昂貴LLM的救星?Nature新研究提出新型憶阻器,比Haswell CPU高效460倍
機器之心報導
編輯:Panda
前些天,OpenAI 發佈了 ο1 系列模型,它那「超越博士水平的」強大推理性能預示著其必將在人們的生產生活中大有作為。但它的使用成本也很高,以至於 OpenAI 不得不限制每位用戶的使用量:每位用戶每週僅能給 o1-preview 發送 30 條消息,給 o1-mini 發送 50 條消息。
實在是少!
為了降低 LLM 的使用成本,研究者們已經想出了各式各樣的方法。有些方法的目標是提升模型的效率,比如對模型進行量化或蒸餾,但這種方法往往也伴隨著模型性能的下降。另一種思路則是提升運行這些模型的硬件——英偉達正是這一路線的推動者和受益者,但該公司的主要策略還是提升 GPU 的性能;另一些研究者則正在探索針對 AI 構建高效高性能的新型硬件體系。憶阻器(memristor)便是其中一個重要的研究方向。
憶阻器是一種電子元件,其能夠限制或調節電路中電流的流動,並且可以記憶之前通過的電荷量。憶阻器在許多實際應用中具有重要意義,原因之一是其具備非易失性特性,即在斷電情況下仍能保持記憶,這使得其在無電源或電源中斷時依然能夠持續使用。憶阻器被認為是和電阻器、電容器、電感同層級的基礎電子元件。憶阻器的概念最早在 1971 年由華人科學家蔡少棠提出。
近日,Nature 發佈了一篇來自印度科學學院、得克薩斯農工大學和愛爾蘭利莫瑞克大學的一篇論文,其中提出了一種「線性對稱的自選擇式 14 bit 的動力學分子憶阻器」。

論文標題:Linear symmetric self-selecting 14-bit kinetic molecular memristors
論文地址:https://www.nature.com/articles/s41586-024-07902-2
該論文的核心亮點是,其中提出的分子憶阻器在核心的矩陣運算上能實現遠超電子器件效率的 14 bit 模擬計算;並且其實現了超過 73 dB 的信噪比,比之前的最佳水平直接高出了 4 個數量級,同時其能耗量比電子計算機低 460 倍!
這樣的出色表現讓 AI 工程師 Rohan Paul 忍不住驚歎:「如果這是真的,算是到了 LLM 的真空管變矽晶體管時刻嗎?」

那麼,這篇論文究竟提出了什麼呢?真的有希望將 LLM 從高功耗高成本的困境中解脫出來嗎?讓我們來簡單瞭解一下。
挑戰
我們知道,向量-矩陣乘法(VMM)是神經網絡等許多計算算法的基礎。但是,VMM 很難實現,因為對於長度為 n 的向量,所需的計算步驟為 n²。儘管對稱運算可以降低 VMM 的複雜性,但它們只適用於特定的矩陣結構,比如人工智能中的非結構化數據。
為了得到高效的通用型 VMM 引擎,人們一直在推動硬件的發展,尤其是點積引擎(DPE)——一種可在單個時間步長內實現 VMM 的模擬加速器。儘管 DPE 有應對計算規模擴展的潛力,但其應用也受限於其精度,因為模擬電路元件僅提供 2-6 個等效比特。這種精度不足的根源在於其物理性質不夠理想,包括非線性的權重更新、不對稱行為、噪聲、電導漂移和設備間差異。這是神經形態計算的一個根本性挑戰。
為瞭解決這個問題,需要發明一種能嵌入到電路中的元件,並且嵌入數量要比目前可用的模擬級別高出幾個數量級。
解決方案
該團隊宣稱已經發明出了這樣的元件。這是一種分子憶阻器交叉開關矩陣,可集成在電路板中。其展現出了 14 比特的模擬精度、近乎理想的線性和對稱權重更新,以及每個電導層級的一步式可編程性(one-step programmability)。
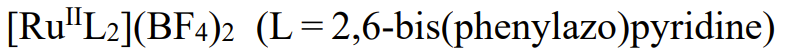
薄膜。更多詳細的設計參數請參看原論文。
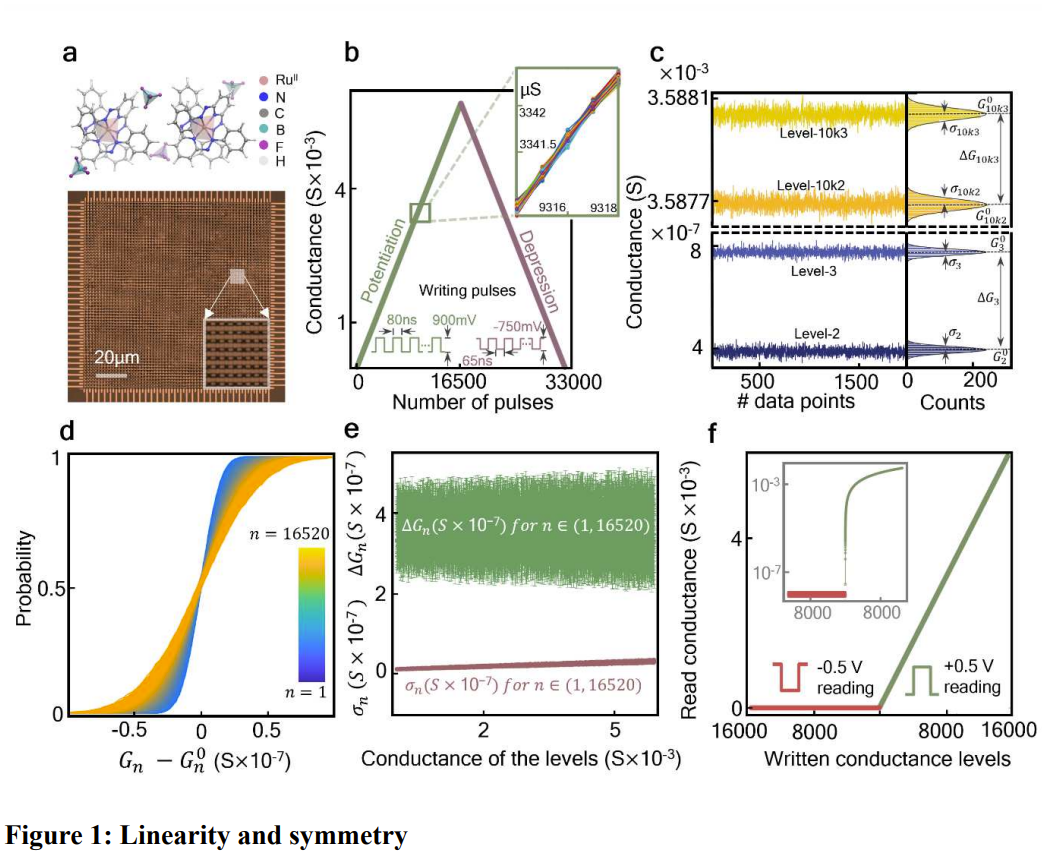
總之,該器件實現了想要的功能,並且具有相當好的非易失性和穩健性。如圖 2a 所示,這個交叉開關矩陣耐久性很好,經過 10^9 個操作週期後,權重更新特性依舊保持不變。另外,圖 2b 表明使用 500 mV 直流電壓在 85°C 環境下,該結構能在 11 天內不出現明顯的電導漂移。另外,他們還測試發現,其能維持長達 7 個月的電導保持率。
實驗
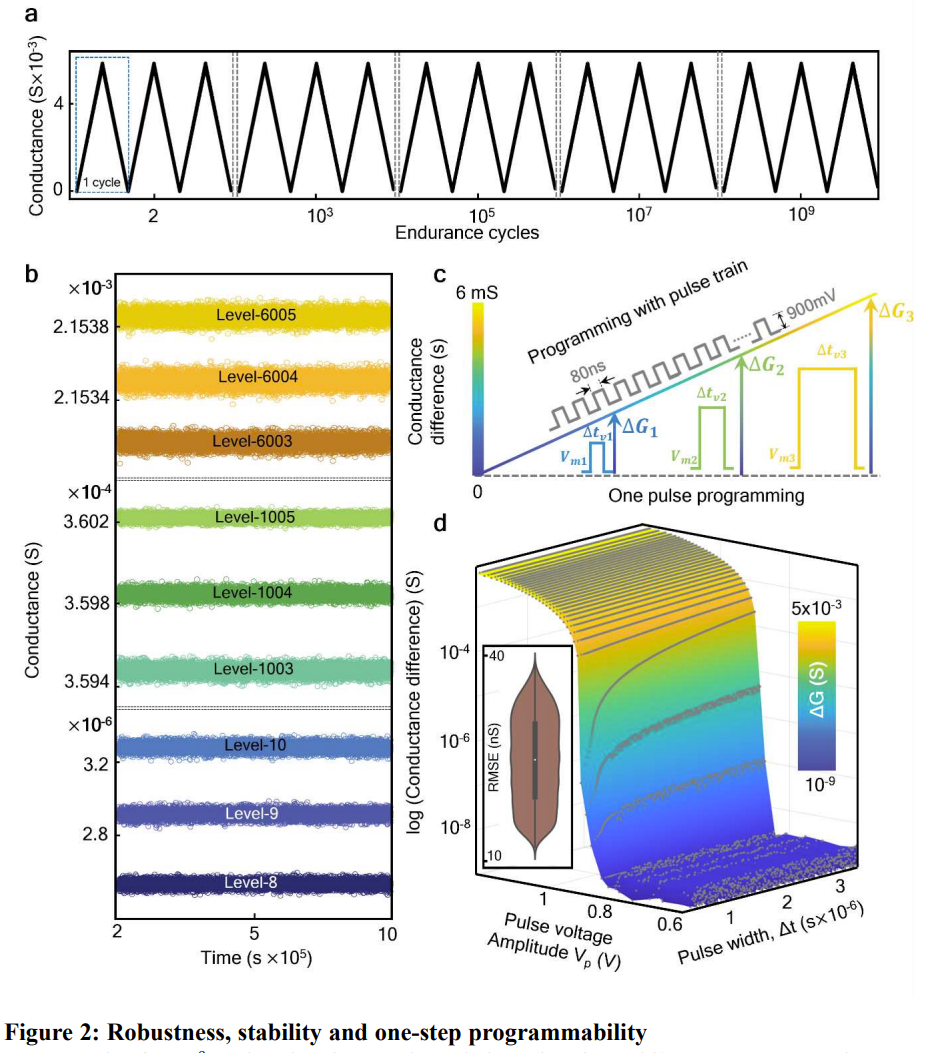
使用這個 64×64 的分子交叉開關矩陣,該團隊執行了 VMM 實驗,這用到了一個他們定製的超過 16 比特準確度的混合信號外圍電路,如下圖 4 所示。a 圖是對其編程,使之執行離散傅里葉變換(DFT)。b 圖則比較了計算出的 DFT 輸出與軟件計算的結果,可以看到它們之間非常一致,這表明這個結構是有效的。
此外,他們還執行了矩陣-矩陣乘法運算,這是幾乎所有 AI 和機器學習算法的基礎運算。結果發現,如果讓兩個 64×64 的矩陣相乘,則該結構僅需要執行 64 步,但如果讓電子計算機來幹同樣的事,則需要執行 262,144 次運算。
圖 4c 表示其矩陣乘法的準確度不依賴於對稱性,這是處理非結構化數據的一個關鍵屬性。
該團隊評估了不同矩陣組合,包括對稱、隨機和雙隨機矩陣。最終得到了 73-79 dB 的信噪比。該團隊表示這是一個非常重大的進步。
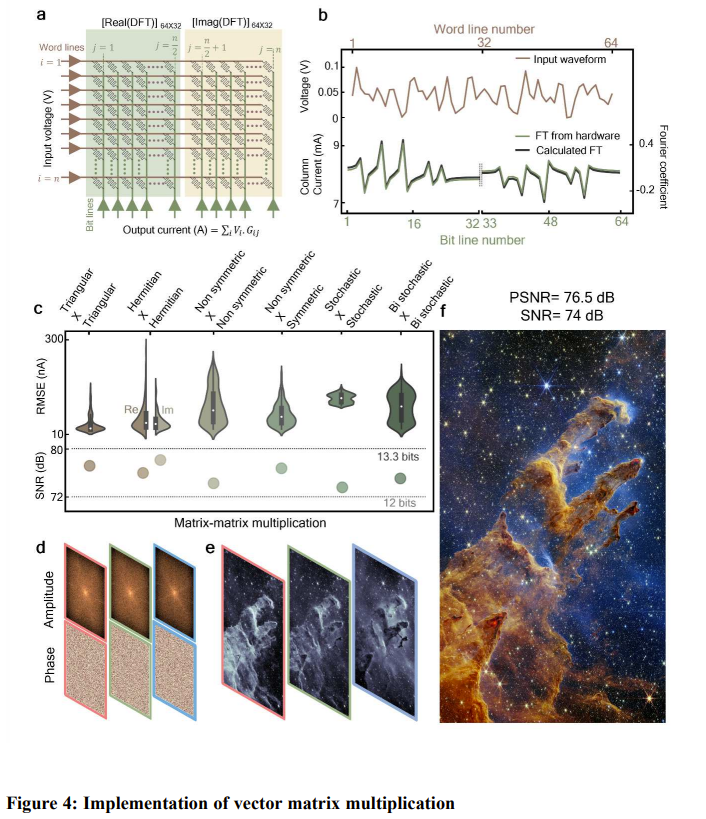
他們還展示了一個非常有趣的用例。使用矩陣乘法,他們使用從韋比望遠鏡數據庫檢索到的頻域數據,通過逆傅里葉變換重建了標誌性的「創生之柱」圖像,見圖 4d-f。
之所以選擇外太空數據,是因為它缺乏對稱性。這項任務每個平面都需要 26,256 個時間步驟,而數字計算機所需的步驟數超過了 10^8。
結果,他們得到的信噪比為 74 dB,峰值信噪比為 76.5 dB,直接高出了之前最佳的 DPE 4 個數量級。
這個轉譯過程的後續階段將需要進一步擴展這個交叉開關矩陣,並開發具有高精度的片上外圍電路。
該團隊在論文中描述了一種經過功率優化的外圍電路設計,可以提供超高的能效:每秒每瓦 4.1 萬億次運算 (TOPS/W) 。這個數據比 18 核 Haswell CPU 高 460 倍,比當前最高效的英偉達 K80 GPU 高 220 倍,並且這還有很大的改進空間。
這個示例展示了基於分子的技術的巨大潛力,通過將其集成到 CMOS 電路中,可以大幅超越最先進的加速器的性能。
如果 OpenAI 等未來開發的大模型也能運行在基於此類技術開發的硬件上,那 AI 的使用成本必定能下降很多。
更多研究細節、數據和代碼請訪問原論文。
參考內容:
https://x.com/rohanpaul_ai/status/1834202945581441420



















