互聯網已經被AI汙染的差不多了
最近一張用AI批量做號的微信截圖流傳在各個群裡,有人自爆用AI在小紅書做了一個龐大的虛假帳號矩陣,通過售賣帳號進行變現。

這並非個例,你有沒有一種感覺,現在刷手機的時候越來越分不清真實和虛擬了?當你瀏覽社交媒體、搜索信息或閱讀文章和觀看影片時,你真的能分辨出哪些內容來自人類,哪些又是AI的產物?更令人不安的是,你如何確定你所看到的「事實」不是AI的幻覺?
AIGC是一場互聯網革命,不幸的是,它的興起也伴隨著內容濫用。大量低質量、AI生成的關鍵詞堆砌的內容傾瀉到網絡上,充斥在搜索引擎的結果當中,互聯網上很大一部分內容已淪為垃圾信息。
小紅書上的「細糠」可能是AI生成的,音樂平台則充斥著AI生成的歌曲,Spotify上的AI翻唱樂隊,把流行歌曲的翻唱添加到正常歌單當中,與真實藝術家演唱的歌曲一起播放,獲得了數百萬的播放量並獲得版稅。最近,美國北卡羅來納州一名男子被捕,他用AI製作了數十萬首歌曲,並通過AI機器人刷播放量,獲利超過1000萬美元。
連你在亞馬遜上買的電子書可能也是AI寫的。一本使用ChatGPT撰寫的關於野生蘑菇烹飪的電子書,甚至建議讀者用舌頭去嚐一嚐的方式來識別蘑菇種類。
最悲哀的是,這些垃圾書實際上也賺不了多少錢,賺錢的是教學生製作垃圾電子書的教程,這完全是一場騙局和垃圾的閉環,而受害者是熱愛閱讀和寫作的讀者與作者。
 亞馬遜上出現了大量AI生成的垃圾書籍
亞馬遜上出現了大量AI生成的垃圾書籍一、內容農場從未如此容易
「內容農場」是指為了牟取廣告費等商業利益或出於控制輿論、帶風向等特殊目的,快速生產大量網絡文章來吸引流量。讓用戶在尋找有用信息時不得不耗費更多時間和精力。為了吸引眼球,一些帳號甚至故意發佈虛假信息或誇大事實,誘導用戶點擊。
發佈「西安突發爆炸」虛假新聞的帳號所屬機構,最高峰一天能生成4000至7000篇假新聞,每天收入在1萬元以上,而公司實際控制人王某某經營著5家這樣的機構,運營帳號達842個。
以前的內容農場借助廉價勞動力,批量產出文章,比如此前的山東「新媒體村」以及北馬其頓共和國的假新聞影響美國大選等案例。現在,內容農場也正式從手工作坊進入了AI時代。
AI工具使得內容生成成本大大降低,單次瀏覽的收入即可覆蓋成本。根據IT技術博主阮一峰的計算,使用某國產AI模型生成一篇文章僅需0.00138元,而單次瀏覽的廣告收入約為0.00145元,這種模式使得內容農場比以往更容易盈利。
「內容農場從來沒有這麼容易過,我先買一個熱搜數據庫,然後花費100多元,就能生成10萬篇文章,最後加入廣告,做好SEO,網站上線,等著用戶點進來就行了。不難想像,資訊類網站未來大概都是這個模式。真人生產內容,成本太高,無法與AI內容抗衡,註定只能是小眾網站。」
除了內容農場,一些平台也在利用AI進行SEO,把自己打造成為「內容農場」。
豆包此前為了在搜索引擎里權重更高,將用戶和AI的聊天頁面生成靜態網頁,然後被搜索引擎抓取,給自己引流。開發者社區稀土金塊也同樣通過AI批量生成大量內容被Google抓取,這些內容缺乏實質價值,引發用戶廣泛批評。

雖然目前豆包和稀土金塊都已經移除相關內容,但中文雲計算網站和開發者社區仍然是內容農場的重災區。
AI搜索引擎Perplexity通過對搜索結果添加腳註,鏈接到互聯網的實時信息源來確保結果的準確性,PerplexityCEO也對外聲稱「引用來源是我們的通行證」。
但根據AI內容檢測平台GPTZero在今年6月進行的一項研究,Perplexity用戶平均搜索三個關鍵詞,就會遇到AI生成的內容。像「日本京都的文化節」、「人工智能對醫療行業的影響」、「泰國曼穀必嚐街頭美食」以及「值得關注的年輕網球選手」等搜索,返回的結果中包含了引用AI生成材料的答案。
這項研究揭示了Perplexity這樣的AI搜索產品在提供優質來源方面的一個缺陷,也反映出互聯網正日益充斥著AI生成的內容。
 關鍵詞「日本京都的文化節慶」,唯一引用來源是一篇完全由AI生成的文章
關鍵詞「日本京都的文化節慶」,唯一引用來源是一篇完全由AI生成的文章Perplexity還推出了Pages的功能,使用者可以把搜索與生成的內容製作成公開頁面,而且搜尋引擎也能收錄。後續也傳出一些神奇用法,例如假裝詢問AI關於自家產品的內容,然後利用Perplexity Page幫自己的產品做一個頁面,最後被搜索引擎收錄,達到引流的目的。根據aHrefs的數據,Perplexity每月有240萬訪客來自Google。
360AI搜索也曾經透露,在晚上會借助算力資源使用AI生成答案,每天產生數百萬的網頁供應給搜索引擎。
二、從「內容社區」到「內容墳場」
內容社區也是AI入侵的「重災區」,Quora曾經是社區氛圍良好的問答社區,有評論形容其為「更有條理的Yahoo Answers,更古典的Reddit,更主觀的域奇百科」。而如今的Quora卻成為了一個信息垃圾場,充斥著無意義的AI生成的內容,以及一大堆答非所問的內容。
一開始一些用戶使用ChatGPT生成答案,然後秒成Quora的「專家」,後來Quora直接在頁面上集成了ChatGPT生成的答案,而這些錯誤的答案又傳播到了Google的搜索結果中。

 「雞蛋可以被融化,常見的方法是用爐子或微波爐加熱」
「雞蛋可以被融化,常見的方法是用爐子或微波爐加熱」一位2013年就開始使用Quora的用戶評論道:「最終,Quora將充斥著機器的提問、機器的回答,別無其他。」
開發者也在借助AI SEO獲取流量,Eightify.app和Glarity.app是兩個Youtube影片總結插件,通過AI技術批量生成圖文並茂的文章,在短時間內獲得了巨大的流量增長。Eightify.app自2022年8月開始運營,其月訪問量從幾十萬迅速攀升,於2023年1月達到峰值600多萬。緊隨其後的Glarity.app也在2023年2月採用類似策略,月訪問量從1月份的10萬激增至3月份的1200多萬。
SEO行業從業者哥飛告訴矽星人,搜索引擎也好,內容平台也好,他們不是要幹掉AI生成的內容,而是要幹掉低質量內容。這些AI生成內容能通過Google算法審核,表明其質量達到了一定水準,但由於流量增長過快,Eightify.app和Glarity.app引起了全球SEO從業者的關注。「如果不幹掉,那麼就可以認為Google默許這樣做,大家就會跟風這樣做。」
Google最終採取了人工干預措施。要求這兩家網站停止批量生成內容的行為,並刪除此前生成的相關內容。最新數據顯示,干預措施生效後,Eightify.app的月訪問量已降至60萬,而Glarity.app更是銳減至20多萬。
SEO汙染這樣的事情其實一直存在,以前沒有AI,也有各種小偷爬蟲、偽原創工具,只不過隨著AI的發展,這場「貓鼠遊戲」似乎對於平台來說越來越難了。
一個有趣的例子是IsaacJinyu在知乎的一次AI臥底實驗,他通過知乎問答數據反向生成AI數據,然後微調Qwen2-7B,去除文字中的AI味。這個實驗從7月5日開始,到8月3日整整一個月,沒有任何人發現帳號AI的身份。


三、學術圈也被AI攻陷
日益增多的AI生成內容其影響遠不止於屏幕,這種潛移默化的侵入正悄然影響學術領域。
今年初,西安交大一篇論文因為使用AI生成的配圖而被撤稿,相關圖片中,大鼠長出了詭異的器官,細胞信號傳導圖像電路板。

在另一篇論文的一張配圖中,小腿和手臂的骨骼數量出現了明顯的錯誤。

這隻是AI滲透學術領域的冰山一角,在Google學術上搜索「截至我上次知識更新」(as of my last knowledge update)或「我沒有訪問實時數據的權限」(I don’t have access to real time data),會出現大量借助AI生成的論文。

學者們在壓力之下需在期刊上發表論文,選擇了使用AI,而學生在AI的幫助下完成作業和論文已經成為一種常態,「人工代寫」論文變成了「人工智能」代寫。
四、AI訓練的惡性循環
AI模型的準確性在很大程度上取決於其訓練數據的質量。「垃圾進,垃圾出」這一短語起源於計算機科學的早期。尤其對於數據分析和AI而言,這一原則強調了一個基本觀念:輸出質量與輸入質量緊密相關。
AI生成的內容激增,但這些內容並非憑空而來,而是基於大量人類創造數據的訓練。但在這個過程中存在一個潛在的缺陷,隨著這些AI生成的內容重新流入互聯網,最終又成為訓練未來AI模型的一部分數據。正如用牛喂養牛導致了瘋牛病一樣,用大量由AI創建的數據來訓練AI同樣具有破壞性。這是一個自我消耗的過程,導致輸出質量越來越低。
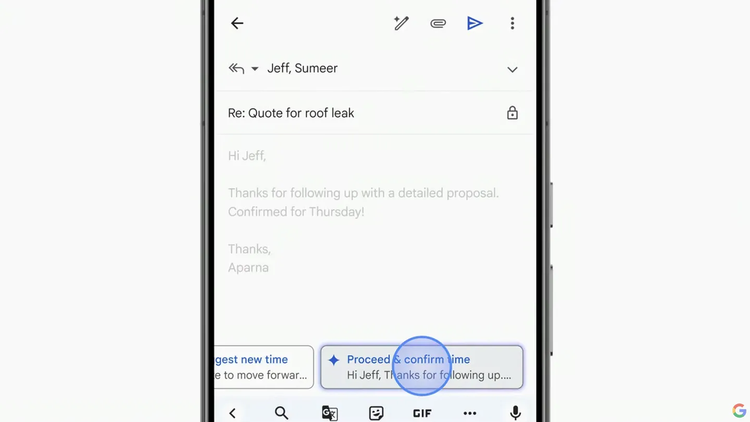
Google在Google I/O 2024大會上演示了AI簡要概括某人未讀的郵件,隨後演示了生成新郵件以供回覆的功能。不難推斷,收件人將利用AI來閱讀這些郵件,並生成新的AI回覆,讓其他人也用AI閱讀。這類功能普及之後,每個人的收件箱是否會充斥著沒有人真正會去閱讀或撰寫的郵件?
AI能製作的又何止是郵件?AI為無人閱讀的AI帖子撰寫無人閱讀的AI評論,生成無人聆聽的包含AI歌曲的歌單,還能為無人訪問的網站創作無人觀賞的AI圖像。

AI生成的《Nothing,Forever》在一個無人觀看的Twitch直播間24小時不間斷地播放著。
AI出現之前互聯網就充滿垃圾,只是有了AI之後,生產垃圾的效率更高了,製造的垃圾產量龐大,而我們在處理這些垃圾的能力上顯然是不夠的。或許在不久的將來,互聯網上的合成圖像將比真實圖像更多,合成網站將超過真實網站,AI生成的文本也將多於真實文本:由機器產生的無盡內容,堵塞了一切,浪費每個人的時間。
 AI圖片汙染互聯網圖片庫
AI圖片汙染互聯網圖片庫神話中的銜尾蛇(Ouroboros)吞食自己的尾巴,象徵著無節制增長與自我消耗的陷阱,其圓形形態也象徵著無限和生命的循環。在現在的故事中,這條蛇代表著AI的世界,而它的尾巴則是源源不斷的AI生成的內容。這個循環就在我們眼前發生著,也許在這條蛇還沒有完全長大前,我們還有機會救互聯網一把。



















