
為了緩解這些問題並構建一個更健壯的基準測試,研究人員設計了一個三步方法:

1. 篩選問題
刪除僅通過文本的大型語言模型(LLMs)就能回答的問題。
研究人員選擇了四個強大的開源LLMs:Llama3-70B-Instruct、Qwen2-72B-Instruct、Yi-1.5-34B-Chat和Mixtral-8×22BInstruct(gpt-4o),並要求模型在沒有圖像的情況下回答MMMU問題;即使模型表明需要視覺輸入,也要求模型提供答案。
對每個模型重覆上述過程十次,如果某個模型能夠正確回答一個問題超過五次,就可以認為這個問題是「純文本可回答的」,排除掉三個模型都可回答的問題。
然後從賸餘的問題池中,在30個主題下,每個主題隨機抽取60個問題,總計1800個問題。
2. 增加候選選項
為了防止模型根據問題和候選項之間的關聯來回答問題,研究人員將問題的候選項從四個增加到十個,使模型更難蒙對。
在增加選項的過程中,專家還會對原始的標註問題進行審查,以確保問題與圖像的相關性,並排除了缺乏明確聯繫或連貫性的問題,篩選出了70個問題。
3. 通過僅視覺輸入設置增強評估
為了進一步挑戰模型的多模態理解,研究人員在MMMU-Pro中引入了純視覺輸入設置,將問題嵌入到屏幕截圖或照片中。
人類標註人員需要在模擬顯示環境中手動捕獲照片和屏幕截圖,圖片涉及不同的背景、字體樣式和字體大小,可以覆蓋現實世界條件的多樣性。
 最終總共獲得了3460個問題,其中1730個樣本是標準格式 ,另外1730個是屏幕截圖或照片形式。
最終總共獲得了3460個問題,其中1730個樣本是標準格式 ,另外1730個是屏幕截圖或照片形式。實驗結果
實驗設置
研究人員用到的基線模型包括:
1. 閉源模型(Proprietary Models):GPT-4o(0513)和GPT-4o mini,Claude 3.5 Sonnet,以及Gemini 1.5 Pro(0801和0523版本),代表了多模態模型能力的最前沿。
2. 開源模型:InternVL2(8B、40B和Llama3-76B版本)、LLaVA(OneVision-7B、OneVision-72B和各種NeXT版本)、VILA-1.5-40B、MiniCPM-V2.6、Phi-3.5-Vision和Idefics3-8B-Llama3
研究人員在三種不同的測試環境下對模型進行評估:(1)4個選項的標準設置、10個選項下的性能和(3)純視覺輸入,其中(2)和(3)的平均分作為MMMU-Pro的總體性能得分。
總體結果

增加候選選項的影響
從4個候選選項增加到10個(∆1)對所有模型的性能都有明顯的下降,GPT-4o(0513)的準確率下降了10.7%,從64.7%降至54.0%,表明增加選項數量可以有效降低了模型猜測正確答案的可能性,迫使模型更深入地理解和處理多模態內容。
純視覺設置的影響
GPT-4o(0513)在純視覺設置中的準確率又下降了4.3%,而LLaVA-OneVision-72B的準確率大幅下降了14.0%,表明純視覺設置確實能考驗出模型整合視覺和文本信息的能力。
對MMMU-Pro的綜合照響
總體的性能差異∆3代表MMMU-Pro與MMMU(驗證集)之間的差異,可以看到Gemini 1.5 Pro(0801)和Claude 3.5 Sonnet模型分別出現了18.9%和16.8%的下降,而VILA-1.5-40B等模型的下降的更多,達到了26.9%。
全面的準確率顯著降低表明,MMMU-Pro成功地降低了模型在原始基準測試中可能利用的捷徑和猜測策略。
OCR在視覺設置中有幫助嗎
研究人員探討了光學字符識別(OCR)提示是否有助於提高MMMU-Pro僅視覺輸入設置中的性能。
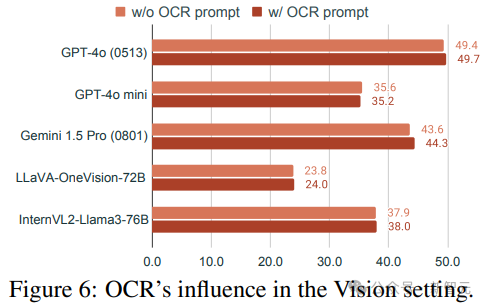
OCR提示明確要求模型寫出圖像中的問題文本,不過,在評估的模型中,包含OCR提示並沒有顯著改變性能。

微小的性能差異表明,現有的模型已經能夠從圖像中提取和理解文本信息,即使沒有明確的OCR提示也是如此。
當文本嵌入在圖像中時,雖然顯著增加了視覺輸入的整體複雜性,但簡單的OCR不足以解決MMMU-Pro僅視覺輸入設置所提出的問題,模型不僅要識別和提取文本,還要理解其在圖像中的上下文、與視覺元素的關係以及與當前問題的相關性。
CoT有助於回答MMMU-Pro問題嗎?
在MMMU-Pro基準測試中,研究人員估了思維鏈(Chain of Thought,簡稱CoT)提示在提升智能體性能方面的有效性,包括標準設置和視覺輸入設置。
結果顯示,在這兩種設置下,引入CoT提示都能夠帶來性能的提升,但不同智能體的性能提升幅度存在顯著差異。

例如,Claude 3.5 Sonnet在標準設置中表現出顯著的性能提升,準確率從42.7%提高到55.0%,相比之下,LLaVA-OneVision-72B只有很小的性能提升。
值得注意的是,一些智能體,比如VILA1.5-40B,在引入CoT提示後性能反而出現了下降,可能與模型在遵循指令方面的能力有關。如果模型無法準確地遵循指令,生成CoT解釋就會變得更加困難。
此外,有些模型無法保持正確的回覆格式,即存在所謂的「簡化回覆格式」問題。
參考資料:
https://arxiv.org/abs/2409.02813




















