OpenAI o1 全方位 SOTA 登頂 lmsys 排行榜:數學能力碾壓 Claude 和Google Gemini 模型,o1-mini 並列第一
o1 模型發佈 1 周,lmsys 的 6k + 投票就將 o1-preview 送上了排行榜榜首。同時,為了滿足大家對模型「IOI 金牌水平」的好奇心,OpenAI 放出了 o1 測評時提交的所有代碼。

萬眾矚目的最新模型 OpenAI o1,終於迎來了 lmsys 競技場的測評結果。不出意外,o1-preview 在各種領域絕對登頂,超過了最新版的 GPT-4o,在數學、困難提示和編碼領域表現出色;
而 o1-mini 雖然名字中自帶「mini」,但也和最新版的 GPT-4o 並列綜合排名第二,困難提示、編碼、數學等領域和 o1-preview 同樣登頂第一。

果然,o1 模型不愧是通用推理領域的新王。lmsys 社區官方發推表示,這項測試結果收集了 6k + 社區投票,並將 OpenAI 這次取得的進展描述為「令人難以置信的里程碑」。

單純看排行榜的排名可能不夠具有說服力,於是 lmsys 特意統計了總榜上前 25 名模型的 1v1 勝率。
可以看到,o1-preview 對所有模型的勝率都超過了 50%,對比 04-09 版 GPT-4-Turbo 的勝率最高,達到了 88%。
o1-mini 如果對戰 o1-preview,勝率為 46%,對 09-03 版 GPT-4o 的勝率為 48%,可以說是大體平手、稍遜一籌的狀態。
值得注意的是,雖然 Grok-2-mini 和 Claude 3.5 Sonnet 都排在比較靠後的位置,但 o1-preview 對這兩個模型的勝率並不高,分別是 58% 和 57%,大大小於排名第四的 Gemini 1.5 Pro 的 69%。

如果看到細分領域的排行榜,尤其是數學 / 推理領域,效果則更加驚豔。o1-preview 和 o1-mini 不僅是登頂數學排行榜,而且是體現出了絕對的領先優勢。
排在第三、第四的 Claude 3.5 Sonnet、Gemini 1.5 Pro 和 08-08 版 ChatGPT-4o 的均分都在 1275 左右,不相上下;o1-preview 和 o1-mini 則一騎絕塵,分數飆到 1360 附近,直接碾壓。

o1 推理團隊的領導者之一 William Fedus 看到這張圖也是相當開心,他表示這張圖「很好地用視覺表達了範式轉換」。

看來最新的 o1 模型在 STEM 學科和通用推理方面的確又達到了新高度,用實際測評結果回應了「AI 遇冷」、「OpenAI 碰壁」的質疑聲。

「那就繼續期待 OpenAI 接下來的發佈吧!」

但一些人感歎「未來可期」的同時,另一些人想到了自己不多的智商和頭髮。

「模型搞得這麼好了,測試就不適合我這種蠢人了。」

同時,也有一些人表達了對 lmsys 排行榜結果的質疑。
比如,眾所周知的 o1 模型推理時間長,因而回答的延時也長,和其他模型都有明顯差別;而且不同於各類基準測試的客觀標準,lmsys 社區中完全基於用戶的主觀評分,難說這裡面是否存在「安慰劑效應」。

也有人不服 o1 在編碼排行榜上的第一,認為雖然 o1-mini 非常適合進行項目規劃,但在 Cursor 這類編碼助手中還是 Claude 模型的表現最佳。

排行榜的結果當然不是全部,o1 模型能否繼續贏得口碑,同時保持住智力水平不變蠢,還要看接下來的一段時間。
IOI 金牌代碼全公開
說到 o1 模型的編碼能力,不知道你還是否記得,剛發佈時 OpenAI 提到了這樣一個指標:如果放寬提交約束到每個問題允許 1 萬次提交,o1 可以達到高於 IOI 金牌門檻的分數。
在模擬進行的 Codeforces 編程競賽中,使用相同的規則進行評估,o1-preview 可以打敗 62% 的人類選手,正式版 o1 則上升到超越 89% 的對手。
專門微調過的 o1-ioi 模型,表現優於 93% 的競爭對手。
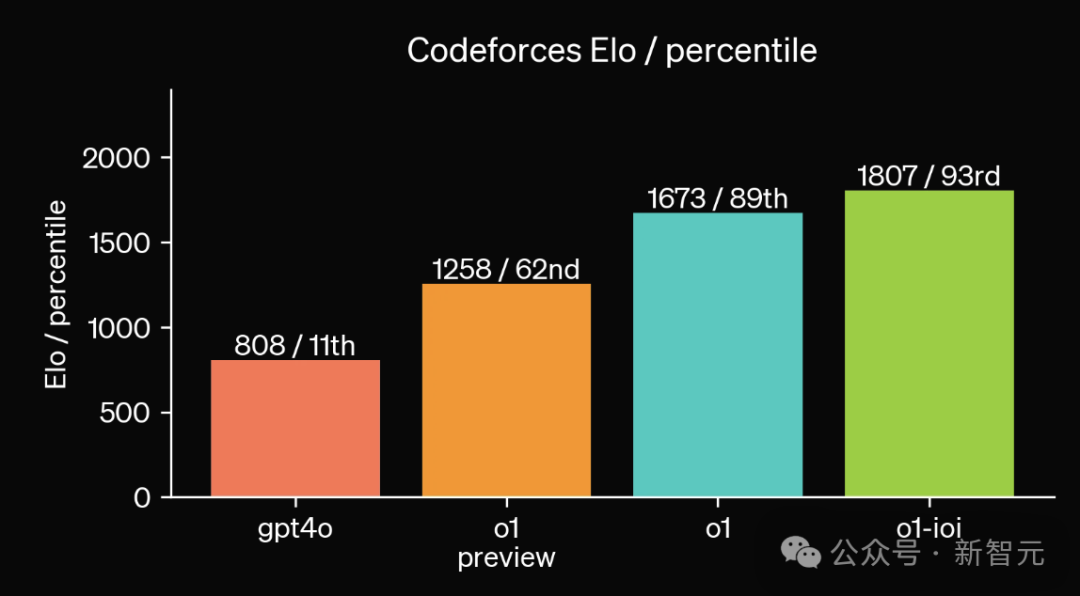
此外,前段時間有用戶在實時的 Codeforces 比賽中使用了 o1 模型,結果是超越了 99.8% 的人類選手。
由於 o1 在編程競賽領域的表現如此突出,引起了 AI 社區強烈的興趣和好奇,OpenAI 於是選擇發佈 o1 模型提交的代碼內容,包括 6 個問題的全部 C++ 代碼以及註釋。
 發文的 yummy 是 o1 模型的核心貢獻者 Alexander Wei
發文的 yummy 是 o1 模型的核心貢獻者 Alexander Wei對於 o1 的驚豔表現,Alexander Wei 自己都很驚訝。
他本人在 9 年前曾參加 IOI 競賽,但從未想到自己這麼快就需要和 AI 競爭,模型展現出的推理過程的複雜程度令人印象深刻。

博文表示,雖然 o1 模型距離人類的頂級表現還有很長的一段路要走,但我們期待有一天能實現這個目標。
這個發展軌跡讓人想起了 AlphaGo—— 從水平高超,到能和人類頂級高手不分勝負,再到 5-0 完全碾壓李世石。
OpenAI 想要達成的,估計就是究極進化的、能在編程上碾壓人類頂級高手的 AlphaZero。
此處公佈代碼的 6 個問題具體如下:

有網民指出,其中最令人印象深刻的應該是象形文字(hieroglyphs)問題,o1 模型總共得到 44 分,在現場的所有選手中排名第四。這表明,模型或許可以破譯一些人類無法解決的子任務。
前幾天,一位目前在 NASA 工作的天體物理學博士就嘗試讓 o1 複現自己論文中的代碼,結果一試嚇一跳 —— 自己讀博時花了 1 年寫出的代碼,o1 只用了一小時就寫完了。

這還只是裸模型,如果加上代碼解釋器、網絡實時搜索等各種工具,效果想必更加驚豔。

而且,Reddit 網民還送來了溫馨提示:這隻是 o1 預覽版哦,可以狠狠期待一下不到一個月就即將問世的正式版 o1 了。

此外,這位網民還表示,o1 基本沿用了 GPT-4 的架構;那你想,改換架構後的 GPT-5(也就是傳說中的獵戶座)能達到什麼高度。
參考資料:
-
https://x.com/lmsysorg/status/1836443278033719631
-
https://codeforces.com/blog/entry/134091
廣告聲明:文內含有的對外跳轉鏈接(包括不限於超鏈接、二維碼、口令等形式),用於傳遞更多信息,節省甄選時間,結果僅供參考,IT之家所有文章均包含本聲明。



















