港大發佈智能交通大模型全家桶OpenCity!打破時空零樣本預測壁壘,訓練速度最多提升50倍

新智元報導
編輯:LRST
【新智元導讀】近日,香港大學發佈最新研究成果:智能交通大模型OpenCity。該模型根據參數大小分為OpenCity-mini、OpenCity-base和OpenCity-Pro三個模型版本,顯著提升了時空模型的零樣本預測能力,增強了模型的泛化能力。
精確的交通流量預測對於提升城市規劃和交通管理效率至關重要,有助於更合理地分配資源並提升出行質量。
然而,現有的預測系統在處理未知區域的交通預測,以及進行長期預測時,常常無法達到預期效果,這些挑戰主要源於交通數據在空間和時間上的不一致性,以及在不同時間和地點的顯著變化。
基於「開發一種具有高度通用性、魯棒性和適應性的時空預測模型」的思路,香港大學、華南理工大學等機構的研究人員提出了一個創新的基座模型OpenCity,能夠識別並整合來自多個數據源的時空模式,以增強在不同城市環境中的零樣本學習能力。

論文鏈接:http://arxiv.org/abs/2408.10269
代碼鏈接:https://github.com/HKUDS/OpenCity
OpenCity結合了Transformer和圖神經網絡技術,以捕捉交通數據中的複雜時空關聯。通過在廣泛的、多樣化的交通數據集上進行預訓練,OpenCity能夠掌握豐富且具有廣泛適用性的特徵表示,這些特徵適用於多種交通預測情境。
實驗結果顯示,OpenCity在零樣本學習方面取得了顯著成效。
此外,OpenCity的可擴展性也得到了驗證,這表明有望構建一個能夠滿足所有交通預測需求的系統,並且能夠以較低的額外成本適應新的城市環境。
概述
現有問題
-
C1. 空間泛化:現有的交通預測模型在空間泛化方面存在限制,難以適應不同地區因基礎設施和人口特徵不同而表現出的各異交通模式。在現實條件下,全面部署傳感器來收集數據並不可行。因此,開發一種能夠在有限數據支持下適應新區域的模型顯得格外關鍵。這種模型能夠降低跨城市部署的成本,並確保交通預測系統在多元化的城市環境中有效運作,無需頻繁重訓練或調整。
-
C2. 時間泛化與長期預測:現有的交通預測模型雖然能夠較好地處理短期預測(如未來一小時內),但在進行數小時甚至數天的長期預測時則效果不佳。模型難以適應城市環境中隨時間變化而變化的複雜交通模式,這一點限制了城市規劃者和交通管理者製定有效長期策略的能力。
-
C3. 通用表徵學習與時空異質泛化:開發能夠廣泛適用的交通模型,關鍵在於開發能夠廣泛適用的交通模型,通過學習通用的交通動態特徵實現泛化。這種泛化學習使得模型能夠適應不同的應用場景,即便是在缺乏特定場景訓練數據的情況下也能運行。考慮到城市交通的多樣性及其時空分佈的顯著變化,模型需要具備適應這些變化的能力,以保持其功能性和靈活性。

圖1 左圖展示了不同交通數據集之間的數據分佈差異,突顯了開發能夠適應這些分佈差異的模型的必要性。右圖則比較了OpenCity在零樣本條件下的表現與使用全樣本數據的基線模型的表現。結果表明,儘管OpenCity面對時空異質性分佈偏移的挑戰,其性能仍可與全樣本基線模型匹敵
論文貢獻
(1)通用時空建模。OpenCity針對城市交通在不同地區及時間內的多樣性和變化進行專門設計。
(2)卓越的零樣本預測能力。OpenCity在未經特定區域訓練的情況下,展示了超越常規模型的性能,這突顯了其泛化特徵學習的能力,並允許該模型在新環境中快速部署,減少了重訓練的需求。
(3)快速適應性。OpenCity在多個時空預測任務中顯示了其廣泛的適用性,能夠快速地適應各種場景,實現靈活的部署。
(4)擴展能力。OpenCity展現了良好的擴展潛力,這意味著它能夠在幾乎無需額外訓練的情況下有效地適應未知環境。
方法
 圖2 OpenCity整體框架
圖2 OpenCity整體框架用於分佈偏移泛化的時空嵌入
上下文歸一化
傳統方法通常依賴於訓練數據的統計特徵,例如均值和標準差,來進行數據的標準化處理。然而,當測試數據表現出與訓練數據在地理空間上無重疊的異質性時,這些統計參數可能不再適用,也難以適應。為了克服這一挑戰並滿足零樣本交通預測的需求,採用了實例歸一化IN(⋅)處理數據。
該方法利用每個個區域的單個輸入實例

的均值μ(Xr)和標準差σ(Xr)進行數據標準化,而不依賴於整個訓練集的統計信息。相關研究表面實例標準化能有效減輕訓練數據與測試數據之間分佈差異的問題,形式化如下:

用於高效長期預測的Patch嵌入
OpenCity旨在應對長期交通預測的複雜性,特別是處理增加的輸入時間步長,這會導致計算資源和內存需求顯著增加。為減輕這一負擔,採納了一種基於時間維度的Patch分割策略。在此策略中,設定了Patch長度P,用於確定每個Patch包含的時間步數;同時設置了步長S,用於定義連續Patch之間的重疊程度。採用此Patch處理方式後,輸入數據的形狀發生了變化。

,這裏𝑁為塊的數量,
研究人員選擇將一小時的交通數據設定為一個Patch的長度,並設置步長S=P,這樣的配置幫助模型有效捕捉並適應交通數據在更長時間跨度的變化趨勢。
此外,採用Patch處理方法顯著減少了對計算和內存的需求,從而實現了更高效和可擴展的長期交通預測。
Patch處理完成後,對數據應用線性變換和正餘弦位置編碼PE,以獲取最終的時空嵌入表示。
被用於後續模塊的輸入,如下:
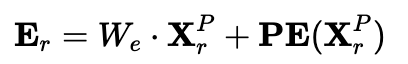
時空上下文編碼
為了捕獲交通數據中的複雜時空模式,OpenCity模型整合了時間與空間的上下文信息。
通過充分考慮這兩個維度的多個因素,OpenCity能更全面地洞察影響交通模式的多元因素。這種整體方法使得該框架能夠在各種時間段和地理區域中提供更精確的預測。
時間上下文編碼
為了使OpenCity成功地捕捉交通數據中的獨特時間模式,利用了諸如一天中的時間


等時間特徵來識別週期性關係,並通過線性層轉換這些時間特徵,生成反映時間上下文的特定嵌入。通過精確模擬交通流的週期性特徵,的方法能夠在長期預測中達到高精度。
和一週中的某一天
時間上下文的編碼過程融合了Patch操作和時空嵌入的對齊,具體實現如下:

空間上下文編碼
鑒於地理特徵的多樣性,每個區域的交通模式具有其特有的特徵(例如,交通樞紐的流量通常較高)。為了有效捕捉這些區域性特徵,在交通網絡模型中引入了空間上下文。
首先,進行了拉普拉斯矩陣的標準化處理:
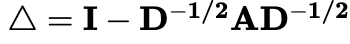
,其中I和D分別是單位矩陣和度數矩陣。
然後執行特徵值分解,得到

,其中,U和Λ分別代表特徵值和特徵向量。
選擇了最小的k個非零特徵向量作為區域嵌入s,用以編碼交通網絡的結構特性。這些嵌入隨後經過一個線性層的處理,用以產生最終的空間編碼

時空依賴建模
時間依賴建模
OpenCity利用新提出的TimeShift Transformer架構,專注於捕捉時間依賴性。
該方法從兩個主要方面識別交通模式:
(1)週期性交通模式。模型能夠識別交通中的週期性和重覆模式,如每小時、每日和每週的循環。通過對這些週期性變化的編碼,的方法可以更精確地解析交通網絡中的規律性。
通過時間嵌入D和空間嵌入C來捕獲交通模式的週期性特徵。目標在於探索歷史交通模式與未來趨勢之間的關係。時間嵌入被細分為歷史時間信號和未來時間信號兩部分:


的模型專門建模了歷史時間和未來時間的映射模式,這使得它能夠更有效地學習和應用交通時間序列的週期性特徵。此過程通過構建一個時間轉移的多頭注意力機制來完成,其中將未來的時空嵌入作為查詢(Query),將歷史的時空嵌入作為鍵(Key),並將歷史時空數據的表示作為值(Value)。
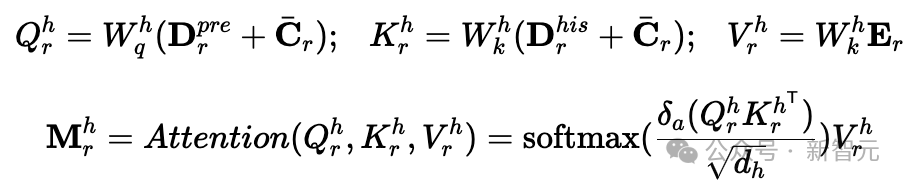
其中,

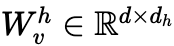


為來自第h個注意力頭的週期關聯編碼模塊的輸出。
為更新後的空間嵌入,
為權重矩陣,δa為dropout操作。
和
引入RMSNorm以提升訓練過程的穩定性。通過明確地建立歷史與未來時間信息之間的聯繫,OpenCity具備了識別週期性的時空交通模式的能力。
(2)動態交通趨勢。除週期性模式外,時間編碼器還能捕捉交通數據隨時間發展的複雜和非線性動態趨勢。
該模塊旨在探索不同時間點之間的動態依賴性。例如,交通事故等突發事件可能導致交通速度和流量急劇變化。
為了應對這種情況,採用了一種改進的注意力機制,與週期性交通模式編碼類似。
其區別在於,查詢(Q)、鍵(K)和值(V)的輸入被改為上一步的歸一化輸出(M)。此調整幫助模型專注於學習不同時間點之間的動態依賴關係,而非僅限於週期性模式。
由此產生的時間表示

能夠有效捕捉這些動態的時空聯繫。
空間依賴建模
由於在交通預測中,交通網絡展現出顯著的空間相關性,捕獲空間依賴性對模型設計至關重要。一個區域的交通狀態通常會受到其鄰近區域狀態的影響。為了有效學習這種空間聯繫,採用了圖卷積網絡(GCNs):

是歸一化的鄰接矩陣,𝛼用於平衡原始信息的保留程度。殘差連接、RMSNorm(RN)和SwiGLU激活函數被用於後續的運算。

式中,


是可訓練權重。通過疊加多層時空編碼網絡,OpenCity具備捕獲複雜的時空依賴性的能力,從而使其能夠學習交通網絡內的複雜相互作用。
代表第l層時空編碼網絡的最終輸出,σ是Swish激活函數,
實驗
零樣本 vs. 全樣本
全面評估了OpenCity在零樣本條件下的性能,測試涉及跨區域、跨城市和跨類型三個維度,並將其與基線模型在全樣本條件下的性能進行了對比,結果如表1所示。
(1)優越的零樣本預測性能。
OpenCity在零樣本條件下取得了突出成就,能夠在無需額外微調的情況下超越多數基線模型。這突顯了模型在掌握複雜的大規模交通數據時空模式、提取適用於多種任務的通用知識的可靠性與效率。
在多個數據集的測試結果下,OpenCity常常位於前兩名,即便不是最佳,其與最優性能(MAE)的差距也控制在8%之內。
這種卓越的零樣本預測能力展現了OpenCity在處理多樣化交通數據集時的廣泛適應性和普遍性,無需大規模的重新訓練。
其核心優勢在於能迅速適應新環境,大幅降低了傳統監督學習方法所需的時間和資源,為實際應用帶來了明顯的優勢。
(2)卓越的跨任務泛化能力。
對OpenCity進行了跨四個不同交通數據類別的評估,包括交通流量(CAD3、CAD5)、交通速度(PEMS07M、TrafficSH)、出租車需求(CHI-TAXI)和單車軌跡(NYC-BIKE)。基線分析顯示,雖然多種模型在特定類型數據上表現出色,但沒有一個能夠在所有類別中一直維持最優結果。
相比之下,OpenCity在所有測試類別中均呈現出高質量的成果,展示了其卓越的穩定性和多功能性。此外,為了評估OpenCity框架的通用性,特別測試了其在跨類別零樣本泛化能力上的表現(以NYC-BIKE為例)。
結果表明,OpenCity在多個評價指標上均展現了出色的成績,進一步驗證了其對多樣數據類型的適應性和普適性。
(3)優越的長期預測性能。
OpenCity架構在長期交通預測任務中的表現優於基線方法,這是其顯著的優勢之一。許多現有模型在預測時間範圍延長時常常難以維持準確性,原因在於這些模型可能過度依賴歷史數據,未能有效捕捉交通狀況的動態變化和演進。
相反,OpenCity能夠從廣泛的交通數據源中學習到關鍵的時空特徵,使其能夠提供穩定而可靠的預測,即便在交通模式隨時間發生變化的情況下也是如此。
 表1 零樣本 vs. 全樣本性能
表1 零樣本 vs. 全樣本性能有監督預測性能
為了進一步驗證OpenCity的性能,進行了監督學習評估。在這一評估中OpenCity採用一體化配置,在單個數據集上與基線模型進行了全面的端到端訓練和測試比較。
表2中的結果顯示,OpenCity在監督學習環境中展示了出色的性能,並在大多數評估指標上保持了領先地位。此外,觀察到大多數基線模型在CAD-X數據集上的表現欠佳,這可能是由於它們傾向於過度擬合歷史的時空模式,難以適應長期依賴的交通模型。
相反,OpenCity架構通過有效地從預訓練階段提取通用的週期性和動態時空特徵,成功克服了由時間和地點的分佈偏移引起的預測性能降低問題。
 表2 有監督任務評估
表2 有監督任務評估模型快速適應能力探索
本節中探討了OpenCity在下遊任務中的快速適應能力。對預訓練階段未出現的交通數據類型實施了「高效微調」策略。具體做法是僅更新模型的預測頭部(最後一個線性層),並限制訓練週期為至多三個。
如表3所示,雖然OpenCity在一些指標上的零樣本性能最初不如基線模型的全樣本性能,這可能歸因於交通模式和數據采樣的差異。然而,通過高效微調,OpenCity的性能顯著提升,超越了所有比較模型。
特別值得注意的是,OpenCity的訓練時間僅需基線模型的2%至32%。這種快速的適應性突顯了OpenCity作為基本交通預測模型的潛力,展示了其對新的時空數據類型的迅速適應能力。
 表3 OpenCity快速適應能力評估
表3 OpenCity快速適應能力評估消融實驗
(1)動態交通建模的重要性。
-DTP。除動態交通建模模塊後,性能有所下降。這說明該模塊對於有效分析最新交通模式並適應突發的交通狀況以優化預測至關重要。
(2)週期性交通轉移建模的作用。
-P湯臣M。在模型中取消了週期性編碼,選擇直接將時間和空間上下文融入時空嵌入。性能的下降表明,通過映射歷史與未來時間對之間的交通流,OpenCity 能夠有效捕獲影響時空模式演變的關鍵規律。
(3)空間依賴性建模的作用。
在-SDM變體中,移除了空間編碼模塊。分析顯示,通過學習空間關係,模型的時空預測能力得到了顯著提升。模型通過整合依賴於空間區域的交通信息,有效地識別了動態交通流模式,為零樣本交通預測提供了關鍵支持。
(4)時空上下文編碼的作用。
在移除了時空上下文信息編碼後(-STC),性能顯著下降。時間上下文信息幫助模型識別並學習特定時段的常見交通模式,同時區域嵌入則提供了區域特定的關鍵特徵。這些因素共同為理解城市間的動態時空模式提供了深刻的洞察。
 圖3 OpenCity消融實驗
圖3 OpenCity消融實驗模型可擴展性研究
如圖4所示,本節探索了OpenCity在數據量和參數規模這兩個維度的可擴展性。
對於參數規模,考察了三個不同的版本:OpenCity-mini(2M參數)、OpenCity-base(5M參數)以及OpenCity-plus(26M參數)。在數據規模的可擴展性方面,對於OpenCity-plus模型,分別使用了10%、50%和100%的預訓練數據,以研究增加數據量所帶來的優勢。
為了便於比較,使用相對預測誤差作為縱軸的度量標準。結果顯示,隨著參數數量和數據量的增加,OpenCity的零樣本泛化能力也逐漸提升。
這表明OpenCity能夠有效地從大規模數據集中提取有用信息,並通過增加參數規模來提高其學習能力。這種可擴展性的展示支持了OpenCity成為廣泛應用於交通領域的基礎模型的潛力。
 圖4 模型可擴展性研究
圖4 模型可擴展性研究與大規模時空預測模型的比較
在本節中,對OpenCity與其他先進的大型時空預訓練模型進行了比較,包括以其出色的零樣本泛化能力而著稱的UniST和UrbanGPT。評估使用的是三個模型在預訓練階段均未接觸過的CHI-TAXI數據集。
如表4所示,OpenCity在這些先進的大型時空模型中顯示出了顯著的性能優勢。此外,與UrbanGPT相比,OpenCity和UniST表現出了明顯的效率提升。這可能是因為UrbanGPT需要依賴於大型語言模型(LLM)以問答格式進行預測,從而限制了其處理批量數據的效率。
OpenCity在性能和效率方面的卓越表現突顯了其在交通領域作為強大大規模模型的潛力。
 表4 與大規模時空預測模型的比較實驗。
表4 與大規模時空預測模型的比較實驗。總結與展望
該論文提出了OpenCity,一個針對交通預測設計的可擴展時空基礎模型,它在多種交通預測場景中展示了卓越的零樣本預測能力。
該模型核心採用了Transformer編碼器架構,用以建模動態的時空依賴性,並通過在大型交通數據集上預訓練,使得OpenCity在多種下遊任務中均表現出色,其零樣本預測性能可與全樣本設置下的先進模型媲美。
OpenCity框架能夠有效處理不同分佈的數據,並展現出高效的計算性能。鑒於其所顯示的良好擴展性,OpenCity為開發一個強大且適用於多種城市環境和交通網絡的通用交通預測解決方案奠定了基礎。
參考資料:
http://arxiv.org/abs/2408.10269
https://sites.google.com/view/chaoh


















