o1核心作者MIT演講:激勵AI自我學習,比試圖教會AI每一項任務更重要
一水 發自 凹非寺
量子位 | 公眾號 QbitAI
「o1發佈後,一個新的範式產生了」。
其中關鍵,OpenAI研究科學家、o1核心貢獻者Hyung Won Chung,剛剛就此分享了他在MIT的一次演講。
演講主題為「Don’t teach. Incentivize(不要教,要激勵),核心觀點是:
激勵AI自我學習比試圖教會AI每一項具體任務更重要

思維鏈作者Jason Wei迅速趕來打call:
Hyung Won識別新範式並完全放棄任何沉沒成本的能力給我留下了深刻的印象。
2022年底,他意識到了強化學習的力量,並從那時起就一直在宣揚它。

在演講中,Hyung Won還分享了:
-
技術人員過於關注問題解決本身,但更重要的是發現重大問題;
-
硬件進步呈指數級增長,軟件和算法需要跟上;
-
當前存在一個誤區,即人們正在試圖讓AI學會像人類一樣思考;
-
「僅僅擴展規模」 往往在長期內更有效;
-
……
下面奉上演講主要內容。
對待AI:授人以魚不如授人以漁
先簡單介紹下Hyung Won Chung,從公佈的o1背後人員名單來看,他屬於推理研究的基礎貢獻者。

資料顯示,他是MIT博士(方向為可再生能源和能源系統),去年2月加入OpenAI擔任研究科學家。
加入OpenAI之前,他在Google Brain負責大語言模型的預訓練、指令微調、推理、多語言、訓練基礎設施等。

在Google工作期間,曾以一作身份,發表了關於模型微調的論文。(思維鏈作者Jason Wei同為一作)

回到正題。在MIT的演講中,他首先提到:
通往AGI唯一可行的方法是激勵模型,使通用技能出現。
在他看來,AI領域正處於一次範式轉變,即從傳統的直接教授技能轉向激勵模型自我學習和發展通用技能。
理由也很直觀,AGI所包含的技能太多了,無法一一學習。(主打以不變應萬變)

具體咋激勵呢??
他以下一個token預測為例,說明了這種弱激勵結構如何通過大規模多任務學習,鼓勵模型學習解決數萬億個任務的通用技能,而不是單獨解決每個任務。
他觀察到:
如果嘗試以儘可能少的努力解決數十個任務,那麼單獨模式識別每個任務可能是最簡單的;如果嘗試解決數萬億個任務,通過學習通用技能(例如語言、推理等)可能會更容易解決它們。

對此他打了個比方,「授人以魚不如授人以漁」,用一種基於激勵的方法來解決任務。
Teach him the taste of fish and make him hungry.(教AI嚐嚐魚的味道,讓他餓一下)
然後AI就會自己出去釣魚,在此過程中,AI將學習其他技能,例如耐性、學習閱讀天氣、瞭解魚等。
其中一些技能是通用的,可以應用於其他任務。
面對這一「循循善誘」的過程,也許有人認為還不如直接教來得快。
但在Hyung Won看來:
對於人類來說確實如此,但是對於機器來說,我們可以提供更多的計算來縮短時間。

換句話說,面對有限的時間,人類也許還要在專家 or 通才之間做選擇,但對於機器來說,算力就能出奇蹟。
他又舉例說明,《龍珠》里有一個設定:在特殊訓練場所,角色能在外界感覺只是一天的時間內獲得一年的修煉效果。
對於機器來說,這個感知差值要高得多。
因此,具有更多計算能力的強大通才通常比專家更擅長特殊領域。
原因也眾所周知,大型通用模型能夠通過大規模的訓練和學習,快速適應和掌握新的任務和領域,而不需要從頭開始訓練。

他還補充道,數據顯示計算能力大約每5年提高10倍。

總結下來,Hyung Won認為核心在於:
-
模型的可擴展性
-
算力對加速模型進化至關重要
此外,他還認為當前存在一個誤區,即人們正在試圖讓AI學會像人類一樣思考。
但問題是,我們並不知道自己在神經元層面是如何思考的。
機器應該有更多的自主性來選擇如何學習,而不是被限制在人類理解的數學語言和結構中。
在他看來,一個系統或算法過於依賴人為設定的規則和結構,那麼它可能難以適應新的、未預見的情況或數據。
造成的結果就是,面對更大規模或更複雜的問題時,其擴展能力將會受限。

回顧AI過去70年的發展,他總結道:
AI的進步與減少人為結構、增加數據和計算能力息息相關。
與此同時,面對當前人們對scaling Law的質疑,即認為僅僅擴大計算規模可能被認為不夠科學或有趣。
Hyung Won的看法是:
在擴展一個系統或模型的過程中,我們需要找出那些阻礙擴展的假設或限制條件。
舉個例子,在機器學習中,一個模型可能在小數據集上表現良好,但是當數據量增延長,模型的性能可能會下降,或者訓練時間會變得不可接受。
這時,可能需要改進算法,優化數據處理流程,或者改變模型結構,以適應更大的數據量和更複雜的任務。
也就是說,一旦識別出瓶頸,就需要通過創新和改進來替換這些假設,以便模型或系統能夠在更大的規模上有效運行。
訓練VS推理:效果相似,推理成本卻便宜1000億倍
除了上述,o1另一核心作者Noam Brown也分享了一個觀點:
訓練和推理對模型性能提升作用相似,但後者成本更低,便宜1000億倍。
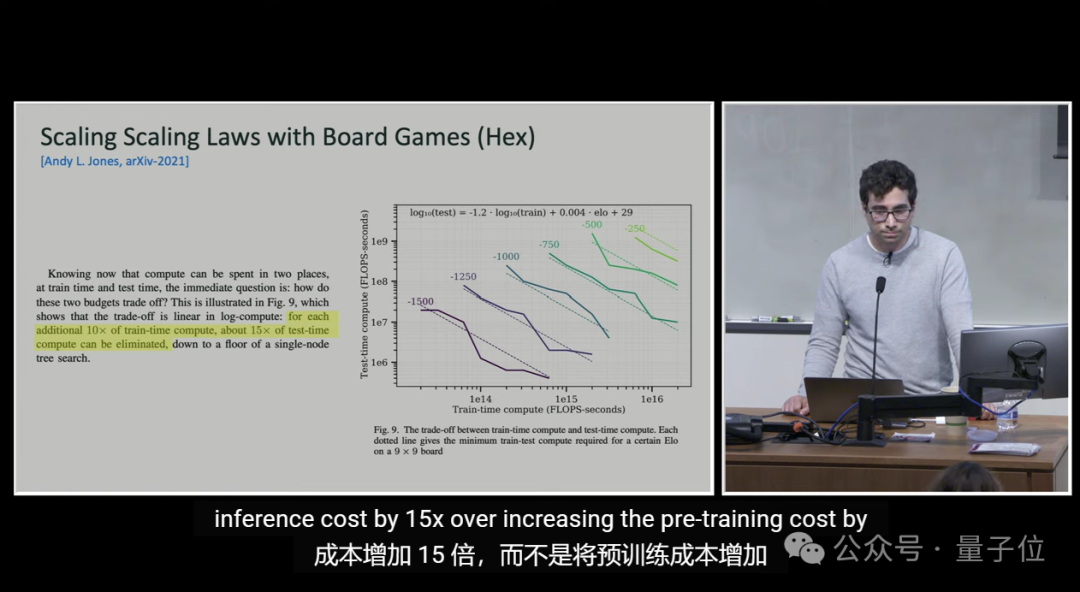
這意味著,在模型開發過程中,訓練階段的資源消耗非常巨大,而實際使用模型進行推理時的成本則相對較低。
有人認為這凸顯了未來模型優化的潛力。

不過也有人對此持懷疑態度,認為二者壓根沒法拿來對比。
這是一個奇怪的比較。一個是邊際成本,另一個是固定成本。這就像說實體店比其中出售的商品貴500000倍

對此,你怎麼看?
Hyung Won Chung演講PPT:
https://docs.google.com/presentation/d/1nnjXIuN2XDJENAOaKXI5srQscO3276svvP6JgivTv6w/edit#slide=id.g2d1161c9c52_0_20
參考鏈接:
[1]https://x.com/hwchung27/status/1836842717302943774
[2]https://x.com/tsarnick/status/1836215965912289306